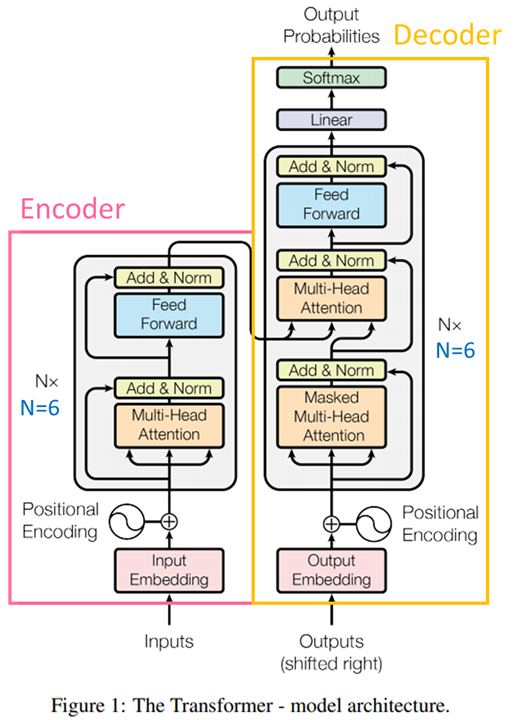
以上圖出自李謦伊
今天我們要細講 Transformer 模型架構的 Decoder(解碼器) 的部分,也就是圖中的右半部,這邊會說明它跟 Encoder 的主要差別
這是在 Encoder 裡面沒有的,主要目的是確保在生成序列中的每個位置時,模型只能參考到該位置之前的部分(限制模型的訪問範圍),而不會看到該位置之後的內容。
它在生成序列(如機器翻譯中的目標語句生成)時非常有用,因為在生成每個詞彙時,我們只應該參考到之前已生成的詞彙,也就是要一個一個的輸出,和原本self-attention一起輸出不同,以確保生成的序列合法且具有一致性。遮罩機制確保模型不會在生成過程中"作弊",即不會提前看到未來的部分。
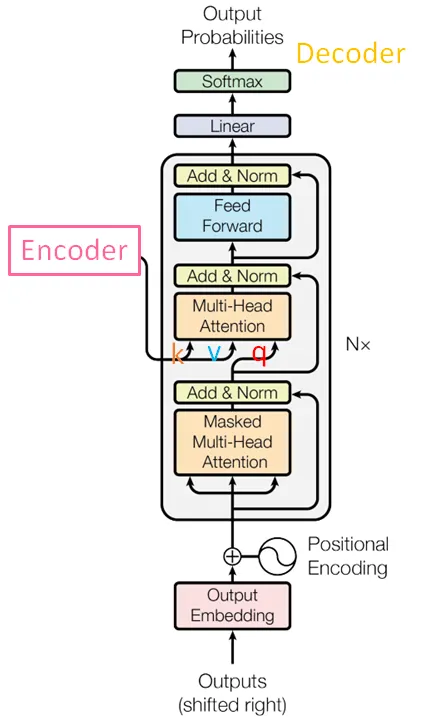
以上圖出自李謦伊
從這張圖呢我們可以看出 Decoder 的輸入來自兩個部分,簡單來說中間層 Multi-head Attention 的輸入 q 來自於本身前一層的輸出(當前 Decoder 層的輸入序列),而 k, v 則是來自於 Encoder 的輸出(來自 Encoder 的輸出序列的特徵表示)。
這兩個主要來源
它們共同負責生成下一個詞彙的概率分佈。根據這個分佈,模型可以選擇生成概率最高的詞彙作為下一個預測詞彙(也就是輸出是一個機率)。這使得模型能夠生成具有意義的文本序列。
Linear Layer(線性層):它將 Decoder 最後一層的輸出特徵向量映射到目標詞彙的詞彙表大小的維度上,對輸出的特徵表示進行線性變換,以使其維度與詞彙表的大小相匹配。
Softmax Layer(Softmax層):它將每個詞彙的分數轉換為該詞彙的概率,這是通過應用 softmax 函數來實現的,它將分數轉換為0到1之間的值,並確保所有詞彙的概率總和為1。
最終,Softmax Layer 的輸出是一個機率分佈,其中每個詞彙都有一個對應的機率值,表示生成該詞彙的機率。
總之,Decoder是Transformer模型中負責生成文本或序列的部分,它根據來自Encoder的信息以及生成的上下文來進行預測,並確保生成的序列是合法且有意義的。

