我們在 Day 07 曾提到,BigQuery 的基本架構可分為查詢和儲存。因此,本篇要來介紹幾個方法,不僅能夠幫助我們提升查詢的效能、降低費用,甚至還能減少故障。
另外,為了看到查詢時間的差異,我特意使用了比較大的資料: bigquery-public-data.crypto_band.logs,大約有3,0638,5922筆,因此也會有額外的費用。
本篇各位可以閱讀就好,這裡我都已經跑過一遍了 (滿滿的新台幣 orz)。
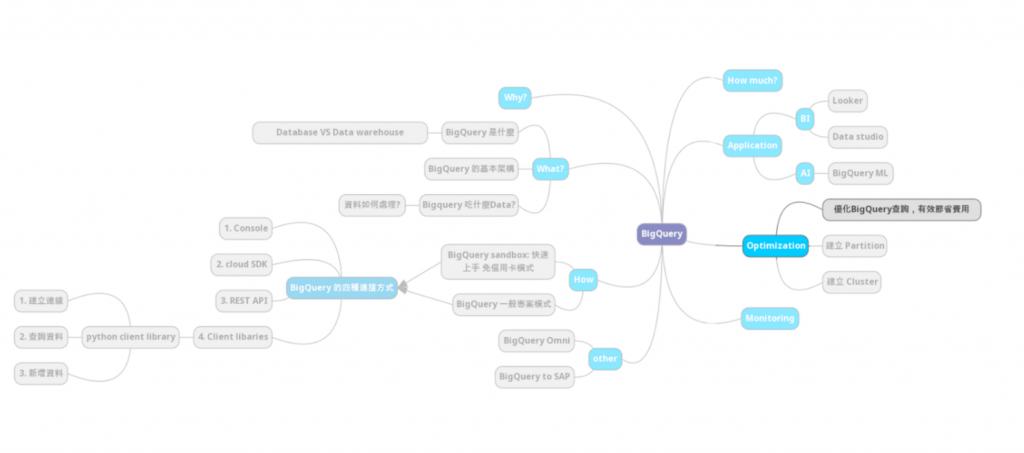
使用 count():
SELECT
txhash,
COUNT(DISTINCT txhash)
FROM
`bigquery-public-data.crypto_band.logs`
GROUP BY 1;
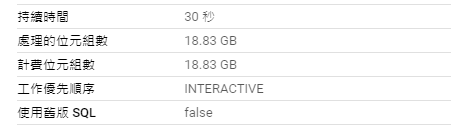
使用 APPROX_COUNT_DISTINCT():
SELECT
txhash,
APPROX_COUNT_DISTINCT(txhash)
FROM
`bigquery-public-data.crypto_band.logs`
GROUP BY 1;
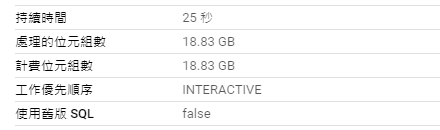
使用 REGEXP_CONTAINS:
SELECT
txhash
FROM
`bigquery-public-data.crypto_band.logs`
WHERE
REGEXP_CONTAINS(txhash, '.*D8.*');
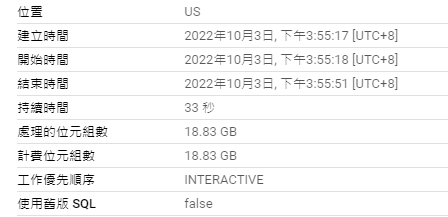
使用LIKE:
SELECT
txhash
FROM
`bigquery-public-data.crypto_band.logs`
WHERE
txhash LIKE '%D8%';
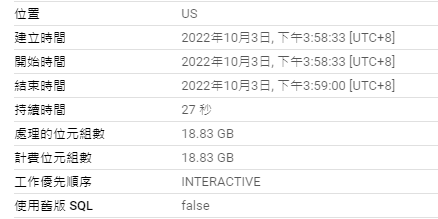
使用 temporary function:
CREATE temp FUNCTION addindex(x INT64, y INT64) AS (x + y);
SELECT log_index, msg_index,addindex(log_index, msg_index) AS result
FROM `bigquery-public-data.crypto_band.logs`;
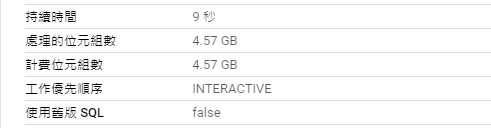
使用 永久性 UDF:
CREATE FUNCTION tv_shows.addindex(x INT64, y INT64) AS (x + y);
SELECT log_index, msg_index, `tv_shows.addindex`(log_index, msg_index) AS result
FROM `bigquery-public-data.crypto_band.logs`;

*註: 使用 UDF還有一個好處,可以儲存在專案的資料集底下,確保大家使用的商業邏輯一致。
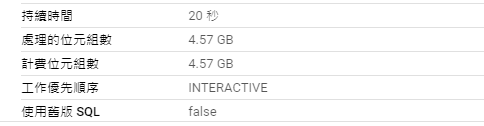
SELECT
block_height,
block_timestamp,
DENSE_RANK() OVER (ORDER BY block_timestamp) AS create_rank
FROM `bigquery-public-data.crypto_band.logs`
ORDER BY create_rank ASC
LIMIT 10;
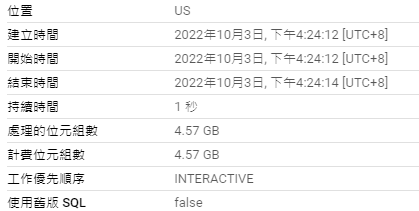
WITH logs AS (
SELECT
block_height,
block_timestamp,
FROM `bigquery-public-data.crypto_band.logs`
ORDER BY block_timestamp ASC
LIMIT 10)
SELECT
block_height,
block_timestamp,
DENSE_RANK() OVER (ORDER BY block_timestamp) AS create_rank
FROM logs
ORDER BY create_rank;
本文介紹和實測了幾個提升查詢效能的方法,有以下幾種:
https://cloud.google.com/bigquery/docs/best-practices-performance-overview?hl=zh-cn

