今日大綱
不同於一般的神經網路,RNN考慮了上一個神經元的輸出,適合應用於時間序列的資料,自然語言處理即為常應用的領域,因語言有上下文的關聯,詞彙會因為上下文而有不同的語意。
RNN與線性迴歸的架構類似,不同的是激活函數,RNN較常使用hyperbolic tangent當作激活函數,線性迴歸則為線性函數。RNN的輸入除了x之外,還有上一層隱藏層的值。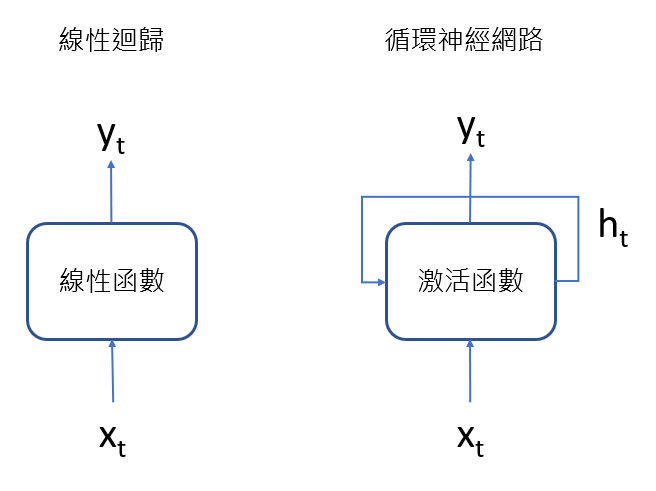
將循環神經網路攤開後如下圖,x為輸入層(input layer),h為隱藏層(hidden layer),y為輸出層(output layer)。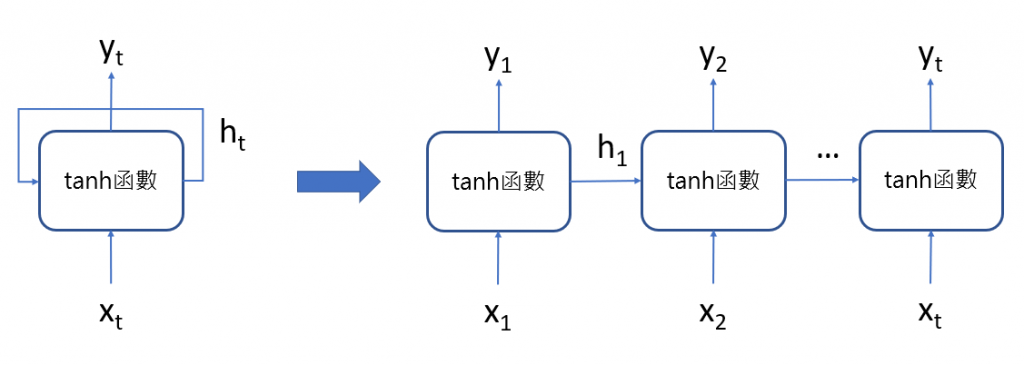
隱藏層與輸出層的計算公式如下: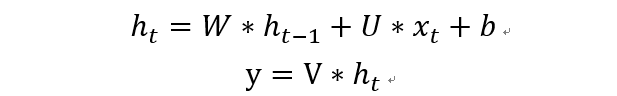
RNN能夠處理不同長度的資料以及不同長度的輸出,分為以下四種:
RNN有梯度消失(Vanishing gradient)與梯度爆炸(Exploding gradient)的問題,激活函數為hyperbolic tangent,經過轉換後的函數介於1到-1之間,偏微分後的數值將會介於0到1之間。如果一開始權重小於1,在優化求解使用反向傳播(back probagation)時,越前面神經層的權重將會越來越小,趨近於0,發生梯度消失;如果權重大於1,將會使越前面神經層的權重越來越大,發生梯度爆炸。LSTM長短期記憶模型即為改善梯度消失與梯度爆炸的模型,明天將會進行介紹。
今天的範例使用阿拉伯數字手寫辨識,總共有10個類別,為數字0到9。一開始先將資料匯入。
from tensorflow.keras.datasets import mnist
from tensorflow.keras import utils
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import SimpleRNN, Dense
(x_train, y_train), (x_test, y_test) = mnist.load_data()
接著將資料做正規化使其介於0到1之間,並且將目標變數從數字0-9變成類別變數one-hot encoding,總共有10個欄位。
x_train = x_train.reshape(-1,28,28)/255.
x_test = x_test.reshape(-1,28,28)/255.
y_train = utils.to_categorical(y_train, num_classes = 10)
y_test = utils.to_categorical(y_test, num_classes=10)
建立簡單的RNN模型,一層RNN層、一層全連接層。
model = Sequential()
model.add(SimpleRNN(units = 64, batch_input_shape = (None, 28, 28), unroll = True))
model.add(Dense(units = 10, activation = 'softmax'))
model.summary()
model.compile(loss = 'categorical_crossentropy', optimizer = 'adam', metrics = ['accuracy'])
train_history = model.fit(x_train, y_train, epochs = 10, batch_size = 64, validation_split = 0.2, shuffle = True, verbose = True)
acc = model.evaluate(x_test,y_test, verbose = 0)[1]
acc
測試集的準確率達95%。
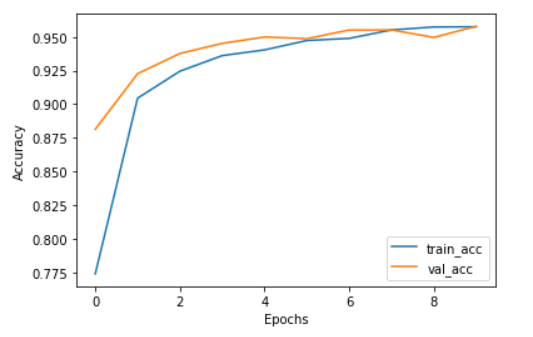
最後將準確率視覺化,從圖可看出訓練集及驗證集的準確率很接近,沒有overfitting的問題。
import matplotlib.pyplot as plt
plt.plot(train_history.history['accuracy'], label = 'train_acc')
plt.plot(train_history.history['val_accuracy'], label = 'val_acc')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend()
plt.show()
感謝您的瀏覽,程式碼已上傳Github

