第24天了!最後就在官方文件裡面撈看看還有什麼可以玩的。 ✨
首先是安裝方式,除了之前試過的linux GPU版本安裝之外,官方文件還提供了linux CPU版本的安裝方式。 💻 Medium這篇相關教學就是在教怎麼使用Dockerfile在CPU環境使用llama3-8b作為OpenAI-Compatible Server。 🌐
在來就是很多範例教學,包含了LLM的推理和應用開發,像是API Client和OpenAI Client、AQLM壓縮模型使用的範例。 📚 此外,這些範例也包含了Gradio Webserver,展示如何建立網頁介面,串接vLLM! 🚀 還有Offline Inference系列,提供離線推理的方式,並支持分散式推理和特殊硬體的推理應用。 ⚙️
最後就是多台機器可部屬的方式:Kubernetes、Helm、Nginx Loadbalancer
如果筆者有資源,真想玩看看QQ
🔍 今天就來看一下:
- FastAPI docs 📖
- Tokenize ✂️
- Embedding model 📊
- Gradio OpenAI Chatbot Webserver 🤖
- Chunked Prefill 與 batch size調整 🛠️

(圖源: threads)
在啟動vLLM時,其實在log中可以看到有很多API可以使用。
而這些可以在(預設) http://localhost:8000/docs#/ 查看FastAPI的swagger界面。
WARNING 08-12 11:26:16 serving_embedding.py:171] embedding_mode is False. Embedding API will not work.
INFO 08-12 11:26:16 launcher.py:14] Available routes are:
INFO 08-12 11:26:16 launcher.py:22] Route: /openapi.json, Methods: GET, HEAD
INFO 08-12 11:26:16 launcher.py:22] Route: /docs, Methods: GET, HEAD
INFO 08-12 11:26:16 launcher.py:22] Route: /docs/oauth2-redirect, Methods: GET, HEAD
INFO 08-12 11:26:16 launcher.py:22] Route: /redoc, Methods: GET, HEAD
INFO 08-12 11:26:16 launcher.py:22] Route: /health, Methods: GET
INFO 08-12 11:26:16 launcher.py:22] Route: /tokenize, Methods: POST
INFO 08-12 11:26:16 launcher.py:22] Route: /detokenize, Methods: POST
INFO 08-12 11:26:16 launcher.py:22] Route: /v1/models, Methods: GET
INFO 08-12 11:26:16 launcher.py:22] Route: /version, Methods: GET
INFO 08-12 11:26:16 launcher.py:22] Route: /v1/chat/completions, Methods: POST
INFO 08-12 11:26:16 launcher.py:22] Route: /v1/completions, Methods: POST
INFO 08-12 11:26:16 launcher.py:22] Route: /v1/embeddings, Methods: POST

在這之中除了chat之外會用到的應該是tokenize,可以計算input tokens的數量。
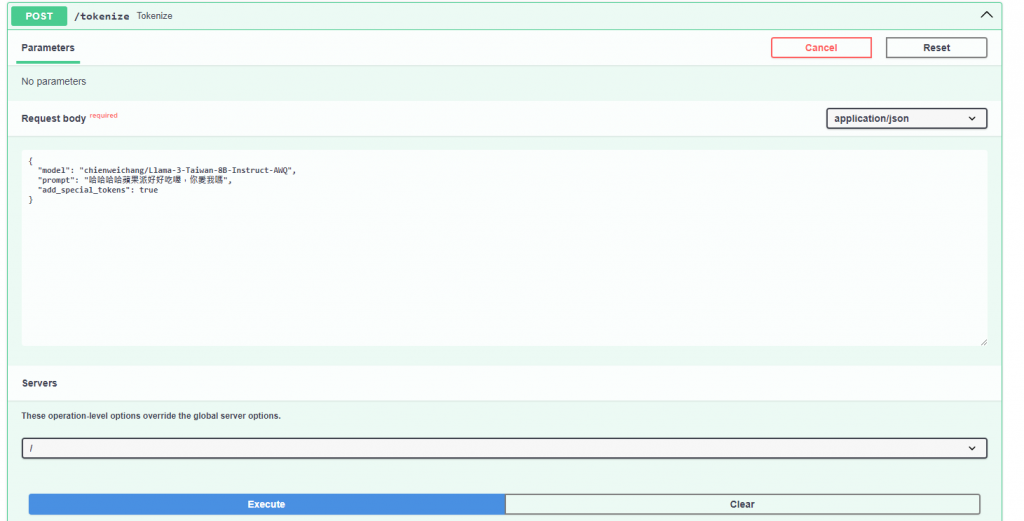
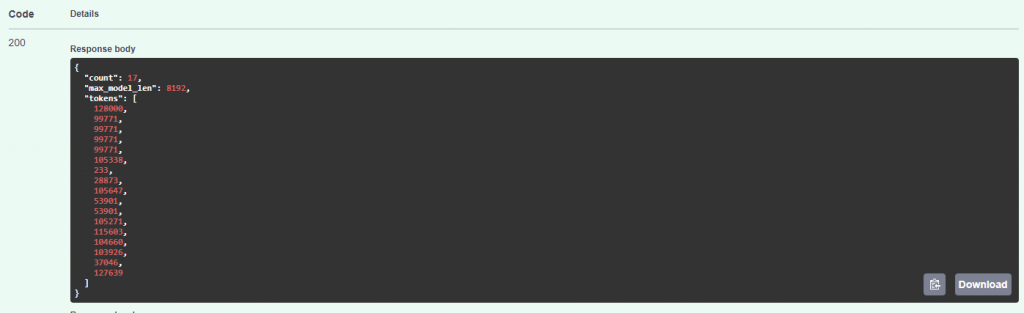
至於embedding model的部分,大家常用的一些中文embedding模型,像是BAAI/bge-small-zh-v1.5,原本在筆者寫30天的2024/9這段時間,vLLM還不支援基於BertModel這樣的embedding模型,當時它只支援Causal Language Models(生成型模型)。
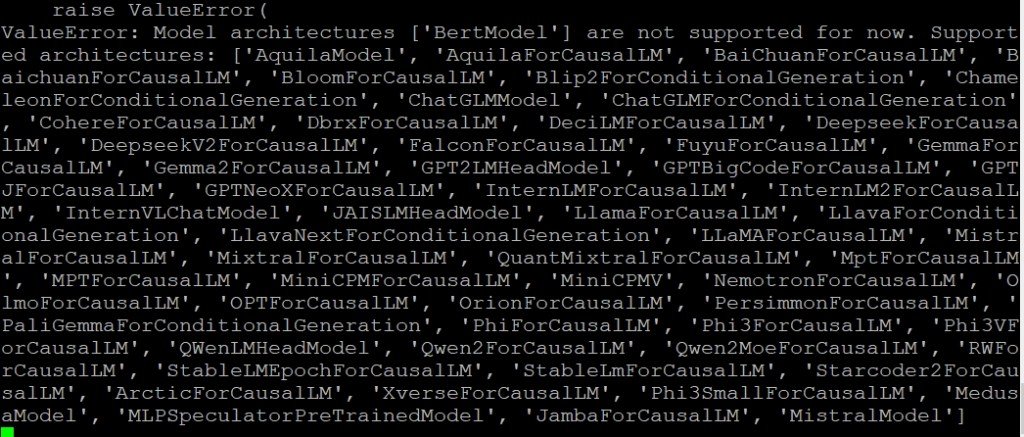
從當時Github這個兩個issuse可以看到,目前vLLM仍專心在autoregressive generation,現在他們還是推薦使用其他libraries來做embedding,也許在未來會再深入開發這個功能。
three months later......
2024/12補充:
現在 Pooling Models 都支援了!! 所謂的Pooling Models包含了embedding, reranking 和 reward models,是在做RAG應用時的重點!只能說他們更新真的是有夠快的OAO
(如果筆者之後還有做什麼新的實驗和截圖再補上來。)
參考官方文件的範例程式碼,要記得pip install gradio,超簡單三步驟開啟你的對話介面!
'http://localhost:8000/v1'改成你的portimport argparse
import gradio as gr
from openai import OpenAI
# Argument parser setup
parser = argparse.ArgumentParser(
description='Chatbot Interface with Customizable Parameters')
parser.add_argument('--model-url',
type=str,
default='http://localhost:8000/v1',
help='Model URL')
parser.add_argument('-m',
'--model',
type=str,
required=True,
help='Model name for the chatbot')
parser.add_argument('--temp',
type=float,
default=0.8,
help='Temperature for text generation')
parser.add_argument('--stop-token-ids',
type=str,
default='',
help='Comma-separated stop token IDs')
parser.add_argument("--host", type=str, default=None)
parser.add_argument("--port", type=int, default=8001)
# Parse the arguments
args = parser.parse_args()
# Set OpenAI's API key and API base to use vLLM's API server.
openai_api_key = "EMPTY"
openai_api_base = args.model_url
# Create an OpenAI client to interact with the API server
client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
)
def predict(message, history):
# Convert chat history to OpenAI format
history_openai_format = [{
"role": "system",
"content": "You are a great ai assistant."
}]
for human, assistant in history:
history_openai_format.append({"role": "user", "content": human})
history_openai_format.append({
"role": "assistant",
"content": assistant
})
history_openai_format.append({"role": "user", "content": message})
# Create a chat completion request and send it to the API server
stream = client.chat.completions.create(
model=args.model, # Model name to use
messages=history_openai_format, # Chat history
temperature=args.temp, # Temperature for text generation
stream=True, # Stream response
extra_body={
'repetition_penalty':
1,
'stop_token_ids': [
int(id.strip()) for id in args.stop_token_ids.split(',')
if id.strip()
] if args.stop_token_ids else []
})
# Read and return generated text from response stream
partial_message = ""
for chunk in stream:
partial_message += (chunk.choices[0].delta.content or "")
yield partial_message
# Create and launch a chat interface with Gradio
gr.ChatInterface(predict).queue().launch(server_name=args.host,
server_port=args.port,
share=True)
當然這一段如果要用真正的OpenAI API也是可以的。

這時會出現 Running on local URL: http://127.0.0.1:8001
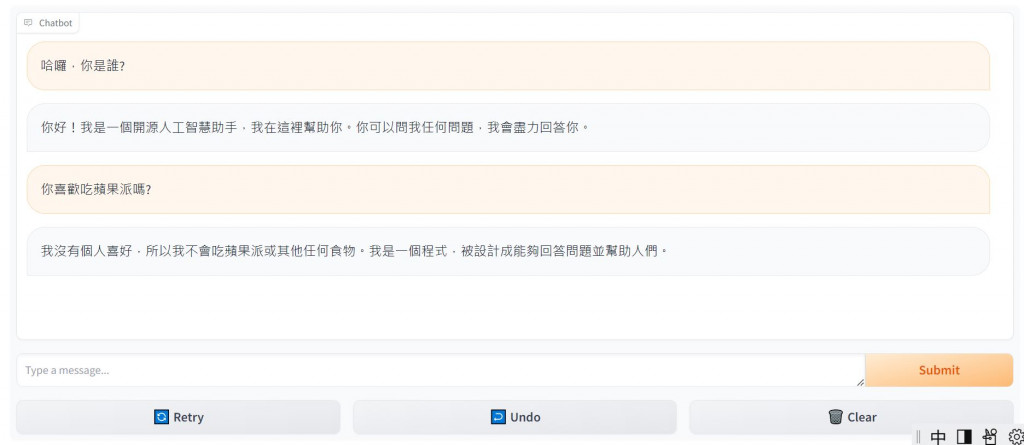
打開下面的gradio網址,就可以快樂地跟模型聊天了! 💬
max_num_batched_tokens 和 max_num_seqs,來共同決定max batch size。今天簡單介紹了vLLM背後的FastAPI以及它Embedding model的限制,最後用它的範例做了一個Gradio對話介面 💬。筆者最後翻了一下,值得一提的是監控的部分 📊,不過這個筆者還沒研究完,預計在後續的監控章節中繼續探討。 🔍
明天就是實作篇的最後一天啦,這幾天都是用linux系統 🐧,接下來就來介紹一下windows版本的安裝! 💻✨

(圖源: x)

