這篇是 [DAY22] 可以用在手寫數字辨識系統上的機器學習方法整理 的擴寫版,可以先看完 DAY22 簡要大綱再來看這篇~
這邊不提原理(提的話應該可以再講30天XD),僅說說各方法的意義與注意點。
程式碼的部分,這次附上原查到的實作方法推薦,時間關係修改成自己需求的部分就先跳過了(現階段已有CNN最好方法),有機會會在 github 傳用這些方法實作其他專案的案例。
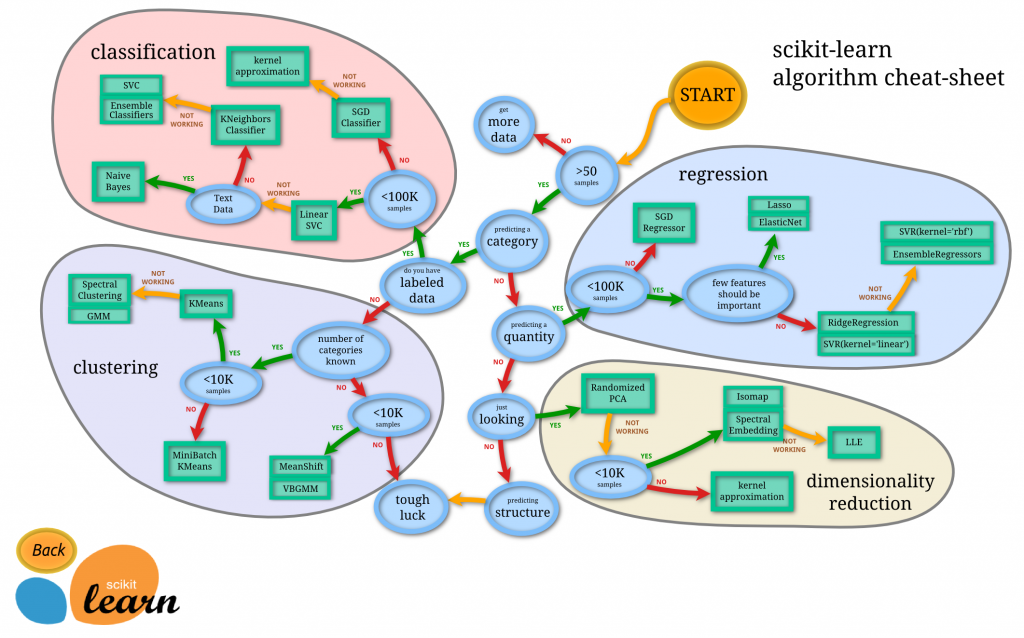
最後想提一下 scikit learn 套件,它提供很多機器學習函式庫,讓我們可以直接引用學習,官網有供的合適套件(estimator)選擇表可以一覽~
那讓我們開始吧!
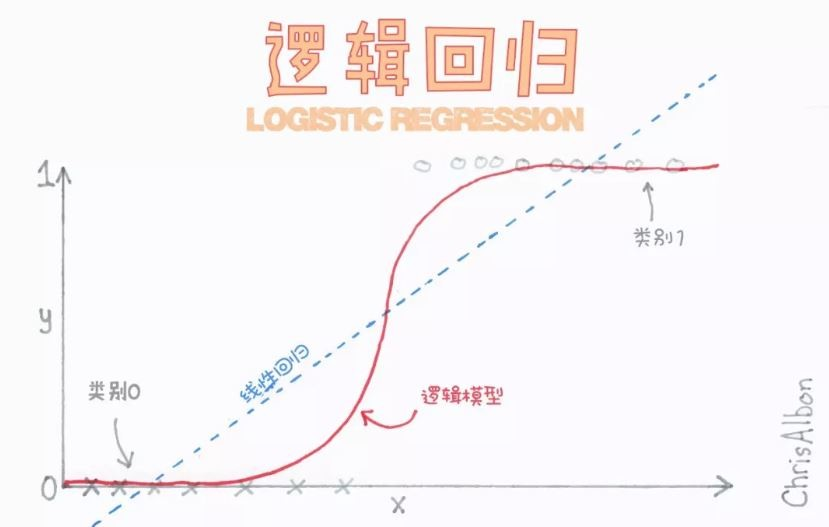
圖片來源:科技橘報
邏輯迴歸適用二分類,但可以做到多分類。
用 logistic regression 做到多分類(multiclass)的過程,可以看林軒田老師在 coursara 上 機器學習基石下 (Machine Learning Foundations)---Algorithmic Foundations 裡的 Multiclass via Logistic Regression(15min),講的很清楚。
官網上就有附使用邏輯迴歸做數字辨識的程式碼。
邏輯迴歸是神經網路的基礎結構。
ps. 二分類時闕值或說臨界值(classification threshold)一般為 0.5,但可以按照你的需求調整
DAY20 有提一部分了,不過我還是在機器學習這邊放了 SVM。
SVM 主要適用二分類,但可以做到多分類。
數字辨識的程式實作:推薦 Kaggle 上 Nishan Patel 所分享的程式碼,非常詳細。
這邊比較重要的是要會分辨 SVM 跟邏輯迴歸的差別(loss)。
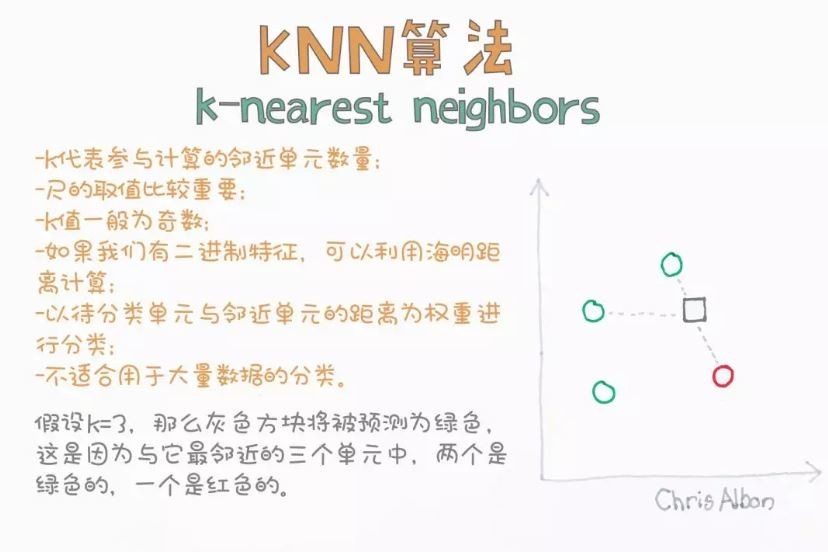
圖片來源:科技橘報
有 NN 但不是 NN(Neural Network)的 K 近鄰演算法,他是根據周圍幾個鄰居的距離(K 個)來決定他要分在哪一類。
人工智慧與數位教育中心解釋的很清楚,簡單好用(有訓練資料但無須訓練),但計算成本高和要小心樣本不均的情形。
數字辨識的程式實作:推薦 STEAM教育學習網的教學,搭配 openCV 實作手寫辨識~
這邊注意幾點:
不推過程,就說一下簡單貝式分類的核心概念 → P(A,B)=P(A)P(B),當A,B兩變數彼此獨立時,它們的聯合機率可以等於它們各自機率的乘積。
以手寫數字圖片輸入大小28*28=784維來說,輸入維度彼此獨立的前提假設不對,雖然還是可以做分類,不過訓練的正確率通常不會太高(因其假設與現實情形不符)。
Kaggle 上 SAHEBI 的五成正確率作法,github 上 Arnab-0901 的八成正確率作法。
ps. 如果你把圖片維度變小,相對單位資訊含量提高,正確率會提升是對的,這邊可以看一下 Allison-QKL 這位網友的嘗試

圖片來源:Joint Induction of Shape Features and Tree Classifiers
上圖解釋它怎麼用在數字分類上(同樣都有某個形狀)
決策樹的優缺點,【AI60問】Q25決策樹什麼時候使用?有什麼優缺點?這篇文章寫得很好,實務上因為很好解釋結果原因,所以很常用,但要注意輸入限制(連續性的資料x)和 overfitting(用訓練資料效果很好,但用沒看過的測試資料效果很差的現象)
樹深度常見七層內,AI(if-else判斷)跟決策樹的差別會不會重疊。
Kaggle 上有人分享用決策樹做手寫數字分類的程式碼。
ps. 在 day9 有稍微提到決策樹的節點分類計算方式,有興趣可以看看。
會說它是決策樹進階版的原因是基於scikit learn 的 RandomForestClassifier 設定,使用大量決策樹來預測,然後選擇最多決策樹預測的類作為結果輸出。它也可以用大量 SVM 或邏輯迴歸組成。
隨機森林的優缺分析可見 cupoy 的 Ray 分析~
Kaggle 跟 codingame 上都有人分享用隨機森林實作的程式碼。
這邊就先快速的對可以用在手寫數字辨識系統的機器學習方法做個小結。
對要製作一個手寫數字辨識系統來說,這些機器學習的方法都是可以使用的方法,回歸到昨天的結論,只要能達成目的的方法就是好方法!
到今天為止,不論是使用 Day4 提到的 OCR,Day16 講的 NN,或是今天說的其它機器學習方法,相信大家都能做出屬於自己的手寫數字辨識系統了~
明天就讓我們來聊聊相關線上資源跟平台吧,大家明天見!


 iThome鐵人賽
iThome鐵人賽