前面幾天陸陸續續介紹了不同的機器學習模型,但是我們都沒有將不同的模型進行比較和評估,今明兩天要來講講如何選擇、評估模型,以及如何分割資料進行建模。
當我們建立完許多同的模型後通常會有兩個目標:
The process of selecting the proper level of flexibility for a model.
估計不同模型的表現( performance )以選擇最佳模型。
Evaluating a model’s performance.
選擇了表現最好的最終模型後,去看其對新數據( testing data )的預測誤差(prediction error, generalization error)。
一般來說建了機器學習模型後要進行模型選擇、參數調校時,離不開驗證 ( Validation)的介紹。這是因為機器學習的模型在訓練資料充足時,提高模型複雜度能輕易地讓準確率上升,但也會伴隨著非常普遍的問題: 過度擬合 Overfitting,這時候我們需要驗證集來檢測避免模型配適發生過度擬合的問題。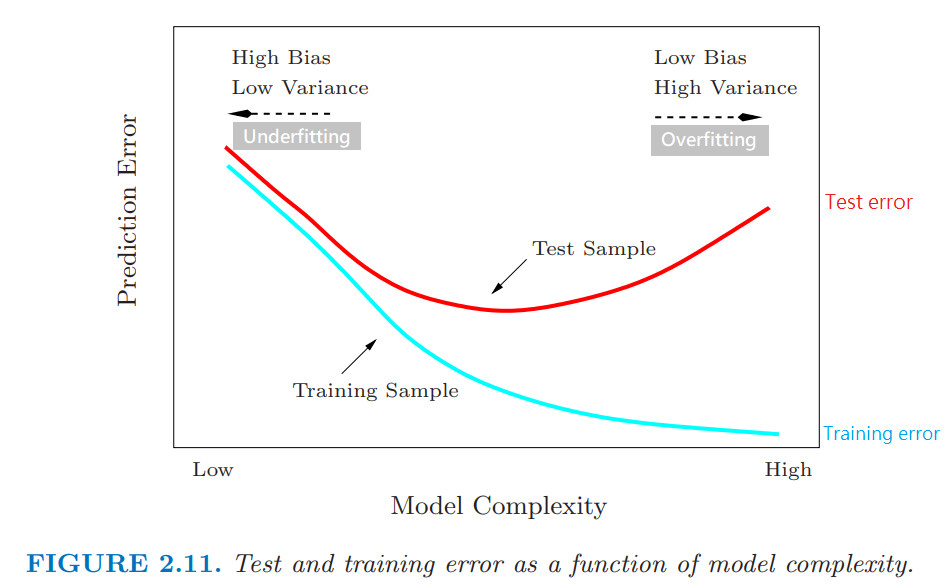
The Elements of Statistical Learning. FIGURE 2.11. Model Complexity
除此之外,接下來預計要介紹的模型包括: 支持向量機 SVM、決策樹 Decision Tree、隨機森林 Random Forest、集成學習 Ensemble Learning ,這些模型都少不了模型超參數(Hyperparameter)的選擇,這時候就可以使用到驗證集來協助挑選參數(Tunning parameter)。
首先讓我們看看資料集的長相:
在資料量充足下,典型的切分法是 50% training 訓練集, 25% validation 驗證集, 25% testing 測試集。
但實例上的資料量往往不足,難以去界定資料集切分成訓練、驗證、測試集的比例。當資料量不足時可能會使用近似驗證的方式驗證協助進行模型選擇,近似驗證的方式包括計算出模型選擇準則或是更有效利用資料。
模型選擇準則
通常是以最樂觀的方式去估計訓練模型的預測誤差(estimate the optimism),例如:
有效利用資料
有效利用資料的方式就是在「不能使用到測試集」的情況下,對剩下的資料進行抽樣,部分作為訓練資料集,剩下的作為驗證集,相當於去計算 Extra-sample error。方法例如:
今天先介紹什麼是驗證集Validation set 和它的用處,
明天要來講講什麼是「Cross-validation 交叉驗證」以及程式碼的示範。
統計與機器學習 Statistical and Machine Learning, 台大課程. 王彥雯 老師.
An Introduction to Statistical Learning with Applications in R. 2nd edition. Springer. James, G., Witten, D., Hastie, T., and Tibshirani, R. (2021).
The Elements of Statistical Learning: Data Mining, Inference, and Prediction. 2nd edition. Springer. Hastie, T., Tibshirani, R. and Friedman, J. (2016).

