目前為止已經學完了所有Data Preprocessing 會用到的技能
讓我們來複習一下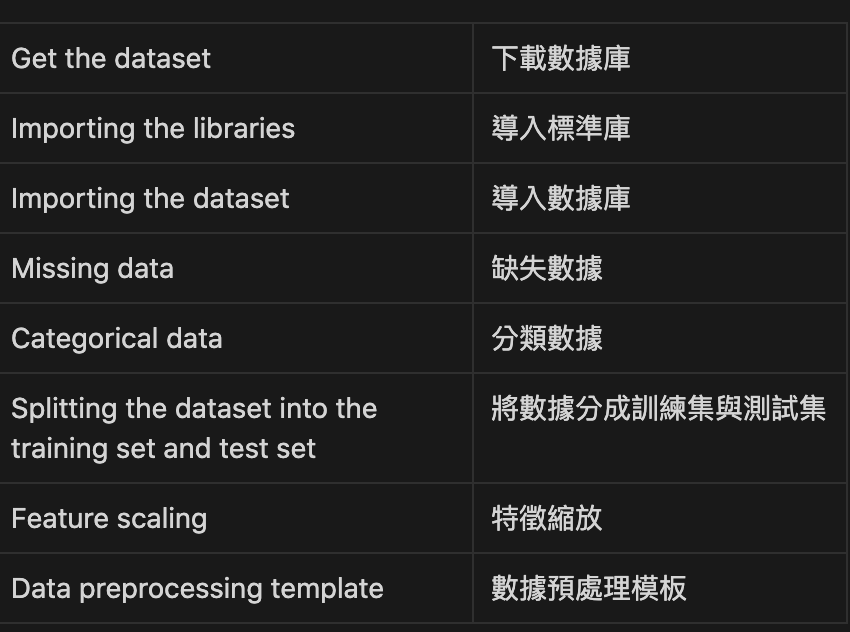
前三項比較像是基本python 的語法
第四項開始講如何處理缺失的數據, 可以用平均數, 最大值, 最小值都可以
第五項講分類數據, 因為有些數據是string 不是數字, 因此可以將某些數據透過python library 轉化為數字 或是 二元數字串(ex: 001, 010, 100), 轉換成數字後才可以導入模型來計算
第六項講訓練集和測試集, 訓練集可以讓機器利用model 學習資料間的關係, 測試集則是讓機器考試, 看看訓練玩的模型準不準確
第七項特徵縮放是讓資料彼此的權重不要差太大, 有點像是當國文的權重佔5, 英文的權重佔1, 這樣就差太多, 透過python libarary 可以讓彼此權重都是1 或是接近, 讓計算上彼此的影響力相當
第八項就是本頁要做的了, 將上述的七項所有程式碼列出變成樣板, 後面的學習可以依此樣板來實作
# -*- coding: utf-8 -*-
"""
Editor: Ironcat45
Title: For data processing practice
Date: 2022/09/21
"""
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
"""
1. Get and import the dataset
Use read_csv() and iloc() to get and import the dataset
Read the data[:][0-2] as array x
Read the data[:][3] as array y
"""
dataset = pd.read_csv('Data.csv')
x = dataset.iloc[:, :-1].values
y = dataset.iloc[:, 3].values
"""
2. Deal with the missing data
Use SimpleImputer to impute the missing data
by calling fit() and transform()
"""
#from sklearn.preprocessing import Imputer
from sklearn.impute import SimpleImputer
imputer = SimpleImputer(missing_values=np.nan, strategy='mean')
# only deal with index 1, 2 (not includes 3)
imputer = imputer.fit(x[:,1:3])
x[:, 1:3] = imputer.transform(x[:, 1:3])
"""
3.1 Deal with the categorical data
Use LabelEncoder to transfer the data
(transfer from string to digit)
"""
# transfer label to digit
from sklearn.preprocessing import LabelEncoder
lblenc_x = LabelEncoder()
# init the label encoder and transfer it
# get all the rows with the colmun 0
x[:,0] = lblenc_x.fit_transform(x[:,0])
lblenc_y = LabelEncoder()
y = lblenc_y.fit_transform(y)
"""
3.2. Deal with the categorical data <dummy encoding>
Use the OneHotEncoder and ColumnTransformer to encode
a colmun of data
"""
from sklearn.preprocessing import OneHotEncoder
from sklearn.compose import ColumnTransformer
ct = ColumnTransformer([("Country", OneHotEncoder(), [0])], remainder = 'passthrough')
x = ct.fit_transform(x)
"""
4. Split the dataset
"""
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x,y,test_size=0.2, random_state=0)
"""
5. Feature scaling
"""
from sklearn.preprocessing import StandardScaler
sc_x = StandardScaler()
x_train = sc_x.fit_transform(x_train)
x_test = sc_x.transform(x_test)
模板中我們只保留了1, 4
後面的學習可能只會用到這些
不過2,3,4,5 的應用還是要依實際情況而定
老師針對這部份沒有說明太清楚
之後再查資料補充
# -*- coding: utf-8 -*-
"""
Editor: Ironcat45
Title: For data processing practice
Date: 2022/09/21
"""
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
"""
1. Get and import the dataset
Use read_csv() and iloc() to get and import the dataset
Read the data[:][0-2] as array x
Read the data[:][3] as array y
"""
dataset = pd.read_csv('Data.csv')
x = dataset.iloc[:, :-1].values
y = dataset.iloc[:, 3].values
"""
4. Split the dataset
"""
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x,y,test_size=0.2, random_state=0)


 iThome鐵人賽
iThome鐵人賽