
今日大綱
電腦無法像人一樣馬上理解文字與語音的意思,需要將非結構化的資料向量化,才能夠進一步作訓練。將文字向量化之前需要預先處理文字,首先需要做斷詞,將每個單字切開,英文較方便處理,因為都是以空格隔開,而中文必須套用中文斷詞的套件,如簡體字的jieba、中研院所提供的繁體中文套件CKIP等。以下以英文為範例,進行斷詞。
import nltk
nltk.download('punkt')
text = "You will improve your reading comprehension and develop your vocabulary on a diverse range of international events, celebrations and topics."
words = nltk.word_tokenize(text)
words

從結果可看出,英文斷詞就是將每個字以空格切開。
接著,如果是英文字需要先將文字還原,例如walks轉成walk,而中文則不需要這個步驟。
還原方式有分兩種:
以下為stemming的實作
ps = nltk.porter.PorterStemmer()
ps_text = [ps.stem(word) for word in words
' '.join(ps_text)

從結果可以看出improve變成improv,vocabulary變成vocabulari,有些字會變得很奇怪。
以下為lemmatization實作
lem = nltk.WordNetLemmatizer()
lem_text = [lem.lemmatize(word) for word in words]
' '.join(lem_text)

可以看出僅有複數的單字 events、celebrations、topics這幾個字變成單數形式。
最後,將停用詞以及標點符號去除,在英文裡如the、a都是沒有語意的單字,而中文如那個、這個等,沒有任何實質意義的詞。
import string
nltk.download('stopwords')
stopword_list = set(nltk.corpus.stopwords.words('english')+ list(string.punctuation))
filter_tokens = [token for token in words if token not in stopword_list]
filter_text = ' '.join(filter_tokens)
filter_tokens

詞袋(BOW)計算每個單字出現的次數,由最常出現的單字猜測大意。
## BOW
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import TfidfTransformer
corpus = ["Today is a good day.",
"Yesterday was a cloudy day.",
"Hope tommrow will be a good day."]
vectorizer = CountVectorizer()
x = vectorizer.fit_transform(corpus)
word = vectorizer.get_feature_names()
print("Vocabulary: \n", word)
print("BOW: \n", x.toarray())
get_feature_names()儲存詞袋裡有哪些詞彙,將轉換過後的詞會變成array時,輸出每個句子對應出現的詞彙。
第一個句子Today is a good day. 在詞典裡day在第三個位置,因此第2個index數值為1,以此類推。
Tf就是詞會出現的次數,IDF就是逆向檔案頻率,這兩個數字相成即為TF-IDF,如果一個詞出現在第n個檔案很高,但是出現在所有檔案的次數也很高的話,其代表性降低,TF-IDF值就會很小,例如the、a,就會常出現在文件裡。反之,出現在所有檔案的次數低的話,這個詞就比較重要。
詞頻(Term frequency)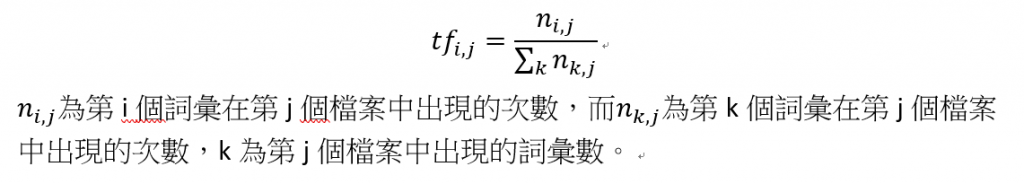
逆向檔案頻率(Inverse document frequency)
## TF-IDF
import numpy as np
transformer = TfidfTransformer()
tfidf = transformer.fit_transform(x)
print("TF-IDF: \n", np.around(tfidf.toarray(),2))
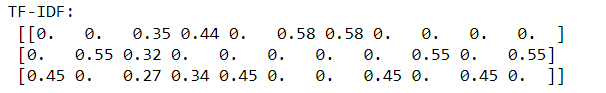
TF-IDF所產生的值介於0-1之間,數值越大代表重要性越高。
謝謝您的瀏覽,程式碼已上傳Github。
