隨著大型語言模型(LLM)的快速發展,如何快速地將模型串接整合,成為了許多開發者面臨的挑戰。LlamaIndex 作為一個資料框架,提供了多種 LLM 接口,使開發者能夠更輕鬆地構建基於LLM的應用程序。整合了 OpenAI、LangChain、Hugging Face、Ollama、vllm 等常見部署 LLM 應用,我們只需要更改一小段程式就能無痛轉換模型,對於開發者來說非常方便。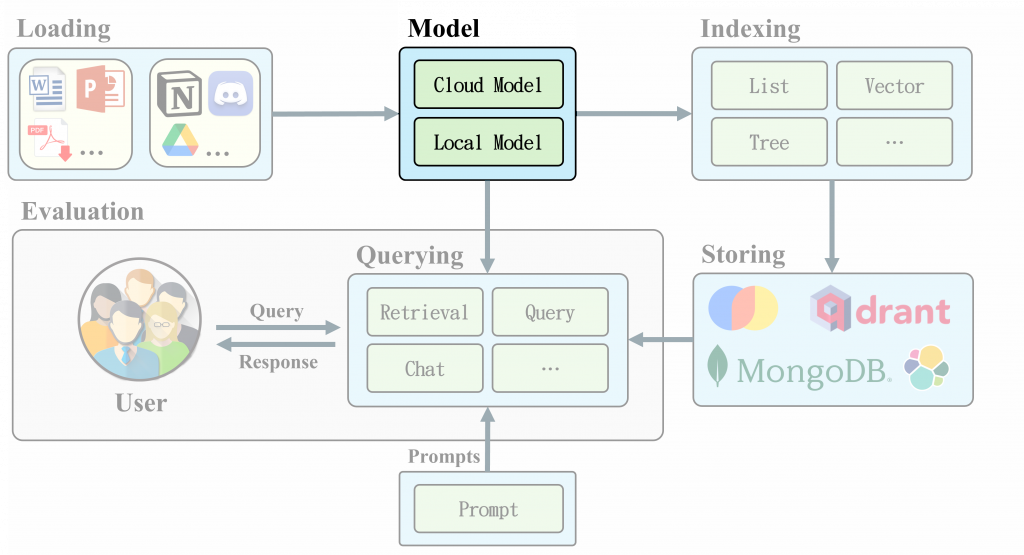
LlamaIndex 支持多種模型類型,這些模型可以根據不同的需求進行選擇:
建立 RAG 系統選擇合適的大型語言模型 (LLM) 是首要步驟之一。而 LLMs 是 LlamaIndex 的核心組成部分。 它可以用作獨立模組或結合其它模組(索引、檢索器、查詢引擎),提供快速切換模型的便利性。
OpenAI Model🔮:LlamaIndex 集成了 OpenAI 模型只需要簡單的幾行程式碼就能實現和 AI 對話。(Streaming:API 即時回覆模式,每次回傳幾個Tokens。)
安裝相關依賴:pip install llama-index-llms-openai
import os
os.environ["OPENAI_API_KEY"] = "YOUR-API-KEY"
from llama_index.llms.openai import OpenAI
# Create LLM
llm = OpenAI(model='gpt-4o-mini')
# non-streaming
completion = llm.complete("用50字介紹台灣")
print(completion)
# Output[1]: 台灣是一個美麗的島嶼,擁有豐富的文化和多樣的自然景觀。以熱情的人民、美味的美食和繁榮的科技產業聞名,台灣是東亞的重要經濟體,亦是旅遊的熱門目的地。
# using streaming endpoint
completions = llm.stream_complete("用50字介紹台灣")
for completion in completions:
print(completion.delta, end="")
Ollama🦙:Ollama 是一個開源的大型語言模型(LLM)工具,提供了快速簡易部署 LLM 的方法,同時支持多種開源 LLM 模型,如 Llama、Phi、Qwen 等。 Ollama 能在普通PC上流暢運行無需複雜配置,透過幾條簡單指令即可啟動。適合中小企業或一般個人研究使用。
下載Ollama程式並安裝,安裝完成後打開 CMD 執行 ollama 會看到以下畫面。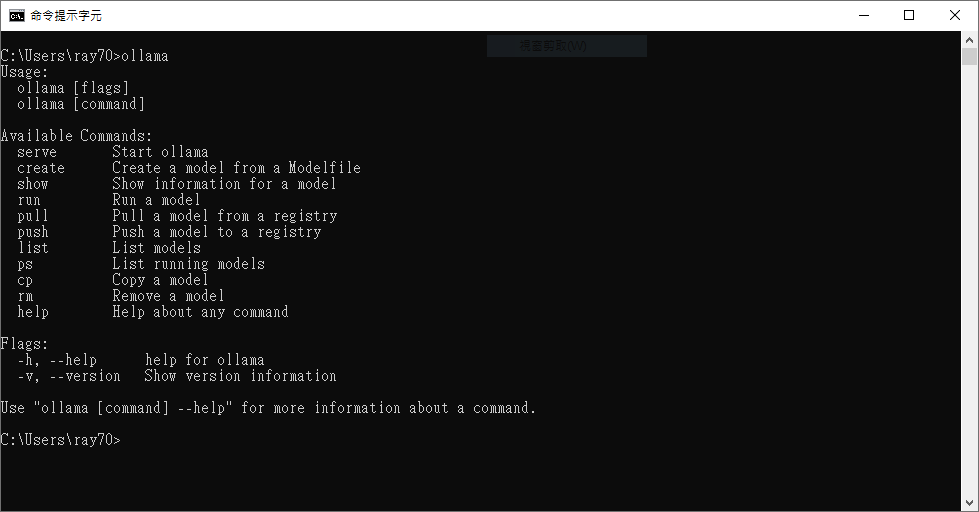
至 Ollama Models 選擇要使用的 Model ,筆者使用 Llama 3.1 示範。選擇模型後先「確認模型大小」是否能放入顯卡VRAM內,例如筆者 3060Ti(8G) 可以裝得下 4.7G 的 Llama3.1:latest,接著我們複製紅框處的語法貼製 CMD 執行。這樣就成功在自己的電腦上部署 LLM ,是不是非常簡單快速✨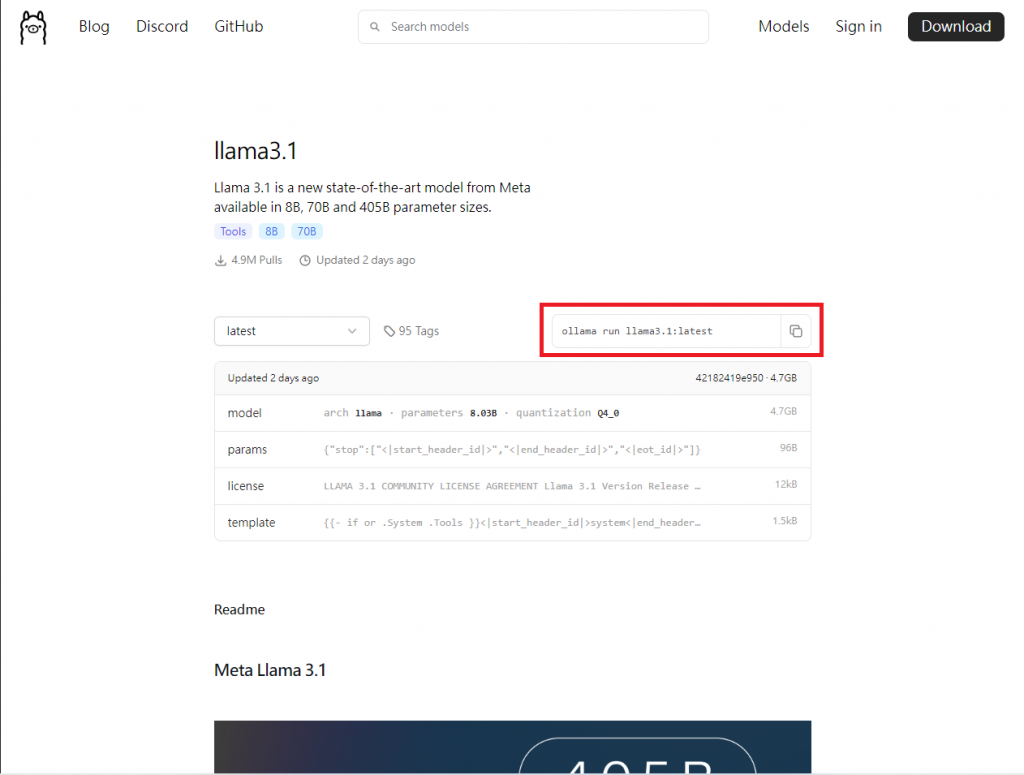
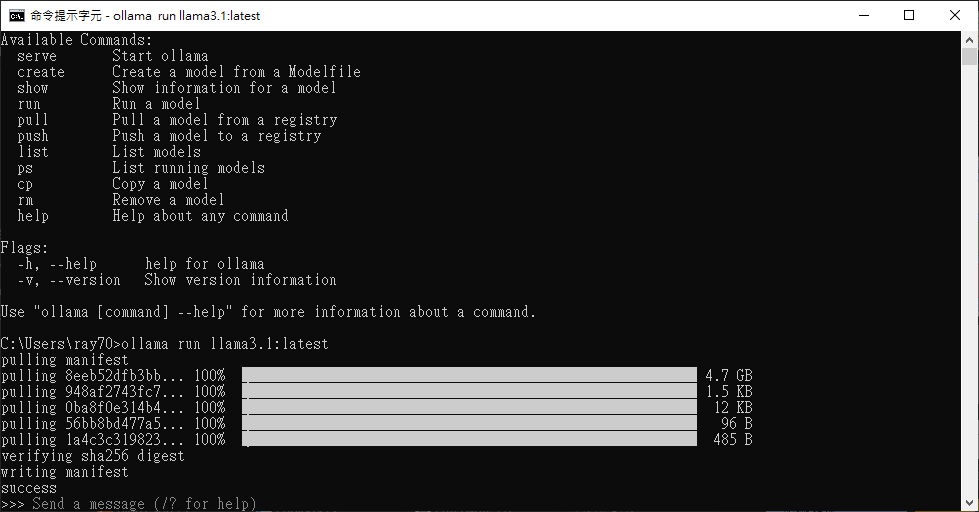
如果你不喜歡這些型號,還能點選旁邊的 Tags 選擇其它量化方式,你將會看到很多奇奇怪怪的名稱,如8b-instruct-q3_K_S。(其中8b代表參數量、instruct代表指令模型、q3代表量化至 3 bit、K則是量化方式、S代表量化後大小。)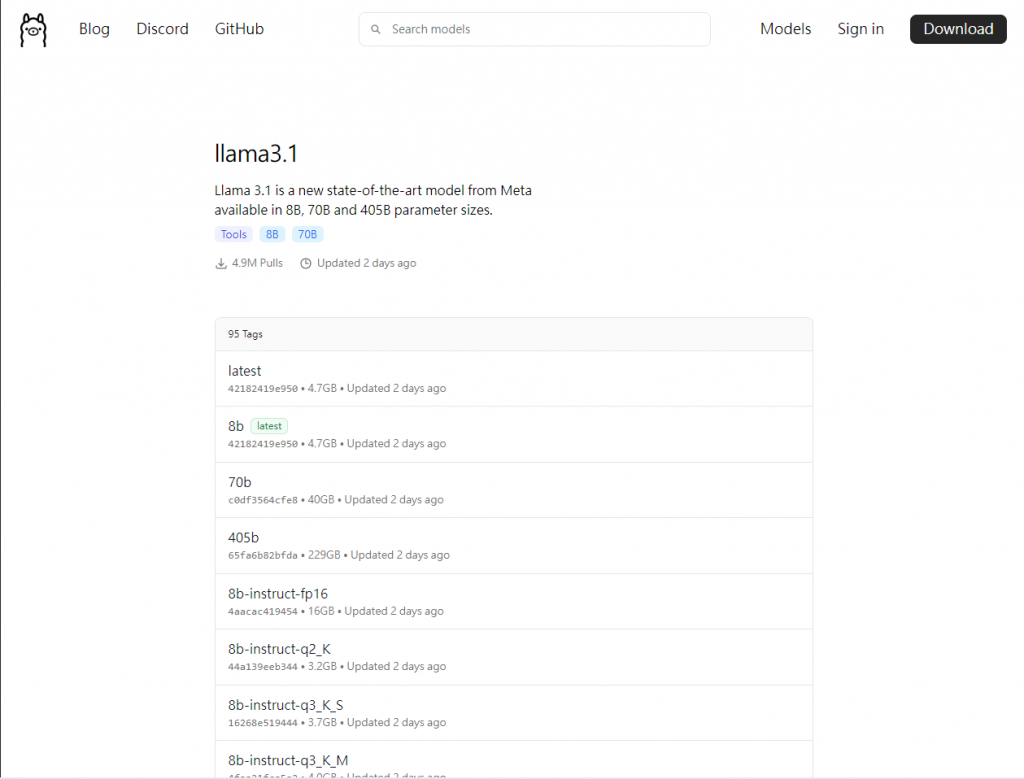
安裝 LlamaIndex 依賴 pip install llama-index-llms-ollama
執行程式碼
from llama_index.llms.ollama import Ollama
llm = Ollama(model="llama3.1:latest", request_timeout=120.0)
# non-streaming
response = llm.complete("用50字介紹台灣")
print(response)
# Output[1]: 台灣是一個美麗的島嶼,擁有豐富的地理和文化多樣性。它由於其自然奇觀、風景優雅、人文氣息濃厚而聞名。台北、新竹等地的文物古蹟以及高雄、花蓮等地的美麗風光是旅遊者的絕佳選擇。
# streaming
response = llm.stream_complete("用50字介紹台灣")
for r in response:
print(r.delta, end="")
LlamaIndex 為開發者提供了一個靈活且強大的框架,讓各類大型語言模型(LLM)可以輕鬆整合並應用於多樣化的專案中。透過簡單的程式調整,開發者無需深究各種複雜的模型部署技術,即可快速在不同的 LLM 間切換,這對於需要快速迭代、實驗不同模型的開發者來說是一大優勢。
此外,LlamaIndex 的多樣化支持包括文本生成、嵌入模型等,滿足了從對話系統到資料檢索的多種需求。像 OpenAI 和 Ollama 這些平台,則提供了即時回應和開源部署等靈活選擇,適合不同規模的專案。不論是中小企業還是個人開發者,都能透過 LlamaIndex 降低使用 LLM 的技術門檻,專注於解決實際問題,而不是困於技術細節中。接著我們將會介紹Embedding Model的使用方法,敬請期待。

