我們繼上一篇討論以下功能:
ChatGPT也可以幫程式設計師抓臭蟲,對於初入門者非常有幫助。
範例1. 程式除錯。
debug the following code:
for i in range(10):
a = random.randint(1,12)
b = random.randint(1,12)
question = "What is "+a+" x "+b+"? "
answer = input(question)
if answer = a*b
print (Well done!)
else:
print("No.")
1. random模組未引入(random module is not imported)。
2. 字串格式化(String formatting)錯誤。
3. 比較符號(Comparison operator)錯誤。
4. 缺少分號(Missing colon)。
5. 輸入未轉換(Conversion of user input)。
python debug_test.py
What is 2 x 4? 6
No.
What is 9 x 12? 108
Well done!
What is 6 x 9? 54
Well done!
前幾篇討論了單元測試、TDD,我們必須提供較多的案例,驗證的覆蓋率才會比較高,程式品質才能確保,但是,撰寫測試案例很花時間,程式設計師通常都懶得作,這時ChatGPT就可派上用場了。
範例2. 測試案例生成。
generate test cases for the following code:
import random, math
for i in range(10):
a = random.randint(1, 12)
b = random.randint(1, 12)
question = "What is " + str(a) + " / " + str(b) + "? "
answer = int(input(question))
if math.floor(answer) == math.floor(a /b):
print("Well done!")
else:
print("No.")

ChatGPT可以衡量演算法或程式的效能,作為效能改善的參考。
範例3. 衡量排序演算法的效能。
provide code for bubble sort
def bubble_sort(arr):
n = len(arr)
# Traverse through all array elements
for i in range(n):
swapped = False
# Last i elements are already sorted
for j in range(0, n-i-1):
# Swap if the element found is greater than the next element
if arr[j] > arr[j+1]:
arr[j], arr[j+1] = arr[j+1], arr[j]
swapped = True
# If no two elements were swapped by inner loop, then the list is sorted
if not swapped:
break
# Example usage
arr = [64, 34, 25, 12, 22, 11, 90]
print("Original array:", arr)
bubble_sort(arr)
print("Sorted array:", arr)
calculate its time complexity
provide code for quick sort
def quick_sort(arr):
# Base case: arrays with 1 or 0 elements are already sorted
if len(arr) <= 1:
return arr
# Choose a pivot (here, the last element of the array)
pivot = arr[len(arr) - 1]
# Partition the array into two sub-arrays
left = [x for x in arr[:-1] if x <= pivot] # Elements less than or equal to the pivot
right = [x for x in arr[:-1] if x > pivot] # Elements greater than the pivot
# Recursively apply quicksort to the left and right sub-arrays
return quick_sort(left) + [pivot] + quick_sort(right)
# Example usage
arr = [64, 34, 25, 12, 22, 11, 90]
print("Original array:", arr)
sorted_arr = quick_sort(arr)
print("Sorted array:", sorted_arr)
通常我們使用SQL存取資料庫,SQL會是很長一串,連結許多資料表,例如SQL Server的範例資料庫Northwind,結構如下圖: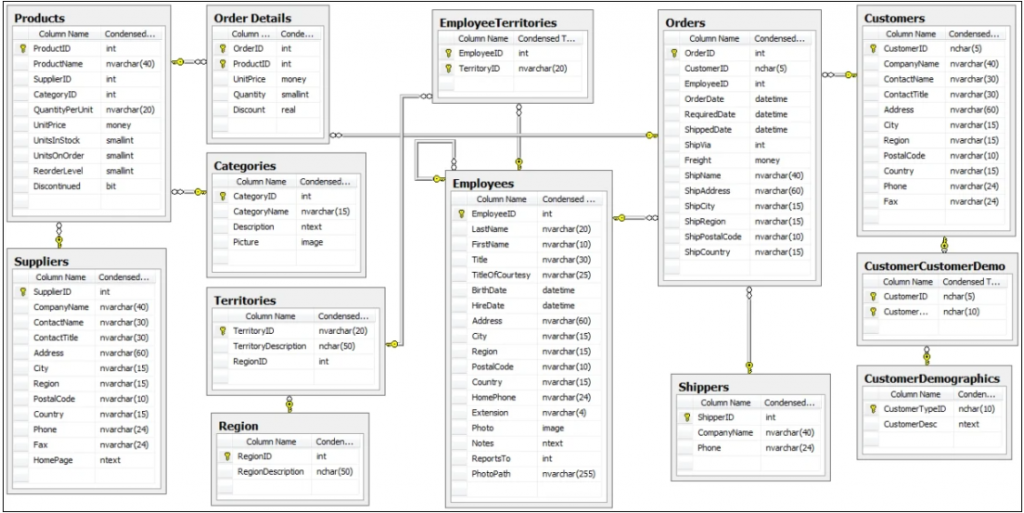
範例4. 進行銷售量統計。
explain the following SQL:
SELECT Categories.CategoryName,
Products.ProductName,
Sum(([Order Details].UnitPrice*Quantity*(1-Discount)/100)*100) AS ProductSales
FROM Categories
JOIN Products On Categories.CategoryID = Products.CategoryID
JOIN [Order Details] on Products.ProductID = [Order Details].ProductID
JOIN [Orders] on Orders.OrderID = [Order Details].OrderID
WHERE Orders.ShippedDate Between DATETIME('1997-01-01') And DATETIME('1997-12-31')
GROUP BY Categories.CategoryName, Products.ProductName;

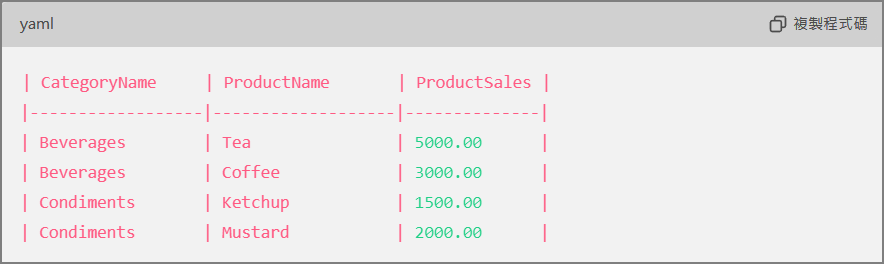
這對撰寫SQL的老手都有莫大的幫助,有時候別人寫的SQL很難理解,須一邊核對DB Schema,一邊觀察輸出結果,才能瞭解SQL的用意,ChatGPT幫我們全部彙總在一起,對於除錯及優化,非常有幫助。
與SQL解析相反,以下透過描述,請ChatGPT幫我們生成SQL。我們會覺得ChatGPT很熟悉Northwind資料庫,測試可能不客觀,所以,改以筆者自創的資料庫試試看。
範例5. 生成SQL與Django ORM程式碼。
generate vote summary based on database schema as below:
CREATE TABLE "polls_poll" ("id" integer NOT NULL PRIMARY KEY AUTOINCREMENT, "name" varchar(50) NOT NULL, "description" text NOT NULL, "pub_date" datetime NOT NULL);
CREATE TABLE "polls_question" ("id" integer NOT NULL PRIMARY KEY AUTOINCREMENT, "seq_no" integer NOT NULL, "question_text" varchar(200) NOT NULL, "is_optional" bool NOT NULL, "poll_id" bigint NOT NULL REFERENCES "polls_poll" ("id") DEFERRABLE INITIALLY DEFERRED);
CREATE INDEX "polls_question_poll_id_b6ace2e1" ON "polls_question" ("poll_id");
CREATE TABLE "polls_choice" ("id" integer NOT NULL PRIMARY KEY AUTOINCREMENT, "seq_no" integer NOT NULL, "choice_text" varchar(200) NOT NULL, "question_id" bigint NOT NULL REFERENCES "polls_question" ("id") DEFERRABLE INITIALLY DEFERRED);
CREATE INDEX "polls_choice_question_id_c5b4b260" ON "polls_choice" ("question_id");
CREATE TABLE "polls_vote" ("id" integer NOT NULL PRIMARY KEY AUTOINCREMENT, "user_id" varchar(20) NOT NULL, "fill_date" datetime NOT NULL, "poll_id" bigint NOT NULL REFERENCES "polls_poll" ("id") DEFERRABLE INITIALLY DEFERRED);
CREATE INDEX "polls_vote_poll_id_482e29e3" ON "polls_vote" ("poll_id");
CREATE TABLE "polls_vote_result" ("id" integer NOT NULL PRIMARY KEY AUTOINCREMENT, "question_id" bigint NOT NULL REFERENCES "polls_question" ("id") DEFERRABLE INITIALLY DEFERRED, "vote_id" bigint NOT NULL REFERENCES "polls_vote" ("id") DEFERRABLE INITIALLY DEFERRED, "choice_no" integer NOT NULL);
CREATE INDEX "polls_vote_result_question_id_c803bc7c" ON "polls_vote_result" ("question_id");
SELECT
p.name AS poll_name,
q.seq_no AS question_number,
q.question_text,
c.seq_no AS choice_number,
c.choice_text,
COUNT(vr.id) AS vote_count
FROM
polls_poll p
JOIN
polls_question q ON p.id = q.poll_id
JOIN
polls_choice c ON q.id = c.question_id
LEFT JOIN
polls_vote_result vr ON c.seq_no = vr.choice_no AND vr.question_id = q.id
JOIN
polls_vote v ON v.poll_id = p.id AND v.id = vr.vote_id
GROUP BY
p.name, q.seq_no, q.question_text, c.seq_no, c.choice_text
ORDER BY
p.name, q.seq_no, c.seq_no;
將SQL貼到SQLiteSpy內執行,結果如下:完全無誤,它還統計每個問題的人數,更勝過筆者撰寫的程式。
進一步測試是否可以將SQL轉換成Django ORM指令,提示(Prompt)如下:
please convert above SQL to Django ORM statement
from django.db.models import Count
# Query to get vote summary
vote_summary = (Poll.objects
.filter(vote__isnull=False) # Ensures that only polls with votes are considered
.values('name', 'question__seq_no', 'question__question_text', 'question__choice__seq_no', 'question__choice__choice_text')
.annotate(vote_count=Count('question__choice__voteresult'))
.order_by('name', 'question__seq_no', 'question__choice__seq_no')
)
# Example of how to print or use the result
for poll in vote_summary:
print(f"Poll: {poll['name']}")
print(f"Question {poll['question__seq_no']}: {poll['question__question_text']}")
print(f" Choice {poll['question__choice__seq_no']}: {poll['question__choice__choice_text']} - {poll['vote_count']} votes")
ChatGPT也可以幫我們分析資料,這裡要特別介紹【Sketch】套件,它可以搭配ChatGPT或其他LLM模型,進行以下工作:
步驟如下:
pip install sketch
pip install openai
SKETCH_USE_REMOTE_LAMBDAPROMPT=False
OPENAI_API_KEY=<YOUR_API_KEY>
使用Jupyter notebook,開啟sketch_test.ipynb。
載入測試資料集tips。
import sketch
import seaborn as sns
df = sns.load_dataset('tips')
df.head()
df.sketch.ask("how much is average tip?")
The average tip is 2.998279.
df.sketch.howto("Plot the sex versus tip")
import matplotlib.pyplot as plt
# create a bar plot of sex versus tip
plt.bar(df['sex'], df['tip'])
# add labels and title
plt.xlabel('Sex')
plt.ylabel('Tip')
plt.title('Tip Amount by Sex')
# show the plot
plt.show()
將程式貼到下一個空格(Cell)進行繪圖:
使用【apply】指令,針對表格的每一筆資料詢問ChatGPT。
import pandas as pd
print(pd.DataFrame({'State': ['Colorado', 'Kansas', 'California', 'New York']})
.sketch.apply("What is the capitol of [{{ State }}]?"))
0 \n\nThe capitol of Colorado is Denver.
1 \n\nThe capital of Kansas is Topeka.
2 \n\nThe capital of California is Sacramento.
3 \n\nThe capital of New York is Albany.
除了以上介紹,ChatGPT還可以生成測試資料/表格、網頁、CSS...等,或許還有更多的未知世界有待我們去探索,連OpenAI CEO Sam Altman也不知道ChatGPT的極限到哪裡。
本系列的程式碼會統一放在GitHub,本篇的程式放在src/20資料夾,歡迎讀者下載測試,如有錯誤或疏漏,請不吝指正。

