我們一起度過了之前幾次的專題,相信大家應該都對建立一個 AI Model所需要的流程有所有理解了!萬般不離其宗,基本上最重要的事情就是我們怎麼設計出適合的模型以及要如何訓練?那我們今天來講人眼視線(Eye Gaze)的模型設計
首先我們先複習一下我們 Eye Gaze 預測的目標,亦即:
1.Input:
1.完整的人臉照片或者僅有眼睛周遭的照片
2.可能再加上 Headpose 資訊以利模型估計
2.Output:
輸出 3D 或者 2D 的視線方向 ( 並且注意大部分為在相機座標系上的方向
不同的輸入照片有誤同的考量,例如直覺上覺得觀察眼睛附近因該足夠判斷,所以組,但也有因為有論文發現有完整臉似乎對 Gaze 預測更準所以鼓勵放全臉。這個模型的輸入上我們到可以在討論,之後我們也會討論一些很有趣的實驗,例如再沒看到眼睛部份我們的模型準度可到多少?我們今天先以模型設計的方向出發,我們的預測方法可以分成以下兩種:
1.Geometry-based: 需要針對眼球模型作建模
2.Appearance-based: 只從眼睛照片去做判斷
Geometry-based 的方法基本為利用結構資訊來幫助視線預測,如下圖: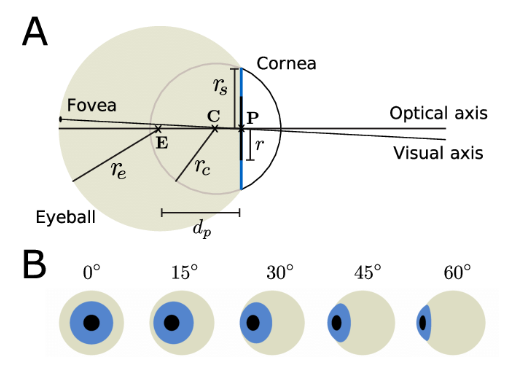
我們可以看到眼球模型其實是一個非常有規則的物體,因此我們可以量測出來人類眼球模型了!而你轉眼珠時向右看跟向前看就是長得非常不一樣,如上圖b,我們可以看得出眼球轉動時變化的程度,而 Geometry-based 正是利用這一點來推動的!
但那我們應該實務上要如何用呢?總不能就只是根據經驗長這樣的照片就是幾度吧?這樣聽起來完全就是 Appearance-based了不是嗎?最常見的我們我們需要預測出關鍵點,如下圖: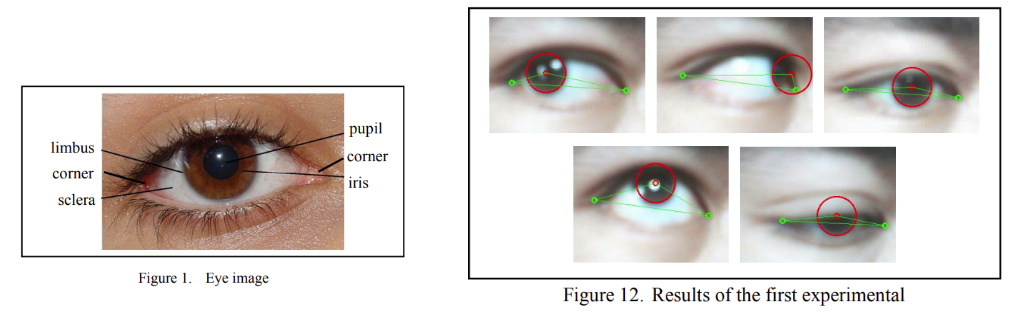
我們可以透過找到眼角旁邊兩點位置跟 瞳孔位置 來跟3D 眼睛模型比較就可以推算出眼睛轉了幾度,具體邏輯就像是之前介紹 Headpose那一章節提過的傳統根據 3D 人臉關鍵點跟 2D 預測關鍵點所推算出來的角度一樣!
而看到這裡,你大概也看出來 Geometry-based方法可能的問題了:如果關鍵點預測不准怎麼辦?為此有眾多論文就在討論這個,除去我們之前討論過得 lanadmark,其中還有討論如何怎麼瞳孔預測準度: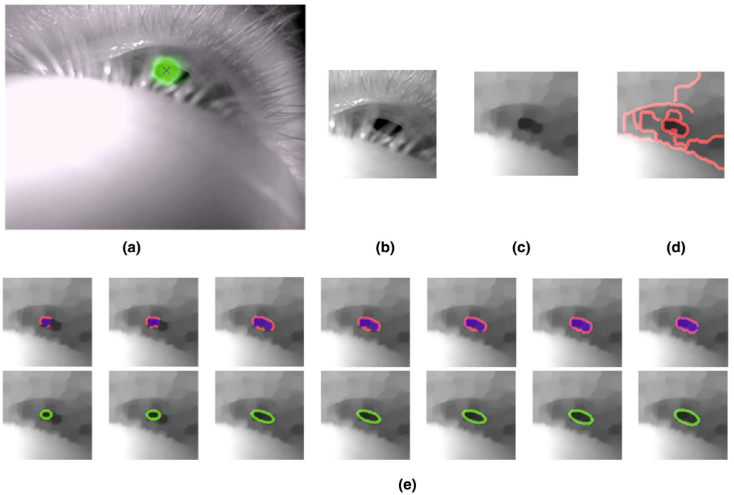
上圖這篇論文就是在討論因為瞳孔再有睫毛遮擋或者大角度時不好找,那要如何透過 iterative 的方式找到更準的瞳孔位置,有興趣可以查閱這篇
更有慎者,想說更多關鍵點應該可以更準吧(可以對關鍵點預測更準),所以把整個臉都見了模,如下圖,有興趣可以參考這一篇
Appearance-based的方法基本上是希望不要透過 3D model 這個 prior 去做預測,主要考量點跟好處有以下:
1.每個人的 3D model 理應不同,所以接需要獨立測量,如果用 Appearance-based 則可以不需要 3D model
2.Appearance-based可以設計成 end-to-end model,這樣方便訓練以及運行可以更快
舉一個 Apperance-based 最常見的例子,完整流程如下圖: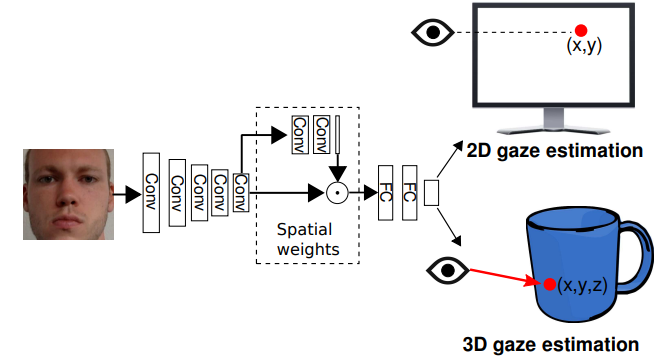
這個照片一開始被相機拍下來會被送進 Face detection model切下人臉然後接把人臉照片喂進 EyeGaze model 去預測出 eye gaze direction(2D 的點 or 3D direction)而這也是最簡單的想法,他的優點就是簡單但缺點則是有下列兩項:
1.人眼部份照片會不會太小?這樣會不會不夠資訊來判斷?
2.如果人頭的位置如果平行於鏡頭移動是不是看的點就會不一樣了?感覺需要多加入人臉的位置資訊比較好判斷
在解釋 1 這個 issue之前,我們先談談這一篇的前身作法,結構圖如下: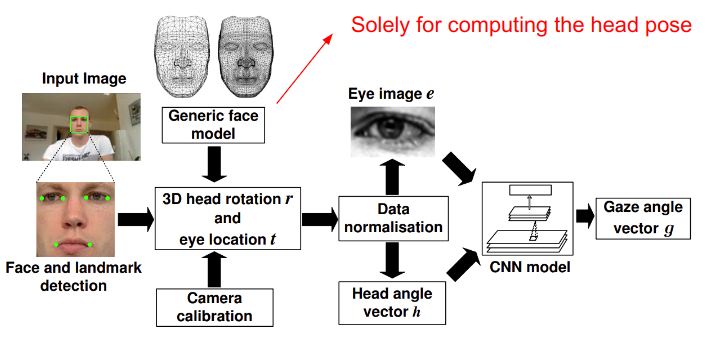
可以看到這一篇的作法為輸入 人眼照片 & Headpose 來去預測 Eyegaze,但實驗結果是我們提的這個最常見例子裡面有實驗去證明了當把人臉照片放進去模形時其實可以給Model 有非常好的資訊去判斷 EyeGaze,像下面的實驗: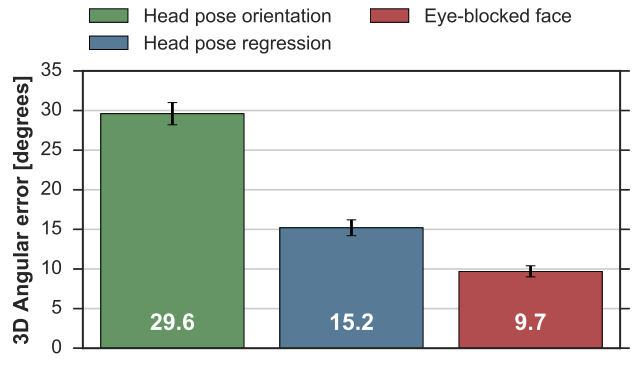
這個實驗是比較以下三點何對模型資訊量最多(亦即用作模型輸入):
1.直接將 Headpose 當作 EyeGaze(Head pose orientation
2.使用 Headpose 去做預測 EyeGaze(Head pose regression
3.使用眼睛區域被遮住的照片 (Eye-blocked face
作者驚奇的發現使用眼睛區域被遮住的照片 (Eye-blocked face) 竟然誤差只有 9 度多,離其他選項準了不知道多少!雖然我們可以預期其他都不準,但眼睛被遮住你都預測到只差 9 度那代表全臉資訊一定對 EyeGaze 很有幫助!但請記得這與不代表沒有眼睛是 Ok,畢竟還是差了 9 度,一般來說一個 EyeGaze 模型我們希望可以 5 度以內,如這一篇中下圖實驗數字: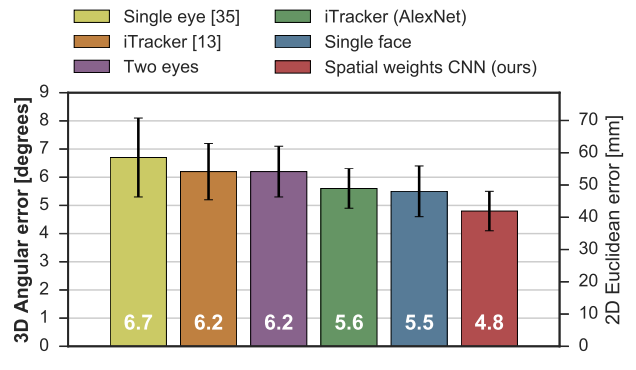
因此我們只能說:
相較於只有人眼以及Headpose,放人臉更加分!但人臉依舊可能面臨到人眼資訊不夠而扣分
但這樣我們是不是還需要人臉位置資訊呢?是的我們的猜測試對的,人頭移動導致看了不同點但我們因為只切下人臉部份因此單純切下來的人臉中我們試看不出他人臉是否移動的!對此 MIT 在2016年提出下來這樣的結構如這一篇,如下圖: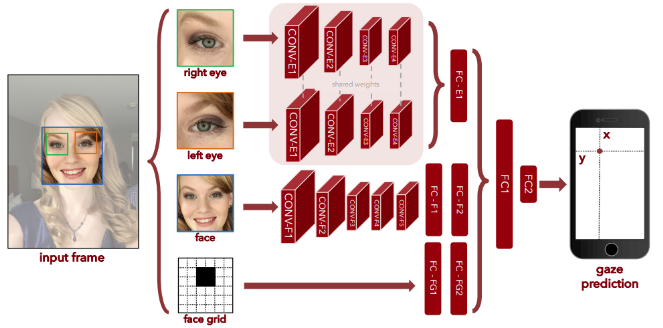
可以看到作者將人臉照片以及頭的位置(用頭在照片中位置所形成的 mask 照片替拜)一起喂進模型,甚至也考慮了人眼區域太小單獨切下人眼區域也喂進模型中,他們發現這樣的模型相較於之前的都更加的準確(iphone上大概差了 1cm 左右,那個時候已經非常不錯了)!他實驗說明了人臉位置資訊其實是非常重要的!
但一定要用頭在照片中位置所形成的 mask 照片去表示嗎?可不可以簡化一下?有的Google 在 2019年發的這一篇為了簡化模型,乾脆直接用人臉的座標去表示人臉位置,效果也很不錯: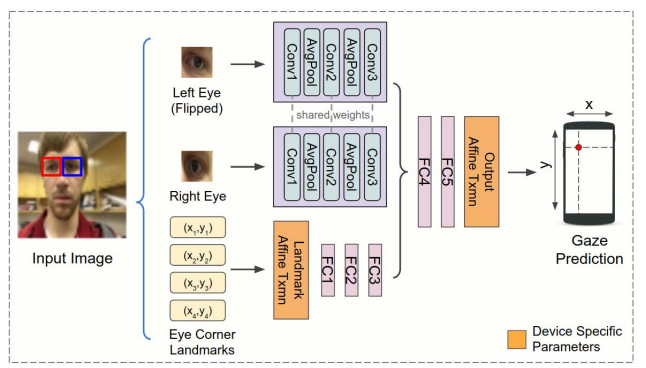
最後我們一張表格來幫大家整理這兩類方法的差異吧,+為優勢/ -為劣勢
| Geometry-based | Appearance-based |
|---|---|
| +較為精準 (如果有拿到良好精確的 3D Model ) | - 較為不精確 |
| +在各個環境調件/Domain都更為 robust (如果有成功抓準關鍵點) | - 需要解決 Domain gap |
| -需要較為清楚的照片 (為了抓取精準的的關鍵點) | + 較不需要清楚的照片 |
| -需要精準的 3D 物理模型 | + 不需要精準的 3D 物理模型 |
今天我們介紹了兩種不同類型的視線估計的方法,讓大家理解基於結構資訊來推算出來的視線以及透過大數據訓練出的基於照片直接估計模型,並且我們也比較了兩著的優缺點。歡迎明晚大家再次回來參與我們這個系列!
1.Zhang, Xucong, et al. "Appearance-based gaze estimation in the wild." Proceedings of the IEEE conference on computer vision and pattern recognition. 2015.
2.Zhang, Xucong, et al. "It's written all over your face: Full-face appearance-based gaze estimation." Proceedings of the IEEE conference on computer vision and pattern recognition workshops. 2017.
3.Cuong, Nguyen Huu, and Huynh Thai Hoang. "Eye-gaze detection with a single WebCAM based on geometry features extraction." 2010 11th International Conference on Control Automation Robotics & Vision. IEEE, 2010.
4.Dierkes, Kai, Moritz Kassner, and Andreas Bulling. "A fast approach to refraction-aware eye-model fitting and gaze prediction." Proceedings of the 11th ACM Symposium on Eye Tracking Research & Applications. 2019.
5.Martinikorena, Ion, et al. "Fast and robust ellipse detection algorithm for head-mounted eye tracking systems." Machine Vision and Applications 29 (2018): 845-860.
6.Strupczewski, Adam, et al. "Geometric Eye Gaze Tracking." VISIGRAPP (3: VISAPP). 2016.
7.Krafka, Kyle, et al. "Eye tracking for everyone." Proceedings of the IEEE conference on computer vision and pattern recognition. 2016.
8.He, Junfeng, et al. "On-device few-shot personalization for real-time gaze estimation." Proceedings of the IEEE/CVF international conference on computer vision workshops. 2019.

