Datasets 提供了一個 Dataset.set_format() 功能。此功能可以透過僅更改輸出格式的,輕鬆切換到另一種格式,而不會影響底層資料格式 (Apache Arrow)。
drug_dataset.set_format("pandas")
drug_dataset["train"][:3]

我們可以透過這種方式建立 pandas.DataFrame,再把他轉成原本的資料格式。
這裡我們目的要建立哪一天看病的人最多
train_df = drug_dataset["train"][:]
quantity = (
train_df["date"]
.value_counts()
.to_frame()
.reset_index()
.rename(columns={"index": "date", "date": "quantity"})
)
quantity.head()
train資料來做train_df["date"] 選擇train_df資料框的condition列.value_counts() 計算每天出現次數。這將產生一個包含不同條件對應其出現次數的序列.to_frame() 將產生的序列轉換為資料框,這樣就建立了一個包含兩列的資料框。一列是條件值,另一列是它們的出現次數.reset_index() 將資料框的索引重置,以便將原始的索引變為新的列.rename(columns={"index": "condition", "condition": "frequency"}) 將列的名稱更改為我們比較好理解的名稱head()的方法看前面前五個資料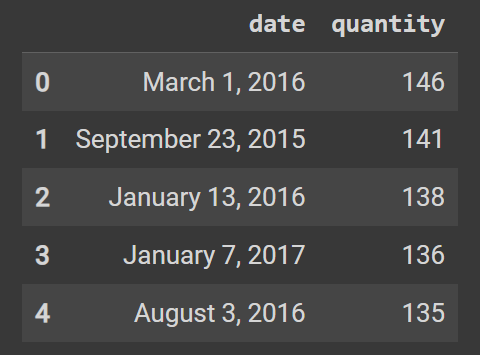
from datasets import Dataset
quan_dataset = Dataset.from_pandas(qunatity)
print(quan_dataset)
Dataset({
features: ['date', 'quantity'],
num_rows: 3579
})
drug_dataset.reset_format()
(例如,以防快取被刪除)Datasets 提供了四個主要功能來以不同的格式儲存您的資料集,前兩個主要用在大型的資料,後兩個用在中小型的資料
| 資料格式 | 對應的方法 |
|---|---|
| Arrow | Dataset.save_to_disk() |
| Parquet | Dataset.to_parquet() |
| JSON | Dataset.to_json() |
| CSV | Dataset.to_csv() |
drug_dataset_clean.save_to_disk( "my_drug" )
drug-reviews/
├── dataset_dict.json
├── test
│ ├── dataset.arrow
│ ├── dataset_info.json
│ └── state.json
├── train
│ ├── dataset.arrow
│ ├── dataset_info.json
│ ├── indices.arrow
│ └── state.json
└── validation
├── dataset.arrow
├── dataset_info.json
├── indices.arrow
└── state.json
from datasets import load_from_disk
my_drug_dataset_reloaded = load_from_disk("my_drug")
print(my_drug_dataset_reloaded)
for split, dataset in drug_dataset_clean.items():
dataset.to_json(f"my-drug-reviews-{split}.jsonl")
split和dataset,就會跑各個資料集(train、validation、test)
!head -n 1 my-drug-reviews-train.jsonl
{"patient_id":141780,"drugName":"Escitalopram","condition":"depression","review":"\"I seemed to experience the regular side effects of LEXAPRO, insomnia, low sex drive, sleepiness during the day. I am taking it at night because my doctor said if it made me tired to take it at night. I assumed it would and started out taking it at night. Strange dreams, some pleasant. I was diagnosed with fibromyalgia. Seems to be helping with the pain. Have had anxiety and depression in my family, and have tried quite a few other medications that haven't worked. Only have been on it for two weeks but feel more positive in my mind, want to accomplish more in my life. Hopefully the side effects will dwindle away, worth it to stick with it from hearing others responses. Great medication.\"","rating":9.0,"date":"May 29, 2011","usefulCount":10,"review_length":125}
data_files = {
"train": "my-drug-reviews-train.jsonl",
"validation": "my-drug-reviews-validation.jsonl",
"test": "my-drug-reviews-test.jsonl",
}
drug_dataset_reloaded = load_dataset("json", data_files=data_files)

