這篇教學會使用 Teachable Machine 訓練「剪刀、石頭、布」的影像模型,再透過 OpenCV 搭配 tensorflow 讀取攝影鏡頭影像進行辨識。
原文參考:辨識剪刀、石頭、布
因為程式使用 Jupyter 搭配 Tensorflow 進行開發,所以請先閱讀「使用 Anaconda」和「Jupyter 安裝 Tensorflow」,安裝對應的套件,如果不要使用 Juputer,也可參考「使用 Python 虛擬環境」,建立虛擬環境進行實作。

開啟 Teachable Machine 網站後,點擊「開始使用」建立新專案 ( 最下方可以切換語系為繁體中文 ),選擇 「圖片專案 > 標準圖片模型」,進入圖片模型訓練流程。
參考「使用 Teachable Machine」文章,訓練「剪刀」、「石頭」和「布」以及「背景」共四個分類,範例使用 a 作為剪刀分類的名稱,b 作為石頭分類名稱,c 作為布分類名稱,bg 作為背景分類名稱 ( 建議左手和右手都要訓練 )。
為什麼要訓練「背景」呢?因為如果沒有背景分類,會在沒有出拳的時候自動判斷最接近的分類,導致判斷出錯,所以建議一定要訓練一個背景的分類 ( 背景的分類除了單純的背景,也可以加入許多雜亂的圖片,增加背景的準確度 )。
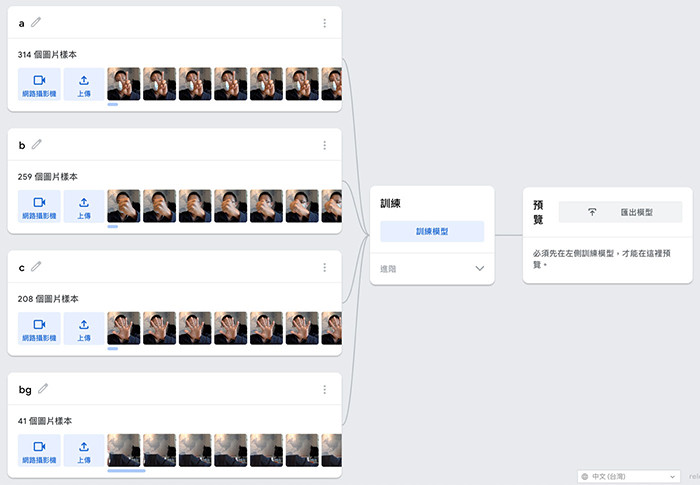
分類建立後點擊「訓練模型」,等待訓練完成,可以從預覽區域測試模型。
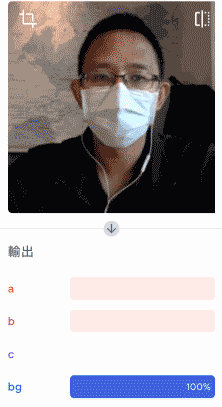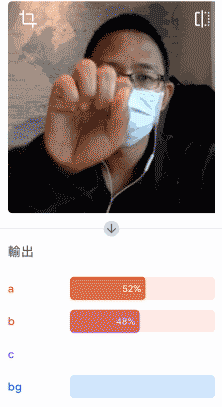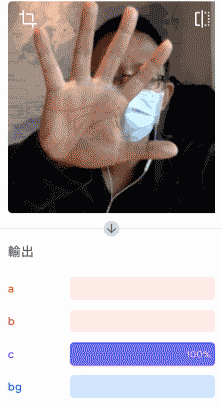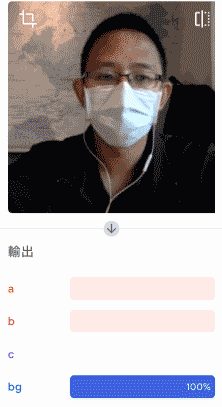
確認辨識結果沒問題,就可以將模型匯出為 Keras 類型,解壓縮後將 .h5 的模型檔案放到指定的資料夾裡。
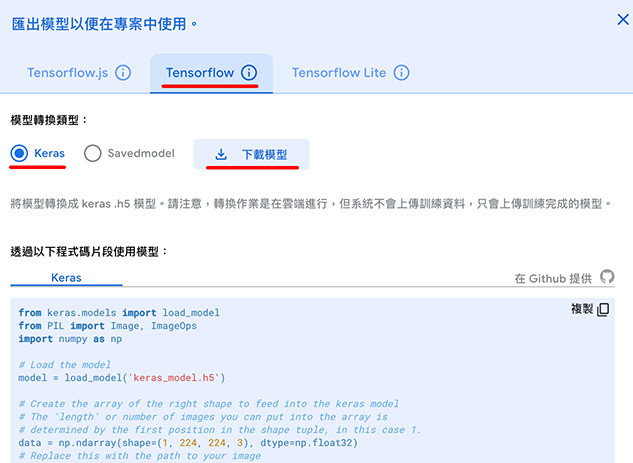
下方的程式碼使用 OpenCV 讀取攝影鏡頭的影像,即時判斷現在出現的影像是什麼分類,並透過 putText() 方法,在影像中加入分類的名稱。
import tensorflow as tf
import cv2
import numpy as np
model = tf.keras.models.load_model('keras_model.h5', compile=False) # 載入模型
data = np.ndarray(shape=(1, 224, 224, 3), dtype=np.float32) # 設定資料陣列
def text(text): # 建立顯示文字的函式
global img # 設定 img 為全域變數
org = (0,50) # 文字位置
fontFace = cv2.FONT_HERSHEY_SIMPLEX # 文字字型
fontScale = 2.5 # 文字尺寸
color = (255,255,255) # 顏色
thickness = 5 # 文字外框線條粗細
lineType = cv2.LINE_AA # 外框線條樣式
cv2.putText(img, text, org, fontFace, fontScale, color, thickness, lineType) # 放入文字
cap = cv2.VideoCapture(0)
if not cap.isOpened():
print("Cannot open camera")
exit()
while True:
ret, frame = cap.read()
if not ret:
print("Cannot receive frame")
break
img = cv2.resize(frame , (398, 224))
img = img[0:224, 80:304]
image_array = np.asarray(img)
normalized_image_array = (image_array.astype(np.float32) / 127.0) - 1
data[0] = normalized_image_array
prediction = model.predict(data)
a,b,c,bg= prediction[0]
if a>0.9:
text('a') # 使用 text() 函式,顯示文字
if b>0.9:
text('b')
if c>0.9:
text('c')
cv2.imshow('oxxostudio', img)
if cv2.waitKey(1) == ord('q'):
break # 按下 q 鍵停止
cap.release()
cv2.destroyAllWindows()

如果要加入中文,必須要使用 pillow 函式庫,開啟命令提示字元或終端機,啟動 tensorflow 虛擬環境安裝 pillow 函式庫,再使用下方的程式碼,就能夠加入中文的文字。
import tensorflow as tf
import cv2
import numpy as np
from PIL import ImageFont, ImageDraw, Image # 載入 PIL 相關函式庫
fontpath = 'NotoSansTC-Regular.otf' # 設定字型路徑
model = tf.keras.models.load_model('keras_model.h5', compile=False) # 載入模型
data = np.ndarray(shape=(1, 224, 224, 3), dtype=np.float32) # 設定資料陣列
def text(text): # 建立顯示文字的函式
global img # 設定 img 為全域變數
font = ImageFont.truetype(fontpath, 50) # 設定字型與文字大小
imgPil = Image.fromarray(img) # 將 img 轉換成 PIL 影像
draw = ImageDraw.Draw(imgPil) # 準備開始畫畫
draw.text((0, 0), text, fill=(255, 255, 255), font=font) # 寫入文字
img = np.array(imgPil) # 將 PIL 影像轉換成 numpy 陣列
cap = cv2.VideoCapture(0)
if not cap.isOpened():
print("Cannot open camera")
exit()
while True:
ret, frame = cap.read()
if not ret:
print("Cannot receive frame")
break
img = cv2.resize(frame , (398, 224))
img = img[0:224, 80:304]
image_array = np.asarray(img)
normalized_image_array = (image_array.astype(np.float32) / 127.0) - 1
data[0] = normalized_image_array
prediction = model.predict(data)
a,b,c,bg= prediction[0]
if a>0.9:
text('剪刀') # 使用 text() 函式,顯示文字
if b>0.9:
text('石頭')
if c>0.9:
text('布')
cv2.imshow('oxxostudio', img)
if cv2.waitKey(1) == ord('q'):
break # 按下 q 鍵停止
cap.release()
cv2.destroyAllWindows()

大家好,我是 OXXO,是個即將邁入中年的斜槓青年,我已經寫了超過 400 篇 Python 的教學,有興趣可以參考下方連結呦~ ^_^

