今天我們要細講 Transformer 模型架構的 Encoder(編碼器) 的部分,也就是圖中的左半部,那我們就一一剖析裡面的每一層在做哪些事情
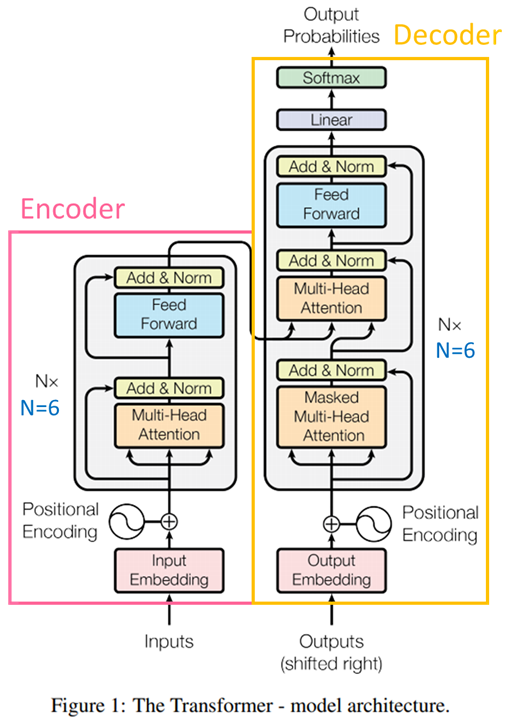
以上圖出自李謦伊
它主要的功能呢就是將輸入的文本中的每個詞彙或字符轉換為數值表示,通常是一個向量。這樣做的目的是將符號性的文本信息轉化為模型可以處理的數學形式,使模型能夠計算、操作和學習文本的特徵(使模型能夠更好地理解和處理文本數據)。
這裡的重點就是要對位置進行編碼。因為在自注意力機制中並不具備處理序列中的位置信息的能力,因此需要額外的位置編碼來告訴模型每個詞在序列中的位置。
最終目的是將它們添加到詞嵌入向量中,以獲得包含位置信息的新的詞向量。這樣,模型在處理不同位置的詞時可以考慮到它們在序列中的相對位置。
Multi-Head Attention 就是上一章講到的 self-attention 的擴展,主要差異之一是Multi-Head Attention會將查詢(Query)、鍵(Key)、和值(Value)拆分成多個低維度的向量,然後分別進行注意力計算,這些輸出最終被串聯在一起,並經過線性映射以生成最終的Multi-Head Attention輸出。
這樣做的目的是讓模型能夠同時學習不同的關注模式,以更好地捕捉序列中的不同依賴關係。
這包括兩個部分,殘差連接(Residual Connection)和層規範(Layer Normalization)
Residual Connection 目的是保留原始輸入信息,因為當我們在一個神經網絡中進行多個層的運算時,有時候我們擔心模型可能會丟失原始輸入的重要信息,通過將前一層的輸出與當前層的輸入相加,確保了原始輸入信息的傳遞。
Layer Normalization 用於正規化每一層的輸出,以確保模型在訓練過程中更穩定,提高訓練的穩定性,有助於模型更快地收斂到最優解。
簡單說就是保留原始信息,同時保持訓練的穩定性
會先對每個序列位置的特徵進行線性轉換,將其映射到一個新的特徵空間,進一步提取有用的特徵,以便在後續的處理中使用。
在線性轉換後接著會應用非線性激活函數,非線性激活有助於捕捉序列中的非線性關係,並提高模型的表達能力。
通過線性轉換和非線性激活所提取到的更高級別表示能力的特徵在序列處理中非常有用,例如,它們可以捕捉詞彙、語法和語義信息。
總之,編碼器是由多個相同的編碼器層堆疊而成,每個編碼器層包括自注意力機制、多頭注意力、前向全連接網絡、殘差連接和層歸一化等結構。這些結構共同協作,使得模型能夠有效地處理輸入序列,並生成相應的隱藏表示,以供後續解碼器的使用。

