
當我們嘗試用「0」、「1」描述生活裡的所有場景、居住城市、街道等,會是怎麼樣的世界呢?
我們用電腦看視頻、聽音樂、查詢資料時,這也正是電腦正在做的事情,而它使用的「0」、「1」叫做 二進制代碼(Binary Code)
就開門見山的說,因為這是個可靠且穩定的儲存資料的方法
為何可靠又穩定?? 下面來舉個例子說明
主記憶體是由可以切換高電壓或低電壓的「電晶體」所組成,電壓是會擺動的,但對電腦來說他就只認得兩種情況,分別是高電壓(high)和低電壓(low),或是開(on)和關(0ff)。CPU 會去解讀現在的電壓狀態是屬於高還是低(開或是關),也就是它會利用電晶體的狀態進一步去操控電腦的其他元件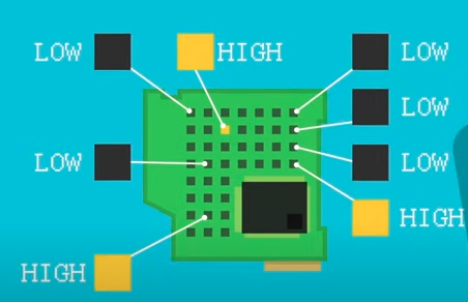
不論今天要儲存的資料是什麼類型,mp4, mp3, png, jpg, pixel, number, text 等,電腦都不需要預先去判斷和解讀資料類型,因為它都會根據一套規則把資料編成二進制的序列(binary sequence),在電腦的世界就是那麼單純,只有「0」和「1」的存在,單位是位元 (bit)
0 => 關 => false
1 => 開 => true
「位元」又叫做 Binary digit,是指二進制中的其中一位(0或1),也是資料儲存和傳遞的最小單位
早期的電腦以 8 個位元為存取單位,因此 8 bits = 1 byte,由於電腦的存取機制是以位元組為單位,所以表示資料所需的為位元數通常是 8、16、32
這裡要來算一下數學
兩個位元可以有多少種不同的排列組合呢? 答案是4種 (00、01、10、11)
上面提到8 bits = 1 byte,也就是有 2 ^ 8 = 256 種 排列組合,這樣的組合足以表示每一個英文字母(大小寫)、數字和標點符號,ASCII 就是這類型組合的公定標準
我們如果要表示更大的資料,那就再增加位元數就好
為了避免各國間的位元表示方式打架,以及不同電腦系統和程式語言之間的字元編碼不一致問題,萬國碼(Unicode)就出現了,他是一套字元編碼標準,讓在不同的電腦和作業系統間能順暢的交換文字資料
十進制對我們應該不陌生。主要是以 0-9 的數字表示,以10的次方為基底,之所以能延續到現在,跟我們有十根手指頭有很大的關係(沒在唬爛😂)
六十進制則常用在時間上,像是每分鐘 60 秒,每小時 60 分鐘,除此之外,已經很少實際應用的場景了
84 如果用十進制表示會是: 8 X 10 ^ 1 + 4 X 10 ^ 0
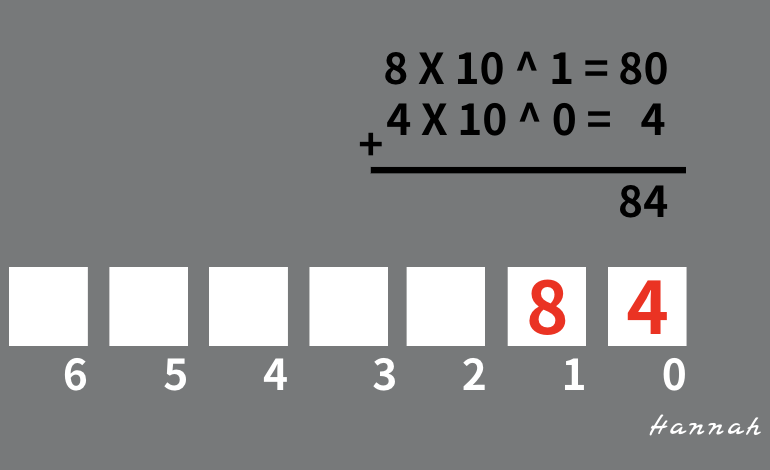
為什麼會從0次方開始,接著1次方、2次方...以此類推呢?
比如今天有個數字 168 ,可以把它拆解為 1 個一百 + 6 個十 + 8 個一
100's | 10's | 1's
------------- | -------------
1 | 6 | 8
從右到左來看,每跨一個欄位就會乘以 10 倍,這就是十進位的運作,是以 10 的倍數為基底。二進制的概念也是如此喔
每個位數以2的次方為基底,像是上面舉例的 84,用二進制表示就是
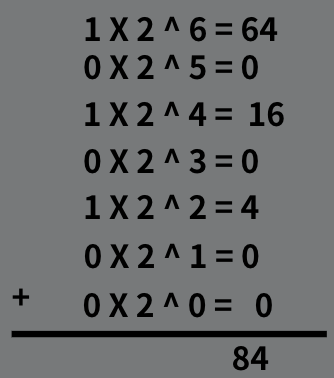

除了數字,字母的表示就無法用數學算出來了,那麼他怎麼被編制的呢?
是以 UTF-8 為標準被編譯,如下圖:
你有發現字母T和上面的84其實是一樣的嗎?都是 01010100 (貓貓圖上面的圖片少一個位元,這裡可以先不用管XD)
電腦要如何分辨 01010100 究竟是 binary number 或 binary text 呢?
其實...對電腦來說都一樣
電腦沒有辦法單獨的從序列就知道這是表示什麼,像是我們不能以「手足」兩個字就知道是在講兄弟姐妹還是在講我的手和腳,必須依照前後文的語意來判斷才行
PS. 若有解說不清或是不正確之處,歡迎指教
電腦的世界很只有「0」和「1」的存在,是以二進制的方式在運作,最小單位是位元 (bit),而 8 個位元又稱為一個位元組(byte)。我們的生活也跟進制息息相關,像是加法是十進制、時間的表示則是六十進制。如果說電腦的世界很單純,那麼人類的世界還真是複雜呀~


 iThome鐵人賽
iThome鐵人賽