前天有提到 Stacking (堆疊法),這種集成學習方法主要是被用來提高模型的預測/分類準確率。
今天就來提供一下相關的 R 範例,並在最後補充一個推薦的 Python Ensemble Learning 示範網站。
在 R 裡使用caretEnsemble套件中,可以建立很多不同種的集成學習模型,其中caretStack( )函式,可以去建立 Stacking 的模型。
## Adapted from the caret vignette
library(caret)
library("caTools")
library("rpart")
#install.packages("caretEnsemble")
library("caretEnsemble")
這裡使用資料集 Sonar,用來區分聲納信號,共208筆資料,60個解釋變數,目標變數 Class 為二元分類,分類為"R"岩石或是"M"金屬。資料集詳情。
library("mlbench") #dataset
data(Sonar) #sonar data
set.seed(123)
inTrain <- createDataPartition(y = Sonar$Class, p = .75, list = FALSE)
training <- Sonar[ inTrain,]
testing <- Sonar[-inTrain,]
在 caretList 裡設定 methodList = 去設置子集合模型。
my_control <- trainControl(
method="boot",
number=25,
savePredictions="final",
classProbs=TRUE,
index=createResample(training$Class, 25),
summaryFunction=twoClassSummary
)
model_list <- caretList(
Class~., data=training,
trControl=my_control,
methodList=c("glm", "rpart")
)
##使用 glm 作為meta classifier,建立集成學習模型
glm_ensemble <- caretStack(
model_list,
method="glm",
metric="ROC",
trControl=trainControl(
method="boot",
number=10,
savePredictions="final",
classProbs=TRUE,
summaryFunction=twoClassSummary
)
)
model_preds <- lapply(model_list, predict, newdata=testing, type="prob")
model_preds <- lapply(model_preds, function(x) x[,"M"])
model_preds <- data.frame(model_preds)
ens_preds <- predict(glm_ensemble, newdata=testing, type="prob")
model_preds$ensemble <- ens_preds
caTools::colAUC(model_preds, testing$Class)
各別模型比較:
> caTools::colAUC(model_preds, testing$Class)
glm rpart ensemble
M vs. R 0.7546296 0.787037 0.8371914
想進一步了解caretEnsemble套件中不同種的集成學習模型,
可以參考A Brief Introduction to caretEnsemble by Zach Mayer,2019。
H2O is an open source, in-memory, distributed, fast, and scalable machine learning and predictive analytics platform that allows you to build machine learning models on big data and provides easy productionalization of those models in an enterprise environment.
H2O 套件也是在 R 上常用進行機器學習、深度學習的工具。這裡官網連結:Welcome to H2O。
這裡推薦一個範例網站,可以提供想用H2O 套件進行堆疊集成學習 Stacked Ensemble Model 參考程式碼。How To Build Stacked Ensemble Models In R by George Pipis, 2020.。
在 Python 裡進行集成學習集成學習時常用到的套件 MLEXTEND。
首先要先去 Anaconda Prompt 安裝套件 MLEXTEND。
pip install mlxtend
以下範例使用 Iris data,並建立羅吉斯迴歸、SVM支援向量機分類、隨機森林三種模型的Stacking堆疊模型,接著再去比較單一模型和堆疊模型(共四種模型)的分類差異:
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.gridspec as gridspec
import itertools
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn.ensemble import RandomForestClassifier
from mlxtend.classifier import EnsembleVoteClassifier
from mlxtend.data import iris_data
from mlxtend.plotting import plot_decision_regions
# Initializing Classifiers
clf1 = LogisticRegression(random_state=0)
clf2 = RandomForestClassifier(random_state=0)
clf3 = SVC(random_state=0, probability=True)
eclf = EnsembleVoteClassifier(clfs=[clf1, clf2, clf3],
weights=[2, 1, 1], voting='soft')
# Loading some example data
X, y = iris_data()
X = X[:,[0, 2]]
# Plotting Decision Regions
gs = gridspec.GridSpec(2, 2)
fig = plt.figure(figsize=(10, 8))
labels = ['Logistic Regression',
'Random Forest',
'RBF kernel SVM',
'Ensemble']
for clf, lab, grd in zip([clf1, clf2, clf3, eclf],
labels,
itertools.product([0, 1],
repeat=2)):
clf.fit(X, y)
ax = plt.subplot(gs[grd[0], grd[1]])
fig = plot_decision_regions(X=X, y=y,
clf=clf, legend=2)
plt.title(lab)
plt.show()
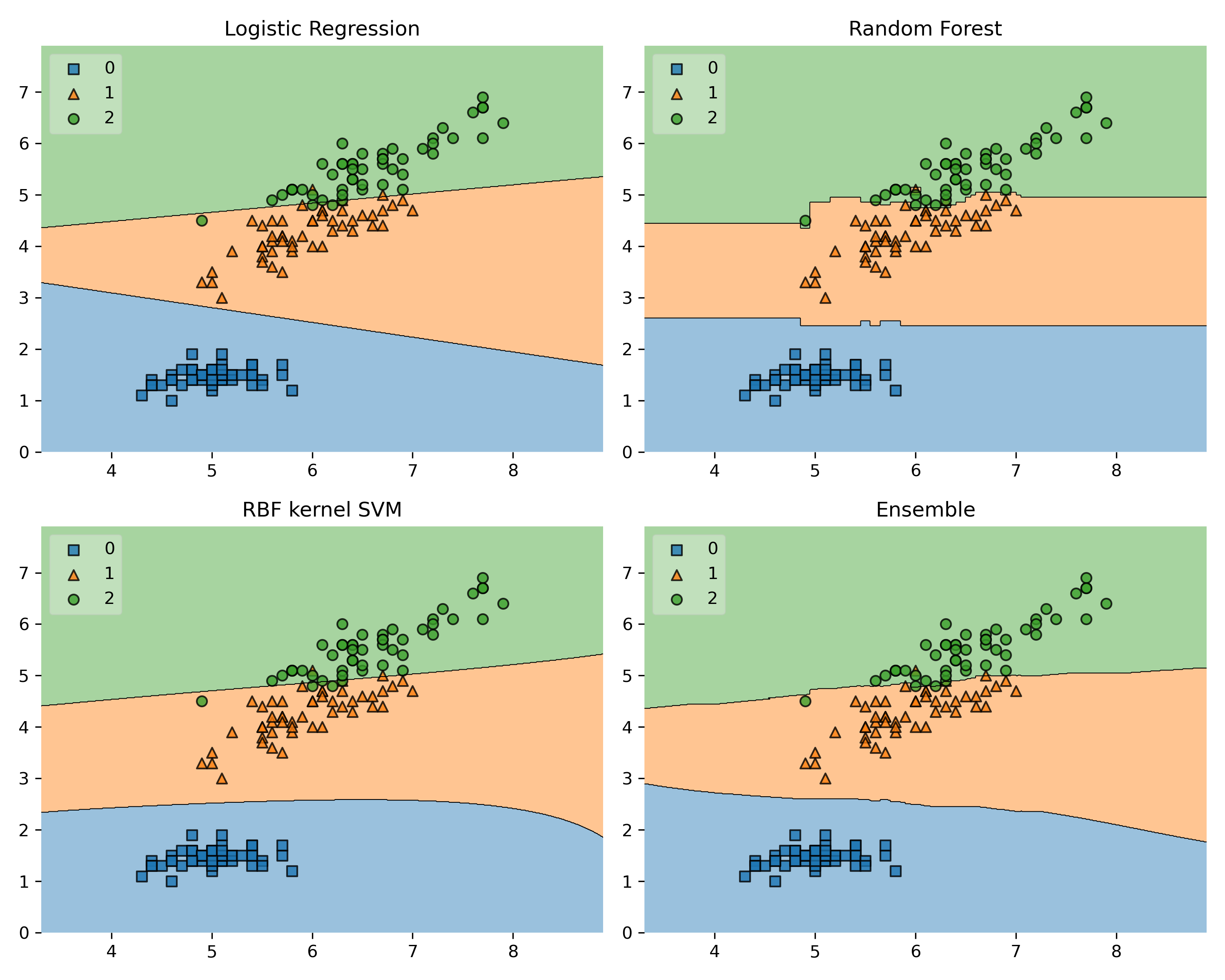
模型預測/分類的結果(準確率)差異:
from sklearn import model_selection # CV
import pandas
from numpy import absolute
from numpy import mean
from numpy import std
labels=["LR","SVC","RF","Stack"]
classifier_array=[clf1, clf2, clf3, eclf]
kfold = model_selection.KFold(n_splits=5)
for clf,l in zip(classifier_array,labels):
cv_scores = model_selection.cross_val_score(clf, X, y, cv=3, n_jobs=-1)
scoring = 'neg_mean_squared_error'
scores_results = model_selection.cross_val_score(clf, X, y, cv=kfold, scoring=scoring)
scores = absolute(scores_results)
acc=1-mean(scores)
# average MAE across the 5-fold cross-validation.;Accuracy
print(l,'\t Mean MAE: %.3f (%.3f)' % (mean(scores), std(scores)),";Accuracy:",acc)
LR Mean MAE: 0.120 (0.122) ; Accuracy: 0.88
SVC Mean MAE: 0.100 (0.060) ; Accuracy: 0.9
RF Mean MAE: 0.160 (0.151) ; Accuracy: 0.84
Stack Mean MAE: 0.093 (0.090) ; Accuracy: 0.90666
[補充]mlxtend是 machine learning extensions 的意思,詳細的套件說明可以參考連結。
這裡推薦以下的網站,作者使用器學習常用到的 SKLEARN 套件和集成學習常用到的套件 MLEXTEND 示範Python程式碼的應用:
Ensemble Learning — Bagging, Boosting, Stacking and Cascading Classifiers in Machine Learning using SKLEARN and MLEXTEND libraries. by Saugata Paul, 2018.
A Brief Introduction to caretEnsemble(@Zach Mayer, 2019)
https://cran.r-project.org/web/packages/caretEnsemble/vignettes/caretEnsemble-intro.html
Ensemble Modeling with R(@Deepika Singh, 2019.)
https://www.pluralsight.com/guides/ensemble-modeling-with-r
How to build Stacked Ensemble Models in R (@George Pipis, 2020.)
https://www.r-bloggers.com/2020/05/how-to-build-stacked-ensemble-models-in-r/
Ensemble Learning — Bagging, Boosting, Stacking and Cascading Classifiers in Machine Learning using SKLEARN and MLEXTEND libraries.(@Saugata Paul)
https://medium.com/@saugata.paul1010/ensemble-learning-bagging-boosting-stacking-and-cascading-classifiers-in-machine-learning-9c66cb271674
Mlxtend (machine learning extensions) is a Python library of useful tools for the day-to-day data science tasks.Examples
https://rasbt.github.io/mlxtend/#examples
MLxtend: Providing machine learning and data science utilities and extensions to Python's scientific computing stack. Sebastian Raschka. The Journal of Open Source Software,2018.
https://joss.theoj.org/papers/10.21105/joss.00638

