前幾天談的都是 GAN 生成影像的原理,那當我們訓練出 GAN 以後,要如何評估模型產生影像的表現並和其他生成模型比較呢?
人工判斷也許是最快能想到的方法。早期的 GAN 在 paper 中往往只會呈現模型產生的影像,說明他們的方法「看起來」比較好。也有一些研究會找一群受試者評分投票生成影像的品質,並統計出結果。然而,人的判斷難免主觀且不穩定,我們很難有一致的標準來比較 GANs,而如果為了提升人工判斷的穩定性而找了大量的受試者評分大量的影像,成本會十分高昂
除了人工判斷以外,還有什麼方法可以評估 GAN 的表現好不好呢?
分類器的公開模型非常多,例如我們可以輕易找到一個在 ImageNet-1k 分類任務上表現還不錯的模型,當我們將一張生成影像輸入到分類模型時,模型會輸出這張影像屬於各個類別的機率。
這裡以動物影像生成任務為例,如果我們把一張很逼真的狗狗影像輸入到分類器時,分類器會判斷這張影像屬於狗的機率非常高。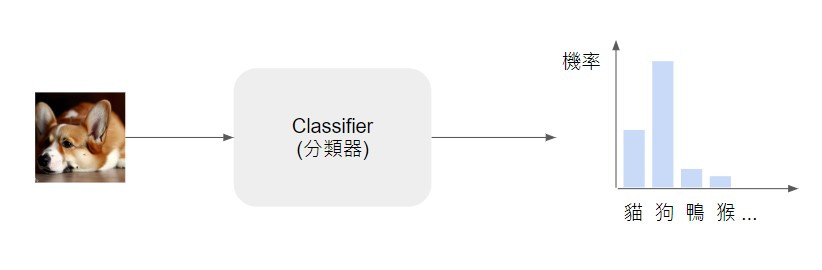
然而如果我們把一張充滿雜訊、看不出是什麼影像輸入到分類器時,分類器就無法判斷這張影像到底屬於哪個類別,輸出的各個類別的機率可能都差不多。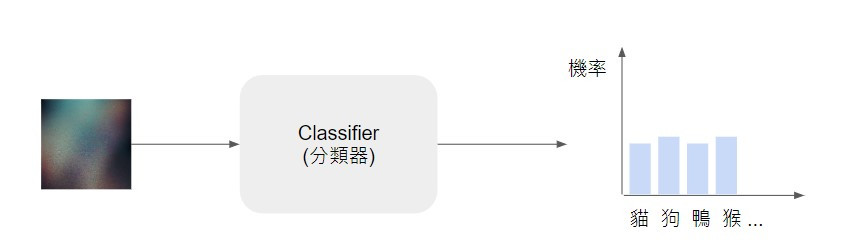
因此,我們可以藉由分類器輸出的類別機率分布來判斷影像的品質。一張生成影像通過分類器得到的機率如果越集中在特定的類別,代表它的品質越好,而如果得到的機率發散在不同的類別,代表影像可能什麼都不像,品質就會是比較差的。
但是這樣的評估方法有沒有什麼潛在的問題呢?答案是,問題還不少。
首先,GAN 的訓練常常會遇到 mode collapse 的問題,意思就是隨著訓練時間增加,GAN 產生少數幾張影像的比例越來越高。
以下圖的狀況為例子,隨著訓練時間增加,generator 產生的狗狗影像確實越來越真實了,單看其中一張的會覺得產生的影像品質很不錯,但多看幾張就會發現 generator 老是產生同一張邊境牧羊犬的影像,生成影像是缺乏多樣性的。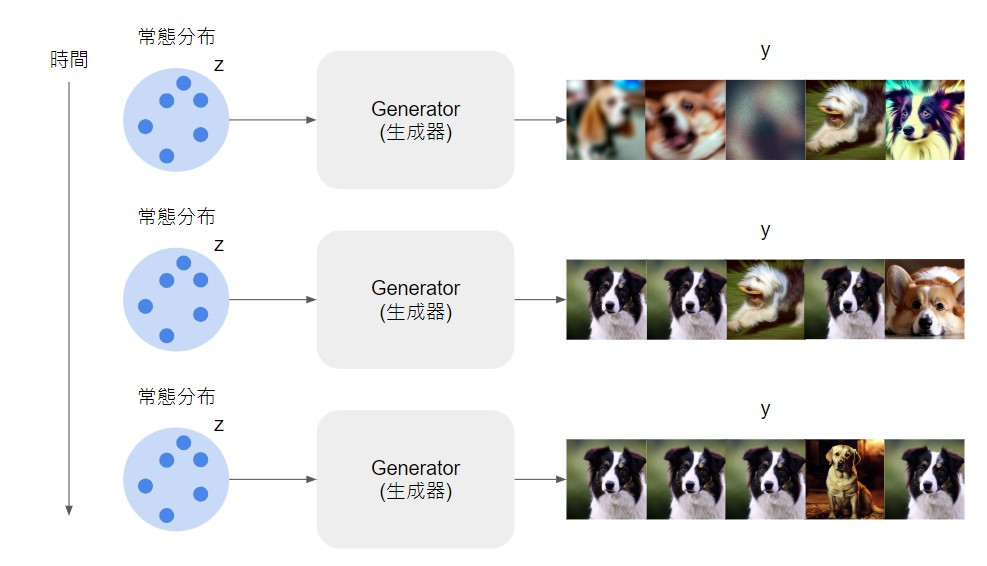
這些出現比例越來越高的圖,剛好就落在 discriminator 的「盲點」。由於 generator 的學習目標是要盡可能「騙過」discriminator,所以就有可能把握住 discriminator 的「盲點」,透過重複產生相近的圖片以達到目標,但是只會產生同一張影像的 generator 並不是我們想要的,畢竟我們訓練 GAN 就是希望能產生更多原本不存在的新影像啊
儘管,上述提到的 mode collapse 問題到現在仍沒辦法本質上的解決,不過我們是有辦法測量生成影像的多樣性的。
要評估生成影像的多樣性,一樣可以使用現成的分類器,只是除了觀察每張生成影像通過分類器得到的類別分布,還要把這些影像的類別分布平均起來。如果 generator 產生的影像很多樣,包含各種類別,我們就可以看到平均類別分布是很均勻的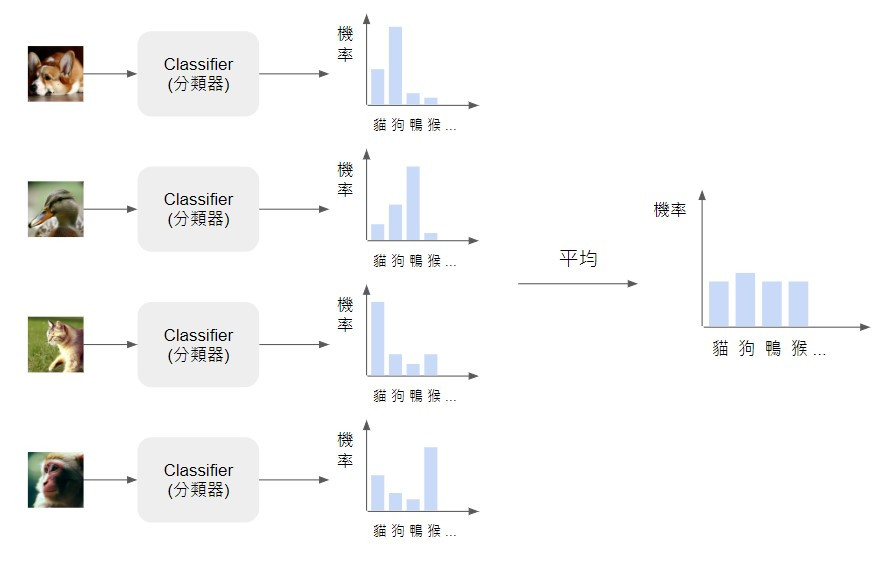
然而,如果 generator 都只產生少數幾張影像,平均的類別分布可能都集中在特定類別,這樣就代表生成影像的多樣性可能是不足的,如下圖。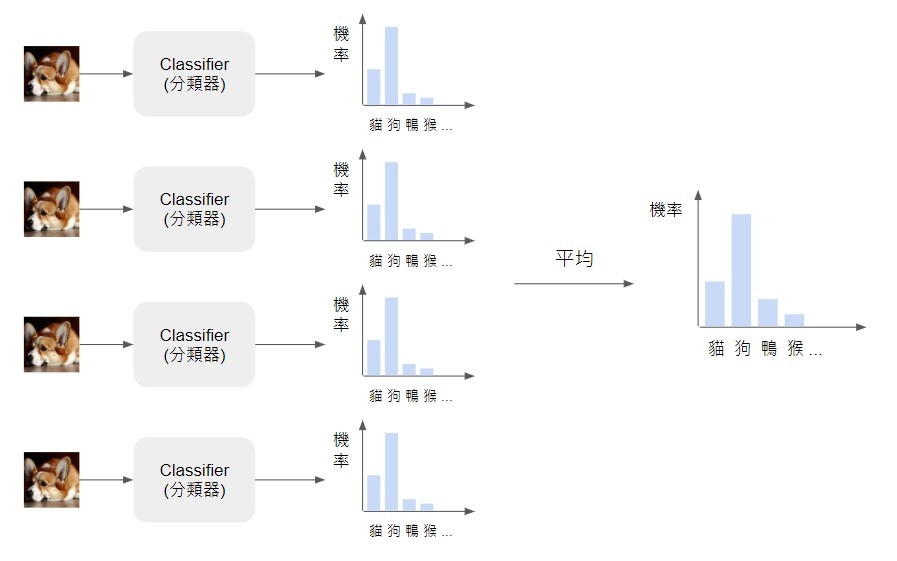
Inception score (IS) 就是一個能同時評估整體生成影像多樣性和個別影像品質的指標。Inception score 越高,代表 GAN 能生成很多獨特且逼真的影像。它也是目前評估生成模型表現的熱門指標。
其實 inception score 的原理就如同剛剛所介紹的:單一生成影像的類別分布越集中越好,整體生成影像的平均類別分布則越平均越好。由於它所採用的現成分類器是用 ImageNet 訓練的 inception network,因此稱為 inception score。
Inception score 的數學形式如下: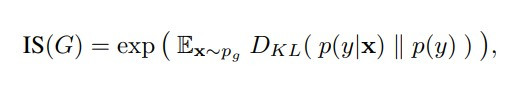
它計算了單一生成影像的類別分布 p(y|x) 與整體生成影像的平均類別分布 p(y) 的 KL divergence 的期望值。記得在[Day 4] 淺談 GAN 的原理有提到 divergence 可以用來估測兩個分布的差距,由於單一生成影像的類別分布 p(y|x) 要越分歧越好,整體生成影像的平均類別分布 p(y) 要越均勻越好,兩個分布應該要是很不相像的,因此當我們計算兩者的 KL divergence,數值大小就可以表現生成影像的品質。
這麼說用 inception score 評估 GAN 的表現好像蠻不錯的,對嗎?
事實上,使用 inception score 有許多的限制。
首先,當 generator 產生的影像不屬於分類器能分類的類別,即使影像品質很好,得到的類別分布可能也無法集中在特定類別(無法被分類器判別成一個明確的類別)。例如鯊魚就不在 inception network 可以分類的類別,即是 generator 產生了品質很好的鯊魚影像,得到的 inception score 可能還是很低。
第二,inception score 無法評估類別內的多樣性。例如我們如果訓練了一個專門生成各種狗狗影像的 GAN,由於影像全部都會被 inception network 分類為狗的類別,即使生成影像包括各種品種的狗,inception score 還是會很低。
Fréchet inception distance (FID) 是另一個常用來評估生成模型表現的指標,不同於 inception score 只會透過生成影像得到的分布來衡量 generator 的表現,Fréchet inception distance 會比較生成影像和真實影像得到的分布的差異。
這個指標比較不會受到 inception network 能分辨的類別限制,因為它不是透過分類器輸出的影像類別分布來估測生成表現,而是取分類器抽取的影像特徵分布來進行後面的計算。它假設真實影像特徵的分布和生成影像特徵的分布分別都是高維度的 Gaussian 分布,而 Fréchet inception distance 就是計算兩個分布的 Fréchet 距離,這個距離越小,就代表生成模型的表現越好!
雖然這個指標可以處理先前提到計算 inception score 會遇到的兩個問題:
然而,它假設了影像特徵的分布是 Gaussian 分布,很可能不符合實際的情況,因此未必能完全反映生成影像和真實影像的差距。
其實,假如我們訓練出一個「硬背的 GAN」,它產生影像的方式就只是如實畫出和真實影像一模一樣的圖,無論是參考 inception score 或是 Fréchet inception distance 都會判斷它是效能很好的 GAN。
但實際上,這樣的 GAN 很不理想的,因為如果它只是產生和真實影像一模一樣的圖,我們就用真實影像就好了
關於如何評估生成模型(包括 GAN)的表現,仍然是個持續在研究中的問題,也陸續有不同的指標被提出,如果有興趣了解更多生成效能指標以及它們的優劣,可以參考以下兩篇文章~

