LlamaIndex Querying 功能為用戶提供了一個強大的數據檢索工具。這項功能使用戶能夠以簡單而直觀的方式查詢資料,無論是尋求具體答案還是進行更複雜的指令。Querying 的過程包括檢索、後處理和生成回覆三個主要階段,這使得用戶能夠靈活地獲取所需的資訊,並從中生成有意義的回覆。
透過 LlamaIndex🦙 ,開發者可以輕鬆構建查詢引擎,並定制檢索策略以滿足不同的需求。無論是從結構化數據還是非結構化數據中提取資訊, LlamaIndex 都能提供高效的解決方案。接下來,我們將深入探討這一功能的具體實現和應用案例,幫助讀者掌握如何利用LlamaIndex提升數據查詢的效率與準確性。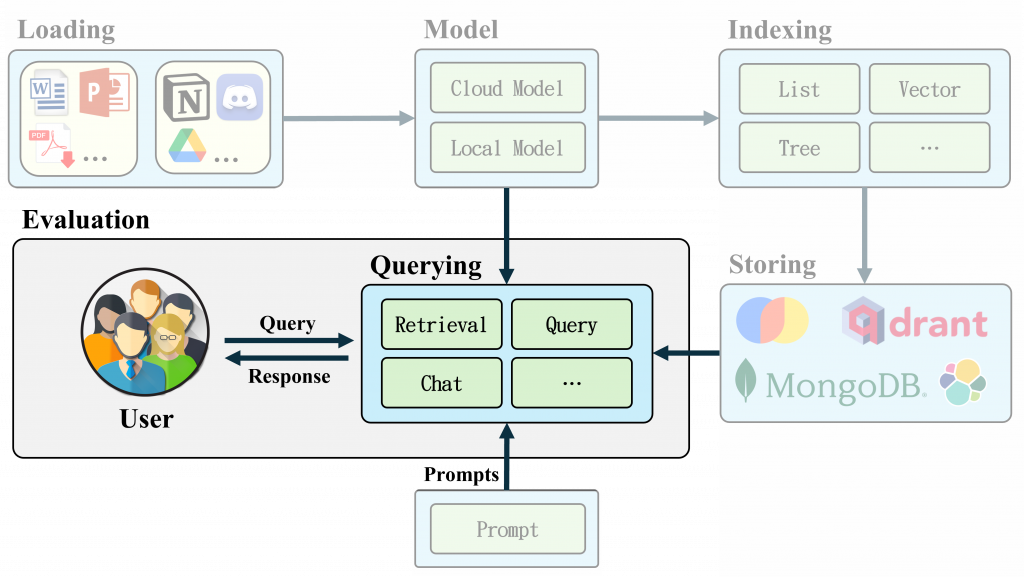
LlamaIndex 的 Querying 是查詢外部數據的核心功能。該功能允許將 LLM 的自然語言處理能力與外部數據結合,進行智能的查詢回覆。以下是 Querying 功能的主要特性:
首先要介紹的就是 RAG (Retrieval-Augmented Generation) 中的三元素,檢索(Retrieval)、強化(Augmented)、生成(Generation),分別對應 LlamaIndex 中的 Retrieval、Node Postprocessors、Response Synthesis 三大功能,接著讓我們一探究竟。
檢索器主要負責根據使用者查詢(或聊天資訊)取得最相關的上下文。
Vector Index Retriever:透過 Embedding Vector 搜尋最相似的 Top_k 個 Nodes。(similarity_top_k: 想要提取多少個相關 Nodes。)
# 建立完 Index 後增加以下 code
retriever = index.as_retriever(similarity_top_k=3)
response = retriever.retrieve("Your Query")
Keyword Table Index Retriever:首先透過 LLM 取得關鍵字,再利用 Keyword Filter 提取相似 Nodes。
# 建立完 Index 後增加以下 code
retriever = retriever = index.as_retriever(retriever_mode='default')
response = retriever.retrieve("Your Query")
BM25 Retriever:透過 BM25 演算法計算相似的 Nodes。(可惜預設沒有支援中文,但有興趣的人可以改寫原始程式。)
from llama_index.retrievers.bm25 import BM25Retriever
import Stemmer
# We can pass in the index, docstore, or list of nodes to create the retriever
bm25_retriever = BM25Retriever.from_defaults(
nodes=nodes,
similarity_top_k=2,
# Optional: We can pass in the stemmer and set the language for stopwords
# This is important for removing stopwords and stemming the query + text
# The default is english for both
stemmer=Stemmer.Stemmer("english"),
language="english",
)
retrieved_nodes = bm25_retriever.retrieve(
"Your Query"
)
Other Retriever:如對其它檢索器有興趣,LlamaIndex 提供了許多 High-Level Function 使用上非常方便。
Node Postprocessors 的主要功能是針對檢索後的 Node 進行過濾和排序,以此提升搜索精準度。
SimilarityPostprocessor:用於刪除低於相似度分數閾值的 Node。
from llama_index.core.postprocessor import SimilarityPostprocessor
# Create Documents
...
# Create Index
index = VectorStoreIndex.from_documents(documents)
# Query Engine(Filter Similarity Score)
query_engine = index.as_query_engine(
node_postprocessors=[
SimilarityPostprocessor(
similarity_cutoff=0.75
)
]
)
KeywordNodePostprocessor:用於排除或包含某些關鍵字的 Node,可以單獨使用或像上述程式碼結合 as_query_engine 一起使用。
from llama_index.core.postprocessor import KeywordNodePostprocessor
postprocessor = KeywordNodePostprocessor(
required_keywords=["word1", "word2"], exclude_keywords=["word3", "word4"]
)
postprocessor.postprocess_nodes(nodes)
MetadataReplacementPostProcessor:用於以 Node Metadata 中的欄位取代 Node 內容,簡單來說就是只檢索指定的 Metadata 內容。
from llama_index.core.postprocessor import MetadataReplacementPostProcessor
postprocessor = MetadataReplacementPostProcessor(
target_metadata_key="city",
)
postprocessor.postprocess_nodes(nodes)
CohereRerank:主要用於改善搜索引擎或問答系統的結果排序, API KEY 需透過以下連結註冊。(試用 API 免費,大量使用才需要收費。)
透過以下程式可以看出,Rerank 能有效地在檢索階段將和查詢更相關的 Node 排序到更靠前的位置,能補足 Embedding 的缺點,但相對的如果使用 Local Model 就會需要較高的運算資源。
#!pip install llama-index-postprocessor-cohere-rerank
import os
os.environ["OPENAI_API_KEY"] = "YOUR-API-KEY"
import llama_index.core
llama_index.core.set_global_handler("simple")
from llama_index.core import Document, VectorStoreIndex
# Create Documents and Index
...
# Create Query Engine
query_engine = index.as_query_engine()
res = query_engine.query("林家花園在哪個縣市?")
# Out [1]: ...
---------------------
city: 新竹
新竹被譽為「風城」,因為當地的強風而得名。它位於台灣的西北部,距離台北約一小時車程。新竹是台灣高科技產業的重要基地,特別是以竹科(新竹科學園區)而聞名,是台灣的“矽谷”。新竹擁有良好的教育環境,著名的清華大學與交通大學皆位於此地。雖然新竹給人現代化的高科技城市印象,但它同時保留了豐富的歷史文化資產,如新竹城隍廟、新竹市東門城等。當地的風味小吃,如米粉和貢丸湯,也深受遊客喜愛,是品嚐道地台灣味的好去處。
city: 台中
台中位於台灣中部,氣候溫暖,擁有台灣第三大城市的規模。它以文化氣息濃厚著稱,擁有豐富的藝術與文化活動,如國立台灣美術館、霧峰林家花園等。台中還是熱門的觀光景點之一,尤其以彩虹眷村和高美濕地最為著名。此外,台中市還以舒適的生活環境和悠閒的生活步調著稱,常被視為居住和發展的理想城市。台中的夜市文化也相當發達,逢甲夜市是其中最具代表性的夜市之一,吸引了無數美食愛好者前來品嚐台灣各地的美食
---------------------
...
# Add Reranker
from llama_index.postprocessor.cohere_rerank import CohereRerank
query_engine = index.as_query_engine(
node_postprocessors=[
CohereRerank(
top_n=2, model="rerank-multilingual-v3.0", api_key="YOUR-Cohere-KEY"
)
]
)
res = query_engine.query("林家花園在哪個縣市?")
# Out [2]:...
---------------------
city: 台中
台中位於台灣中部,氣候溫暖,擁有台灣第三大城市的規模。它以文化氣息濃厚著稱,擁有豐富的藝術與文化活動,如國立台灣美術館、霧峰林家花園等。台中還是熱門的觀光景點之一,尤其以彩虹眷村和高美濕地最為著名。此外,台中市還以舒適的生活環境和悠閒的生活步調著稱,常被視為居住和發展的理想城市。台中的夜市文化也相當發達,逢甲夜市是其中最具代表性的夜市之一,吸引了無數美食愛好者前來品嚐台灣各地的美食
city: 新竹
新竹被譽為「風城」,因為當地的強風而得名。它位於台灣的西北部,距離台北約一小時車程。新竹是台灣高科技產業的重要基地,特別是以竹科(新竹科學園區)而聞名,是台灣的“矽谷”。新竹擁有良好的教育環境,著名的清華大學與交通大學皆位於此地。雖然新竹給人現代化的高科技城市印象,但它同時保留了豐富的歷史文化資產,如新竹城隍廟、新竹市東門城等。當地的風味小吃,如米粉和貢丸湯,也深受遊客喜愛,是品嚐道地台灣味的好去處。
---------------------
SentenceTransformerRerank:可串接支援 sentence-transformer 的 Rerank 模型,快速實現用戶自行持有開源模型,不需要額外付費給 API 公司。如需結合query_engine、chat_engine可以參考上方程式碼。(如果要使用中文 Rerank 筆者建議可以使用 BGE 模型,效果很不錯。)
# pip install llama-index-embeddings-huggingface
# pip install llama-index-llms-openai
from llama_index.core.postprocessor import SentenceTransformerRerank
# We choose a model with relatively high speed and decent accuracy.
postprocessor = SentenceTransformerRerank(
model="cross-encoder/ms-marco-MiniLM-L-2-v2", top_n=3
)
postprocessor.postprocess_nodes(nodes)
Other Method: LlamaIndex 還提供了其它 AI 公司的 API 接口,如有興趣可以至官方網站查看整合方式。
Response Synthesis 提供用戶自訂 Prompt 並支持透過查詢和 Node 生成回覆,不僅增加了自定義的彈性,也簡化了自行串接 LLM 的繁瑣過程。(response_mode 在明天將會結合 query_engine 進一步詳細介紹)
from llama_index.core.data_structs import Node
from llama_index.core.response_synthesizers import ResponseMode
from llama_index.core import get_response_synthesizer
response_synthesizer = get_response_synthesizer(
response_mode=ResponseMode.COMPACT
)
response = response_synthesizer.synthesize(
"query text", nodes=[Node(text="text"), ...]
)
透過一層一層的串接可以簡單實現 RAG 架構,Documents → Embedding → Indexing → Retrievel → Node Postprocessors(Filter、Rerank) → Response Synthesis。透過以下範例能看到每一層都能幫助我們系統過濾掉不精確的 Node ,並在 Rerank 後精準找到了最相關的 Node,再透過 Response Synthesis 生成回覆。
import os
os.environ["OPENAI_API_KEY"] = " YOUR-API-KEY "
import llama_index.core
llama_index.core.set_global_handler("simple")
from llama_index.core import Document, VectorStoreIndex
# Create document
text_chunks = [
"台北是台灣的首都,也是台灣政治、經濟、文化和交通的中心。這座城市充滿了活力與多元文化,結合了現代與傳統的魅力。台北擁有世界知名的地標——台北101,它曾是全球最高的摩天大樓,並且是購物和觀光的熱門地點。此外,台北還有許多文化和歷史景點,如故宮博物院、龍山寺和中正紀念堂,吸引了大量國內外遊客。台北市內交通便捷,捷運系統發達,是探索這座都市的絕佳方式。這裡也是台灣美食的集中地,夜市文化如士林夜市、饒河街夜市更是不可錯過的體驗之一。",
"新竹被譽為「風城」,因為當地的強風而得名。它位於台灣的西北部,距離台北約一小時車程。新竹是台灣高科技產業的重要基地,特別是以竹科(新竹科學園區)而聞名,是台灣的“矽谷”。新竹擁有良好的教育環境,著名的清華大學與交通大學皆位於此地。雖然新竹給人現代化的高科技城市印象,但它同時保留了豐富的歷史文化資產,如新竹城隍廟、新竹市東門城等。當地的風味小吃,如米粉和貢丸湯,也深受遊客喜愛,是品嚐道地台灣味的好去處。",
"台中位於台灣中部,氣候溫暖,擁有台灣第三大城市的規模。它以文化氣息濃厚著稱,擁有豐富的藝術與文化活動,如國立台灣美術館、霧峰林家花園等。台中還是熱門的觀光景點之一,尤其以彩虹眷村和高美濕地最為著名。此外,台中市還以舒適的生活環境和悠閒的生活步調著稱,常被視為居住和發展的理想城市。台中的夜市文化也相當發達,逢甲夜市是其中最具代表性的夜市之一,吸引了無數美食愛好者前來品嚐台灣各地的美食",
"台南是台灣最古老的城市,也是台灣的文化和歷史重鎮,擁有豐富的歷史遺跡和古蹟。作為台灣的發源地,台南保存了大量具有歷史價值的建築物,如赤崁樓、安平古堡和延平郡王祠。這座城市還以其宗教文化著名,每年都有多場盛大的廟會活動,如媽祖遶境、五廟祭典等,吸引大量信徒參與。台南同時也是美食天堂,台南小吃如擔仔麵、碗粿和牛肉湯聞名全台。台南擁有獨特的歷史氛圍與人文風情,讓每個造訪者都能感受到濃厚的古早味。",
"高雄是台灣的南部最重要的港口城市。高雄港是世界最繁忙的貨運港之一,帶動了當地的經濟發展。高雄市內的交通便捷,擁有輕軌和捷運系統,讓市民和遊客都能方便地遊覽這座城市。高雄的著名景點包括蓮池潭、打狗英國領事館、六合夜市等,是旅遊和購物的好地方。此外,旗津半島也是高雄知名的觀光勝地,以海灘、美食和古蹟著稱。高雄擁有豐富的自然景觀和現代化的都市建設,結合了傳統與現代的多元風貌。"
]
metadata_chunks = ['台北', '新竹', '台中', '台南', '高雄']
documents = []
for i, text in enumerate(text_chunks):
doc = Document(
text=text,
id_=f"doc_id_{i}",
metadata={"city": metadata_chunks[i]})
documents.append(doc)
# Indexing
index = VectorStoreIndex.from_documents(documents)
# Query
query = "國立台灣美術館在哪裡?"
# Retriever
retriever = index.as_retriever(similarity_top_k=4)
nodes = retriever.retrieve(query)
print(f"Number of Nodes:{len(nodes)}")
print(f"Node Similarity Order:{[x.metadata['city'] for x in nodes]}")
# Out [1]:
Number of Nodes:4
Node Similarity Order:['台北', '台中', '新竹', '台南']
# Node Postprocessor
# Filter
from llama_index.core.postprocessor import SimilarityPostprocessor
processor = SimilarityPostprocessor(similarity_cutoff=0.78)
nodes = processor.postprocess_nodes(nodes)
print(f"Num of Nodes:{len(nodes)}")
print(f"Node Similarity Order:{[x.metadata['city'] for x in nodes]}")
# Out [2]:
Num of Nodes:3
Node Similarity Order:['台北', '台中', '新竹']
# Rerank
from llama_index.postprocessor.cohere_rerank import CohereRerank
reranker = CohereRerank(
model="rerank-multilingual-v3.0",
top_n=2,
api_key=" YOUR-API-KEY ",
)
nodes = reranker.postprocess_nodes(nodes, query_str=query)
print(f"Num of Nodes:{len(nodes)}")
print(f"Node Similarity Order:{[x.metadata['city'] for x in nodes]}")
# Out [3]:
Num of Nodes:2
Node Similarity Order:['台中', '台北']
# Response Synthesizer
from llama_index.core import get_response_synthesizer
response_synthesizer = get_response_synthesizer(response_mode="compact")
response = response_synthesizer.synthesize(
query, nodes=nodes
)
print(response.response)
# Out [4]: 台中
LlamaIndex 提供了一套靈活且高效的 RAG 方法,結合了檢索、後處理與生成回覆的能力,使其成為開發者實現智慧查詢系統的強大工具。無論是結構化數據還是非結構化數據,透過 LlamaIndex 使用者能夠輕鬆地構建與優化查詢策略,確保能迅速且準確地取得所需資訊。接著我們將介紹 query_engine、chat_engine 敬請期待。
請問如果是金融pdf要llm去計算財務指標
會需要用到哪個Retrieval呢
如果是很多份相似的PDF的話,我的經驗是Vector + (BM25 or Keyword)就可以在搜索部分有一定水準了,BM25、Keyword要很準確需要在斷詞、停用詞等前處理下功夫,才能提升搜索精準度。

