
在 Grafana 的官方文件中,有一篇關於 Dashboard 的最佳實踐指南,為我們提供了寶貴的建議與參考。今天,我們將專注於介紹這些最佳實踐,特別是針對 Grafana 的管理者和使用者,探討如何有效地建置和維護 Dashboard 。
隨著業務和組織規模的擴大,我們在不同場景中會遇到各種挑戰,Grafana Dashboard 可能變得越來越難以管理。隨著使用者的增長, Dashboard 的數量和複雜度也會隨之增加,如果缺乏有效的管理,這些 Dashboard 很容易變成一片混亂,帶來難以控制的風險。因此,建立一套成熟的實踐標準,作為 Dashboard 管理的依據,變得尤為重要。接下來,我們將結合這篇最佳實踐指南和實務經驗,從各個角度深入探討這些理論。
當我們剛開始接觸 Grafana 時,可能對於各種功能和面板的運用並不熟悉,也不太了解如何規劃和管理這些功能,更不用說那些涉及專業監控指標和統計概念的見解了。然而,Grafana 提供了一個非常強大的平台,讓我們能夠站在巨人的肩膀上,學習和搭建我們自己的可觀測性應用服務。
首先,Grafana 提供了豐富的開源 Dashboard 資源,讓每個使用者都可以輕鬆導入現成的 Dashboard,並根據自身需求進行定制。這些 Dashboard 是由社群和專家分享的開箱即用的工具,可以極大地幫助我們快速上手。
此外,Grafana 官方部落格中經常分享與合作夥伴的成功案例,這些案例展示了如何實踐和發展最佳實踐。我們可以通過這些成功的實例,汲取寶貴經驗,提升自己在監控和應用服務上的能力。
如果我們對於搭建 Grafana 還感到不熟悉,也不必擔心。Grafana 官方還提供了一個無需登錄的沙盒環境,稱為 Grafana Playground。在這裡,我們可以自由探索和實驗,從中學習如何更好地利用 Grafana。
這些資源,包括現成的 Dashboard、成功案例的參考,以及 Grafana Playground,都為我們提供了豐富的學習機會,讓我們能夠在短時間內掌握 Grafana 的使用技巧,並運用到實際的監控和應用服務中。
在先前的章節中,我們已經討論過 USE 和 RED 等可觀測性策略,這些策略也是 Grafana 官方強烈推薦的組合應用方式。其中,RED 指標特別適合用來設定告警和 SLA(服務水平協議)。舉例來說,當我們的 SLA 或告警透過 RED Dashboard 被觸發時,我們可以立即察覺到使用者體驗可能受到了影響。
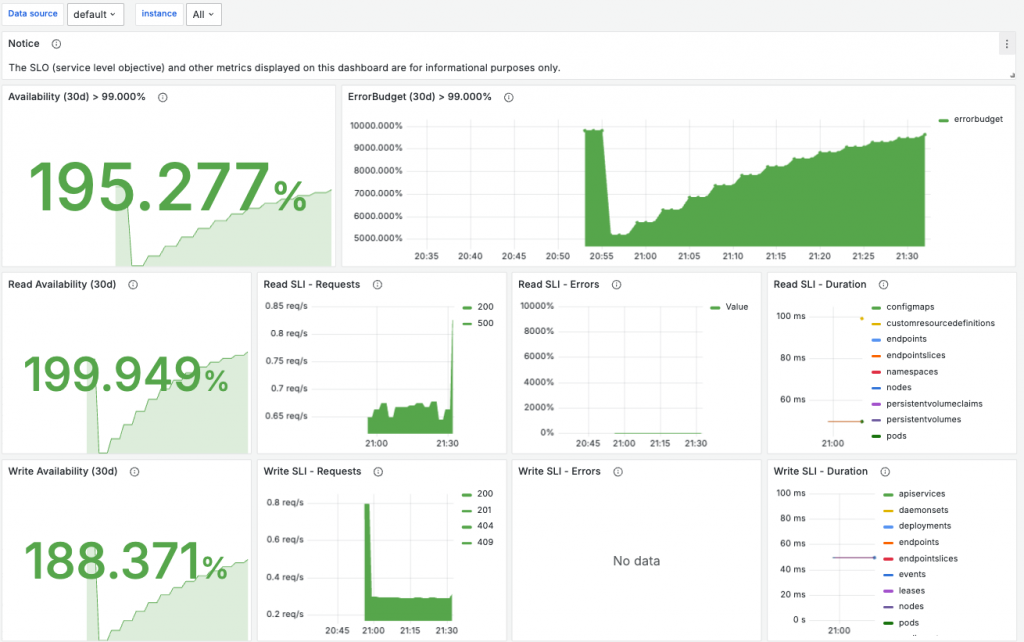
這時我們可以從最前端的請求進入點開始深入排查,找出是哪個服務或是哪台機器出現了 CPU/Memory 使用率異常,也就是我們之前提到的 USE 方法的價值所在。它不僅能夠幫助我們有效設計 Dashboard,還能將告警和排錯的流程變得更加簡潔和高效,提升工作效率。這樣一來,我們不會在問題發生時,手忙腳亂地在混亂的 Dashboard 中尋找解決問題的救命稻草,而是能夠迅速、精確地定位並解決問題。
Grafana 官方文件中,提供了我們一套 Dashboard 管理成熟度模型,其旨在評估和提升 Dashboard 設計和使用的有效性,確保 Dashboard 在監控和管理過程中發揮最佳效用。從廣義上來看,Dashboard 成熟度可以分為三個層次:低、中、高。
在這個階段,Dashboard 管理缺乏連貫性和策略,大多數人都從這裡開始。Dashboard 的設計與使用較為隨意,通常缺乏有效的管理和結構。
特徵:
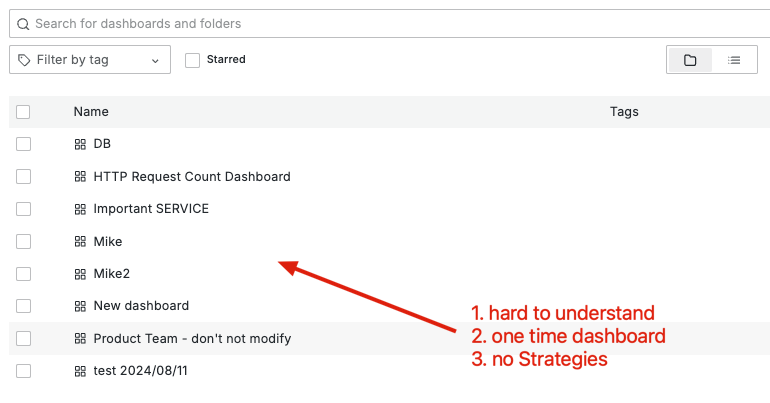
要遵循的最佳實踐:
在這個階段, Dashboard 管理開始有序,逐漸形成策略並進行優化,但仍有進步空間。你已經意識到 Dashboard 設計的結構性,並開始實施一些基礎的管理策略。
特徵:
要遵循的最佳實踐:
在這個階段,通過一致且周到的策略,Dashboard 管理已經達到了優化的使用狀態。Dashboard 的設計和管理已經成熟,並且需要定期維護來保持這一水準。
特徵:
要遵循的最佳實踐:
通過這樣的管理成熟度模型,讓我們可以逐步提升 Dashboard 的管理和使用效能,才能夠提供更高效的監控解決方案。
在我們建立 Grafana Dashboard 之前,遵循以下最佳實踐可以幫助我們創建更有效的監控。
在設計 Dashboard 時,我們首先要問自己,這個 Dashboard 想要講述什麼故事或回答什麼問題。嘗試建立資料的邏輯顆粒細度,例如從大到小,或從一般到特定。如果發現 Dashboard 沒有明確的目標,可能需要重新考慮它的必要性。
此外,保持 Pannel 的簡潔,專注於回答具體問題。例如,當你的問題是「哪些伺服器出了問題?」時,只需顯示遇到問題的伺服器數據,而非所有伺服器的數據。
Dashboard 應該減少使用者的認知負擔,而不是增加困惑。確保 Dashboard 易於理解,這對未來的你或其他使用者尤為重要。你可以自問:
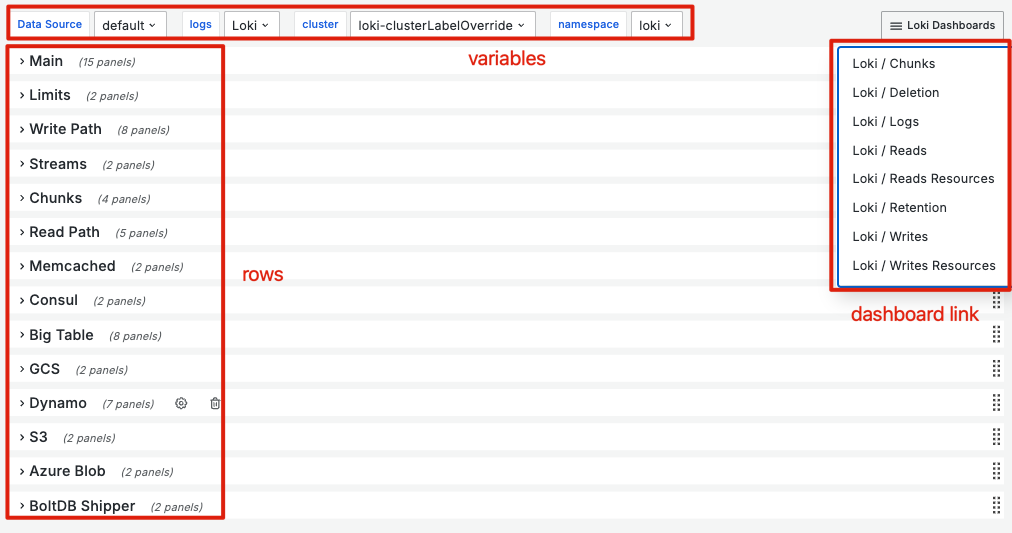
在 Grafana 中,通過良好的命名習慣並合理切分 Folder 和設置權限,能夠顯著提升 Dashboard 的管理效率。這不僅僅是為了保持整潔,更是為了在長期運營中,能夠快速定位和查找所需資源。為了達到這一目標,我們必須確保所有命名都是具有明確意義的,這樣可以在使用 Label、Tag、Dashboard 和 Folder 進行分類和交叉查找時提供巨大的幫助。
具體來說,我們可以將一些常見的元素在每個 Grafana 資源中進行抽象和標準化,例如:
通過這樣的命名和分類策略,我們可以在管理層面上實現高效、有序的資源調配和監控,減少在查找和維護時的困難,從而提升整體運營效率。
在 Dashboard 中查詢 Data Source 儲存後端時,其實與我們在應用服務中查詢資料庫的行為並無太大差別。任何不當的查詢都可能導致效能下降與資源浪費,尤其當這些查詢規模一大,將會對儲存後端造成巨大的壓力。這不僅會影響系統的整體效能,還可能導致查詢的結果變得不夠及時或準確。
以一個常見的情境為例:我們想要查看某個 API 請求的反應時間。初學者可能會直接使用以下查詢語句來檢索數據:
service_http_request_response_time{} # last 7 days
這個查詢會對所有 API 路徑在過去七天內的所有結果進行檢索。然而,這樣的查詢很容易導致過多的數據檢索,浪費大量的資源和時間,並且最終的結果可能包含了許多我們並不關心的數據。
更好的方法是根據具體需求進一步優化查詢,例如我們實際上可能只關心某些特定請求和相對較短時間範圍內的數據。優化後的查詢語句可能會像這樣:
service_http_request_response_time{service="auth", path="/login"} # last 6 hours
在這個優化後的查詢中,我們將查詢語句進一步鎖定了特定的 service 和 path,並且將時間範圍縮短至過去六個小時。這樣不僅大大減輕了儲存後端的查詢壓力,還使得查詢結果更加貼近實際應用需求,更容易得到我們真正關心的數據。
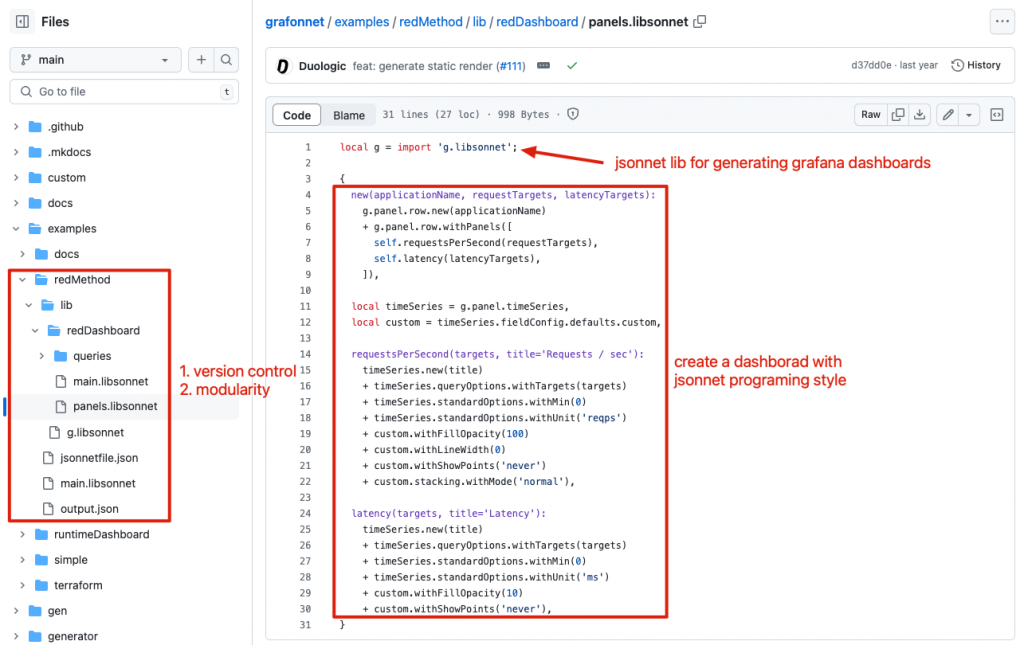
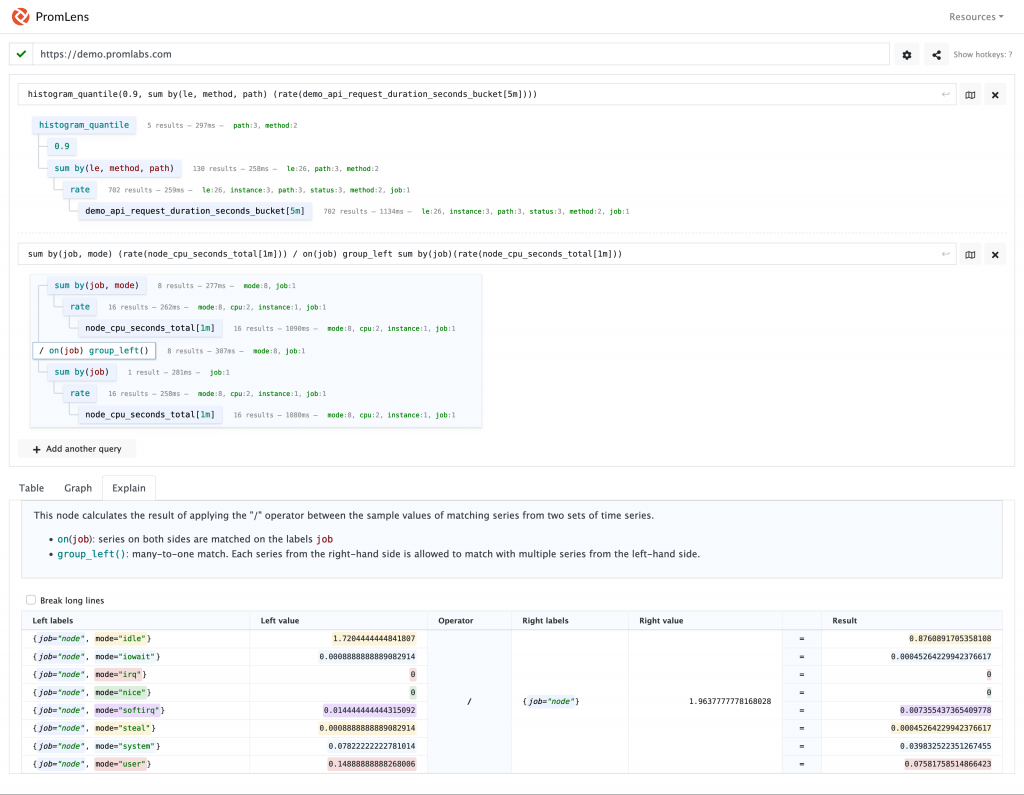
以下是使用 Metrics 語法優化工具 PromLens 來分析並提高我們查詢語句效率的範例。在 Grafana 使用中,執行合理的查詢語法是至關重要的,這不僅可以確保數據檢索的準確性,還能避免對我們的資料源後端造成過大的壓力。PromLens 這類工具能幫助我們可視化和逐步優化 Prometheus 查詢,識別不必要的計算和數據提取,從而改善整體效能。
在本章節中,我們已經對官方提供的最佳實踐有了初步了解,這讓我們深刻體會到使用與管理 Grafana Dashboard 之間的難度差異。僅僅會使用 Grafana Dashboard 是遠遠不夠的,真正的挑戰在於如何有效地管理這些 Dashboard 。這不僅涉及到如何合理地使用軟體領域中的抽象概念,還包括如何管理設定檔、遵循命名規範、進行定期審查,以及考量系統效能等多方面的議題。
這些都是我們身為軟體工程師在職涯中不斷追求精進的目標——如何以最有效率的方式解決複雜的問題。正因如此,這些最佳實踐不僅適用於 DevOps 和 SRE 人員,更值得每一位立志成為優秀工程師的人深入學習和精進。透過掌握這些管理技巧,我們不僅能提升工作效率,也能為團隊帶來更大的價值。
Reference:

