註:本文同步更新在Notion!(數學公式會比較好閱讀)
描述性統計(Descriptive Statistics)
描述性統計用於總結和描述數據的基本特徵。它不會進行推斷,而是關注數據的模式和趨勢,常見指標包括:
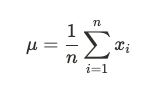
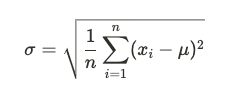
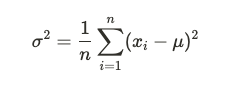
推論性統計(Inferential Statistics)
推論性統計通過從樣本數據中得出的結論來推測母體特徵。這是機器學習的核心方法之一,因為我們常常從有限的數據中訓練模型,並希望它能對未來數據進行預測。
機器學習中的許多算法都依賴於概率論。理解隨機事件和隨機變量是理解模型預測的重點。
隨機變量是與隨機實驗結果相關聯的變量,表示了可能結果的數值。
正態分佈(Normal Distribution)
許多自然現象的近似模型,其密度函數為: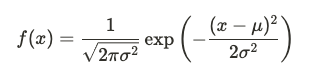
其中 µ 是均值,σ 是標準差。
假設檢驗是統計學中的一個推斷工具,用來檢驗關於母體的假設是否成立。檢驗過程包括提出零假設 H_0(通常為無效果假設)和備擇假設 H_1,並根據數據決定是否拒絕 H_0。
置信區間用來估計一個參數的區間範圍。假設我們估計某個參數的均值µ,置信區間的表達式為:
在統計學中,回歸分析用於建模變量之間的關係。線性回歸是最常用的統計模型,通過找到數據點的最佳擬合直線來預測目標變量。
線性回歸的模型表達式為:
最小二乘法是一種求解回歸問題的常用方法,其目標是最小化觀察值與預測值之間的平方誤差和: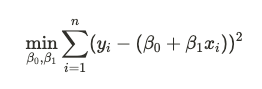

貝葉斯推理是一種更新先驗知識的工具,根據新數據來調整我們對事物的理解。這在分類問題(如 Naive Bayes 分類器)中應用廣泛。
回歸分析是監督學習中的重要技術,假設檢驗則在模型評估中扮演著關鍵角色。統計學還有助於模型的泛化,避免過度擬合,並提供如置信區間、p 值等指標來評估模型的性能。


 iThome鐵人賽
iThome鐵人賽