前面講完linux的vLLM安裝使用,這次來介紹Windows版本的使用方式,筆者之前剛好借到一台windows電腦+RTX 4060 Ti * 2,就用這台從0開始設定。如果是CPU,這邊補充昨天分享過的教學連結。
因為圖片很多,往下滑之後可能不會想再往上滑,所以先放章節大綱:
- ⚙️ 安裝 Docker Desktop
- 🐳 pull vLLM image
- 📦 啟用 docker 容器
- 💻 在 Windows 電腦做 vLLM 測試
- ⏸️ 停止 docker 容器
從此github issue看到,目前在vLLM可以跑的方法是使用Docker Desktop!

(圖源: reddit,下面留言好讚喔)
安裝是可以基於Hyper-V或WSL,如果要確認Hyper-V有沒有打開,可以從 Windows PowerShell (管理員) 下以下的指令:
Get-WindowsOptionalFeature -Online -FeatureName Microsoft-Hyper-V-All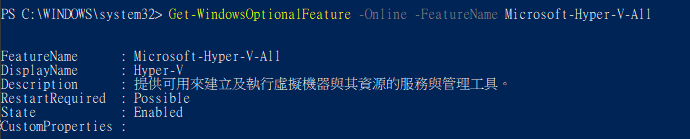
如果State顯示為Disabled,代表Hyper-V未啟用。
這時按下Win + R,輸入optionalfeatures,然後按Enter。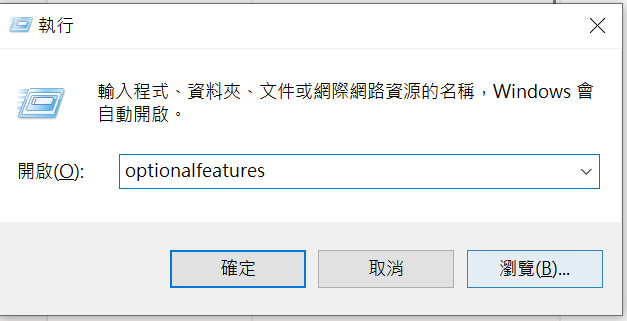
把Hyper-V都打勾,然後重新開機,再確定一次有沒有啟用。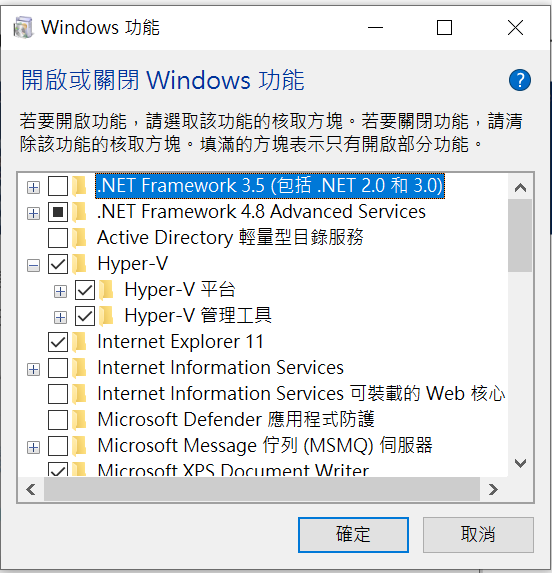
之後再安裝Docker Desktop,理論上應該就可以直接執行了。
(如果有特定的帳號,就需要將user加入至docker_group)
接下來打開cmd,然後看看dockerhub上vllm官方的image,沒意外的話就是選最新的。
docker pull vllm/vllm-openai:latest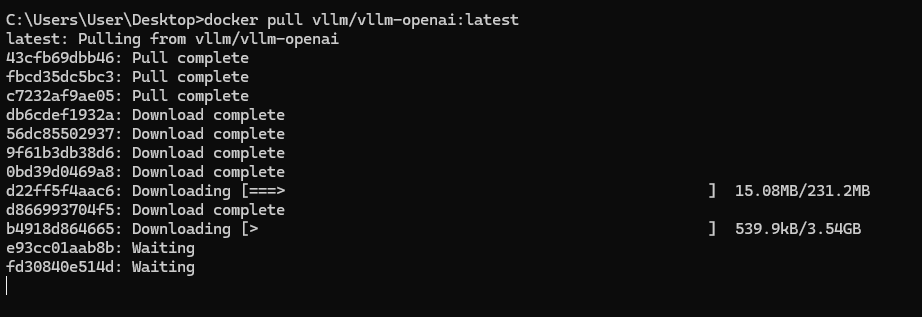
中間可能需要等待一下。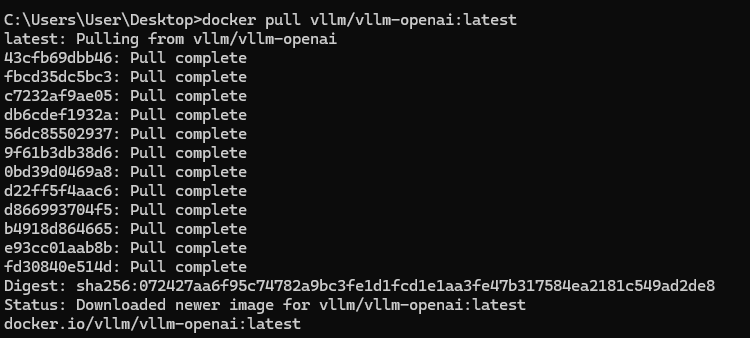
pull完之後就可以在Docker Desktop中看到image了。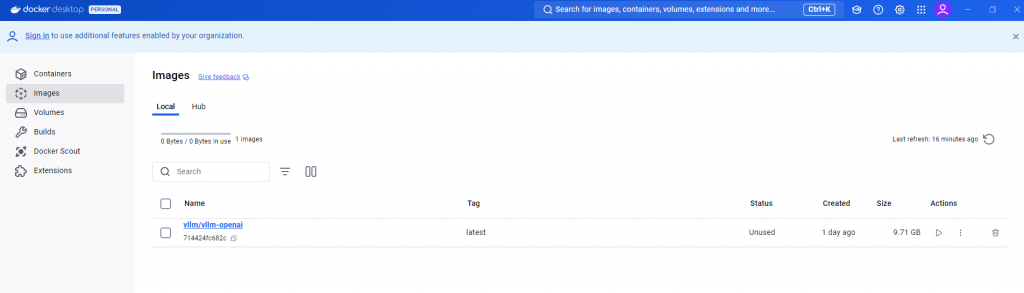
接下來同樣打開cmd,指令可以從vllm官方文件 看到。
docker run --gpus all -p 8001:8000 --ipc=host vllm/vllm-openai:latest --model yentinglin/Llama-3-Taiwan-8B-Instruct
8001:8000代表windows電腦的8001 port對應到docker中的8000 port。
如果模型有需要的話,可以在前面加上--env "HUGGING_FACE_HUB_TOKEN=<secret>"。同樣的,後面也可以加上一些前面學過的參數,因為VRAM只有16GB * 2,這邊是加上了--pipeline-parallel-size 2,分散了模型的參數量到2個GPU上。
可以從docker點進去容器的logs看,主要下載模型會需要一段時間,這邊大概是花了半小時才完成下載,因為先前沒有幫容器命名,所以現在是一個奇特的隨機名稱。
如果想要改名請用docker rename [old name] [new name],或是一開始就加上--name [name]。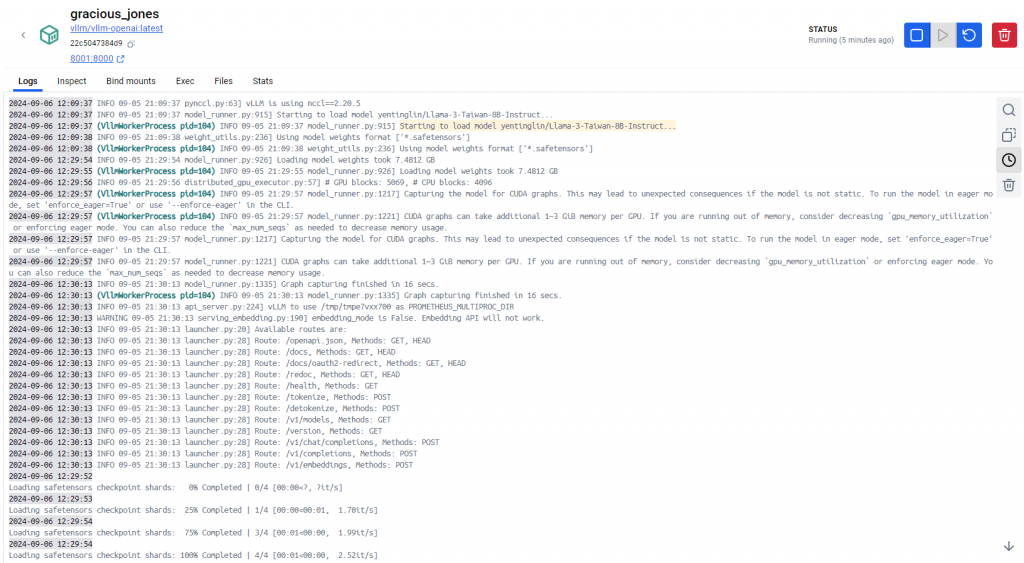
等看到熟悉的Uvicorn running就完成啦。
看一下nvidia-smi,有成功載入了。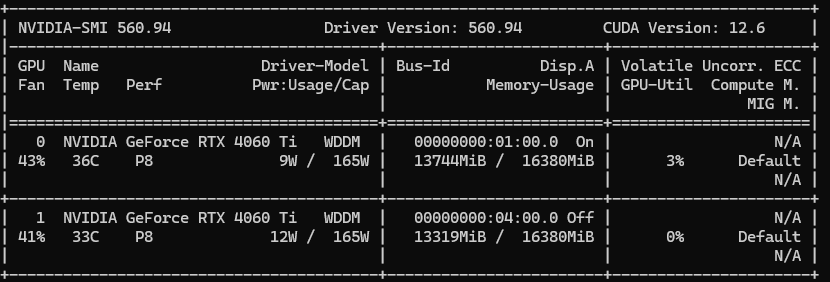
前面幾天的測試都是用python call API,這次則是在cmd簡單curl看看!
(cmd的curl方法稍微不同,需要用以下格式)
curl http://localhost:8001/v1/models
curl -X POST http://localhost:8001/v1/completions -H "Content-Type: application/json" -d "{\"model\": \"yentinglin/Llama-3-Taiwan-8B-Instruct\", \"prompt\": \"嗨嗨你是誰\", \"temperature\": 0}"
上面是文字接龍的版本,下面是一般chat的版本。
curl -X POST http://localhost:8001/v1/chat/completions -H "Content-Type: application/json" -d "{\"model\": \"yentinglin/Llama-3-Taiwan-8B-Instruct\", \"messages\": [{\"role\": \"system\", \"content\": \"zh-tw. You are a helpful assistant.\"}, {\"role\": \"user\", \"content\": \"你喜歡吃蘋果派嗎?\"}], \"top_p\": 0.9, \"temperature\": 0.1}"
這邊可能會看到
"finish_reason":"stop","stop_reason":128009
至於"stop_reason":128009是什麼,從這個issue的討論來看,其實llama3的EOS token id就是128009。
其他使用方式如OpenAI API、FastAPI docs、接gradio介面聊天就如同前面幾天教過的樣子,就不再重複提了。
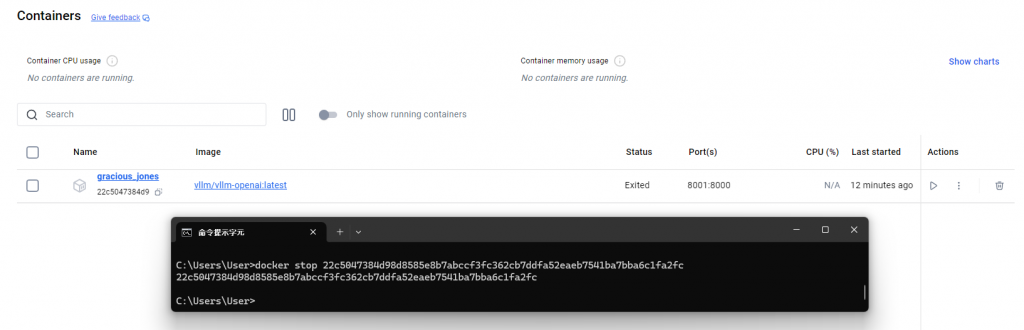
如果沒有停止docker容器的話,就會繼續卡著VRAM不放,在玩完之後要記得做docker stop Container_ID,確認VRAM有被釋放掉。
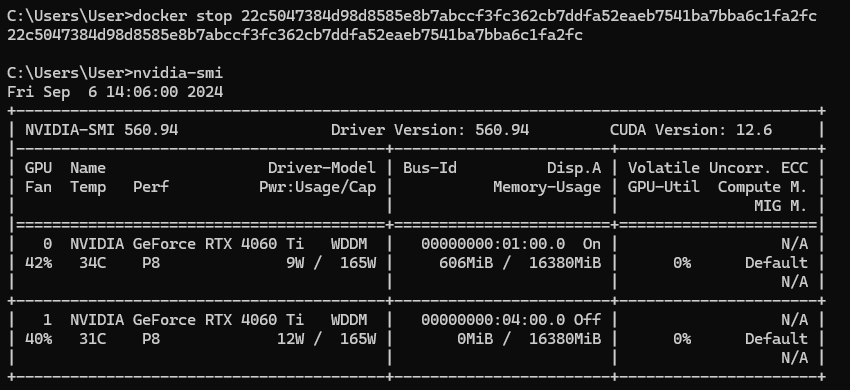
最後再次檢查nvidia-smi,資源有成功被釋放掉了。
補充,如果想要完全停止每次開機都會跳出來的Docker Desktop,右下角icon區,找到docker的鯨魚,就可以右鍵quit它囉。
這章節如果有docker和前面一般使用過vLLM的基礎在,用起來就是非常簡單愉快,只需要等待模型下載的時間,就可以無痛體驗推理加速的感覺。
另外筆者發現,寫實作應用篇真的是超級簡單暴力,不用再看很多文獻慢慢消化內容,這是目前寫起來最快速的一天,接下來最後的最後要繼續探討infra相關的知識! ✨

(圖源: securityboulevard)


 iThome鐵人賽
iThome鐵人賽