
在先前介紹完了 Alertmanager 的基本架構後,我們理所當然的可以直接進入進階設定環節吧!本篇將會帶各位介紹關於如何調整 Alertmanager 核心設定,藉此我們能夠更了解到 Alertmanager 的運作機制。隨後,我們將會探討一些使用 Alertmanager 作為告警管理的實際注意事項,這也能加深我們對於告警事件概念的輪廓。

以下為一個 Alertmanager 設定範例檔案,我們可以藉此來理解各個設定項目的意義:
global:
smtp_smarthost: 'localhost:25'
smtp_from: 'alertmanager@example.org'
smtp_auth_username: 'alertmanager'
smtp_auth_password: 'password'
templates:
- '/etc/alertmanager/template/*.tmpl'
route:
group_wait: 30s
group_interval: 5m
repeat_interval: 3h
# A default receiverreceiver: team-X-mails
routes:
- matchers:
- service=~"foo1|foo2|baz"
receiver: team-X-mails
routes:
- matchers:
- severity="critical"
receiver: team-X-pager
- matchers:
- service="files"
receiver: team-Y-mails
routes:
- matchers:
- severity="critical"
receiver: team-Y-pager
- matchers:
- service="database"
receiver: team-DB-pager
# Also group alerts by affected database.group_by: [alertname, cluster, database]
routes:
- matchers:
- owner="team-X"
receiver: team-X-pager
continue: true
- matchers:
- owner="team-Y"
receiver: team-Y-pager
inhibit_rules:
- source_matchers: [severity="critical"]
target_matchers: [severity="warning"]
equal: [alertname, cluster, service]
receivers:
- name: 'team-X-mails'
email_configs:
- to: 'team-X+alerts@example.org'
- name: 'team-Y-mails'
email_configs:
- to: 'team-Y+alerts@example.org'
- name: 'team-Y-mails'
email_configs:
- to: 'team-Y+alerts@example.org'
- name: 'team-Y-pager'
pagerduty_configs:
- service_key: <team-Y-key>
- name: 'team-DB-pager'
pagerduty_configs:
- service_key: <team-DB-key>
global 是全局設置區域,它定義了告警管理的基礎配置,包括 SMTP 伺服器、發送者郵箱及 SMTP 認證資訊,這些設定會應用到所有的告警接收端。
smtp_smarthost:指定用來發送郵件的 SMTP 伺服器地址及端口號,這裡是 localhost:25。 smtp_from:郵件的發送者地址。 smtp_auth_username 和 smtp_auth_password:SMTP 認證使用的帳號與密碼。
Alertmanager 支援自定義告警模板,透過 templates 設定,我們可以指定 Alertmanager 使用的模板路徑。這些模板可以用來自定義告警通知的格式,支持將 Prometheus 中的變數嵌入郵件或其他通知中。
templates:
- '/etc/alertmanager/template/*.tmpl'
Alertmanager 的路由機制是其核心功能之一。透過 route 區塊,我們可以定義告警分發的方式。路由可以根據告警的標籤(如 service 或 severity)來決定將告警發送給哪個接收者(receiver)。
route:
group_wait: 30s
group_interval: 5m
repeat_interval: 3h
關鍵設定:
route:
receiver: team-X-mails
routes:
- matchers:
- service=~"foo1|foo2|baz"
receiver: team-X-mails
routes:
- matchers:
- severity="critical"
receiver: team-X-pager
路由設定: 這一段定義了多層次的路由結構:
告警抑制是用來避免因同一問題產生的多個不同嚴重度的告警。例如,當一個 critical 級別的告警出現時,我們可能不希望收到關聯的 warning 級別告警。
inhibit_rules:
- source_matchers: [severity="critical"]
target_matchers: [severity="warning"]
equal: [alertname, cluster, service]
這段設定告訴 Alertmanager,當有 critical 嚴重性的告警出現時,會抑制同樣 alertname 且屬於同一 cluster 和 service 的 warning 告警,這樣能減少重複或冗餘的通知。
Alertmanager 允許將多個相似的告警分組,以減少通知的數量,並提高可讀性。通過 group_by 參數,我們可以指定按照哪些標籤對告警進行分組。
group_by: [alertname, cluster, database]
這段配置將告警按照 alertname、cluster 和 database 來分組,這樣當多個數據庫相關的告警發生時,它們將會被合併成一個通知,而不是每個告警單獨發送,從而提高了告警通知的整體效率。
告警去重的功能旨在避免對相同問題的重複通知。Alertmanager 會根據告警的標籤來進行去重,當多個相同的告警進來時,它只會發送一次通知,並在告警狀態發生變更(如恢復正常)時再發送更新。
去重的依據:Alertmanager 會根據 alertname、service、instance 等先有標籤進行去重。這些標籤組合決定了每個唯一的告警。
接收者(receivers)定義了告警應該發送到的具體目標。例如,可以是電子郵件、PagerDuty、Slack 等。每個接收者可以設置不同的通知渠道和格式。以下是 team-X-mails 接收者的設定:
receivers:
- name: 'team-X-mails'
email_configs:
- to: 'team-X+alerts@example.org'
這裡指定了 team-X-mails 通過電子郵件將告警發送到 team-X+alerts@example.org。
另外,team-DB-pager 是透過 PagerDuty 發送告警的範例:
- name: 'team-DB-pager'
pagerduty_configs:
- service_key: <team-DB-key>
接下來,我們就再更進一步的探討 Prometheus 與 Alertmanager 的運作機制,還有那些實際運作時會遇到的問題與解決方式。
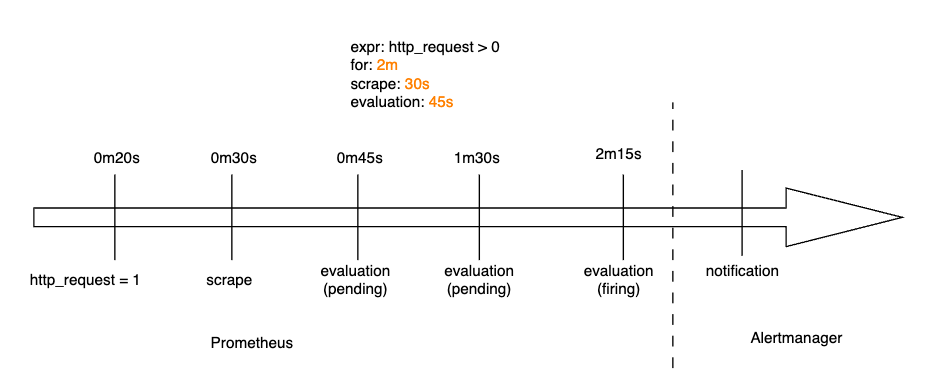
注意:這裡只的 Prometheus 告警規則生命週期,皆還在向 Alertmanager 發送告警之前,並不包含 Alertmanager 的處理流程,我們需要明確清楚其中差異。
在 Prometheus 的運作流程中,指標抓取(scraping)與告警評估(evaluation)是兩個關鍵的環節:
一個告警在 Prometheus 中可以有以下三種狀態:
而告警的狀態只會在每次評估週期中發生變化,並且狀態轉換取決於是否設置了 FOR 設定:
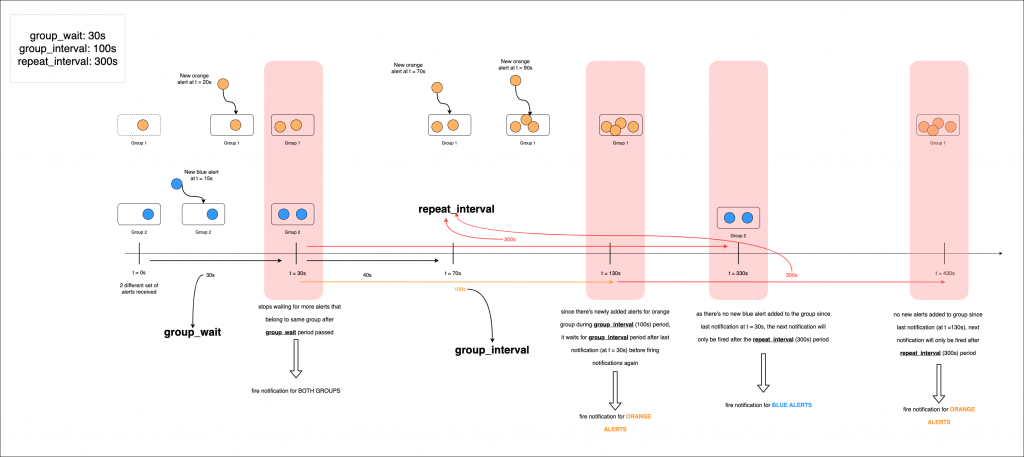
ref: https://jaanhio.me/blog/understanding-alertmanager/
Alertmanager 是告警通知管道的最後一環,在告警變為 "firing"(觸發)或 "inactive"(解除)時,它會接收並發送通知(注意,處於 "pending" 狀態的告警不會被轉發到 Alertmanager)。
其中一個重要功能是將相似的告警進行分組,這對於避免接收端被大量相同類型的告警轟炸非常有用。例如,當同一告警條件在多個節點上發生時,我們可以將所有節點的告警整合為一個通知,而不是為每個節點分別發送。這樣的分組雖然有效,但也可能引入額外的延遲。
Alertmanager 的通知分組主要由以下參數控制:group_by、group_wait 和 group_interval:
group_by: [ 'namespace', 'service' ]
group_wait: 30s
group_interval: 5m
當一個新告警觸發時,系統會等待 group_wait 的時間(例如 30 秒)才發送通知,以便在此期間收集其他符合 group_by 條件的告警,將它們一同分組發送。這表示,如果 group_wait 設為 30 秒,Alertmanager 將緩衝該告警 30 秒,等待其他可能的告警加入緩衝區,然後再發送。
如果之後在下一次評估中,同一分組內有新的告警被觸發,這些告警不會再等待 group_wait,而是等待 group_interval(例如 5 分鐘)後再發送。group_interval 決定了自上次通知發送後,需要等待多長時間才會再次發送相同分組內的通知。
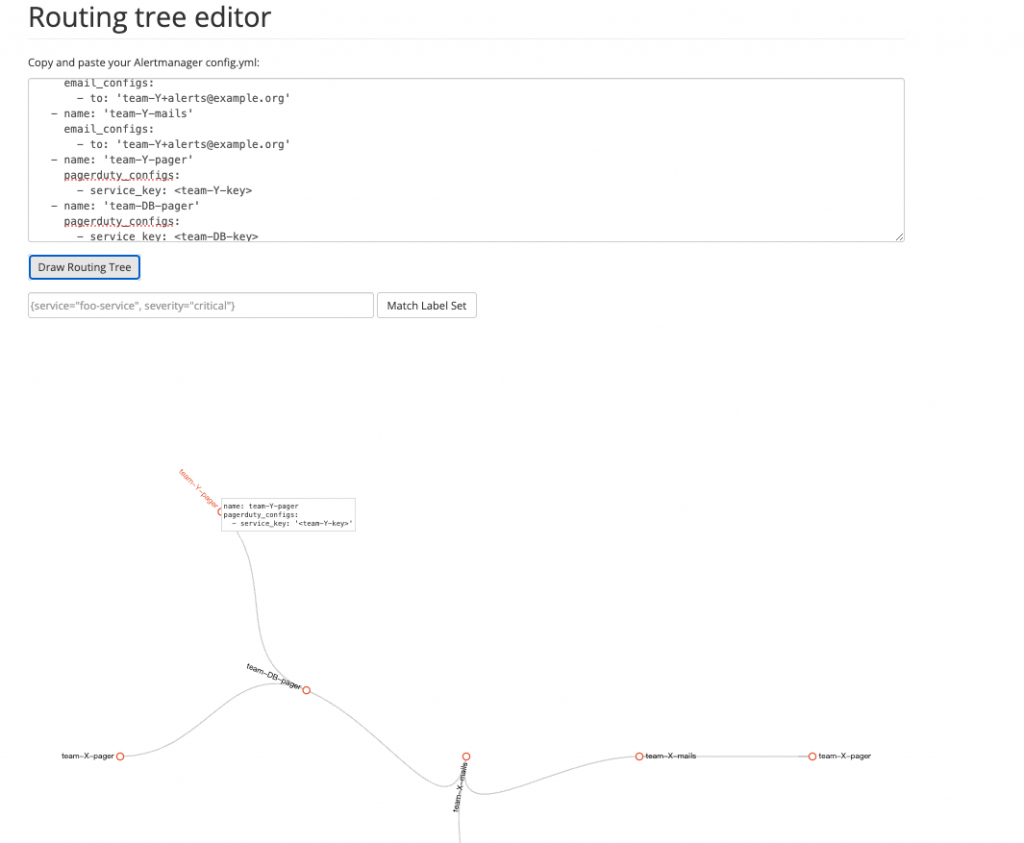
在 Prometheus 提到的最佳實踐中,首先,我們要保持路由設計簡單,第一級路由應該匹配 service 或 team,以確保告警能夠正確地分派。使用 amtool 或路由樹編輯器來進行測試和驗證,以確保配置的正確性,將相關告警進行分組,使通知對使用者更具意義。
此外,每個服務或團隊應該自行管理其設定檔和告警的間隔,以適應各自的客製需求。
下圖為 Routing Tree Editor 工具,可以讓我們更直觀的了解告警路由的設定:
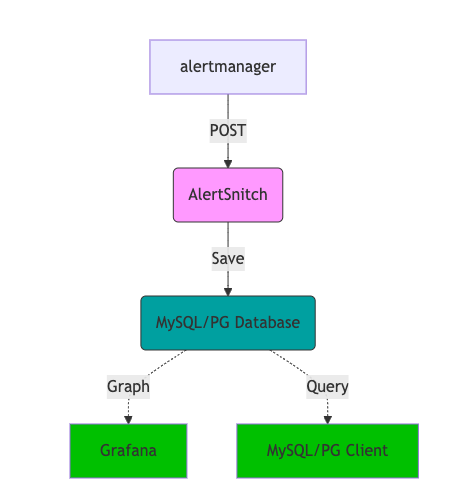
在大部分的團隊中,告警事件通常是直接發送到目的地如 Slack 或 Email 等,這樣的設計雖然簡單,但卻會遇到一個問題,那就是告警事件的歷史紀錄難以追蹤,如果想要檢視某個服務在某個時間點的告警事件,可能需要翻閱大量的通知紀錄,這不僅效率低下,而且容易遺漏。
而 alertsnitch 是一個開源的告警歷史持久化專案,可以將告警事件儲存到 MySQL 或 PostgreSQL 中,並透過 Grafana 進行視覺化。藉此,我們開始擁有了統計追蹤並且優化告警事件的能力,每週甚至每天的告警事件,都可以被我們清楚的掌握。
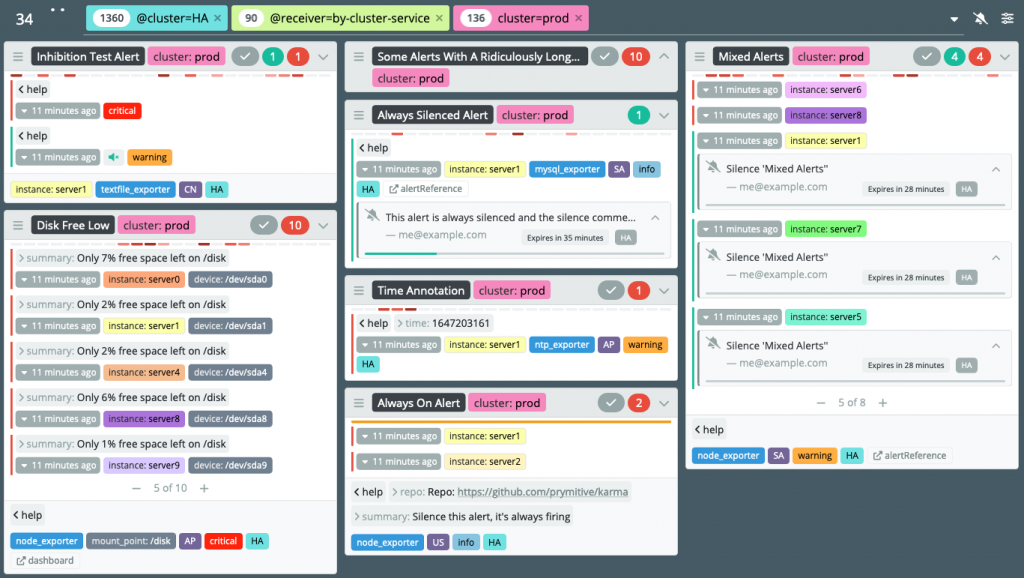
Karma 是一款為 Prometheus Alertmanager 提供的強大告警儀表板工具,專為彌補 Alertmanager 原生 UI 的不足而設計。它能從多個 Alertmanager 實例中聚合告警,為使用者提供一個集中的視覺化介面,方便管理和監控各種告警。
Karma 的核心功能包括:
在這章節中,我們已經算是對 Alertmanager 困難的部分有了蠻深入的了解。關於告警規則以及告警事件的的生命週期,我們需要特別注意其中的差異,這樣在實際的運作中,我們才能夠更清楚的知道問題的發生點在哪裡。了解其中的差異後,不論我們往後轉換到 Alertmanager 以外的告警事件工具,我們都能夠快速上手。有了紮實的基礎觀念後,我們就不需要被特定服務的告警事件工具給綁死,這樣在日後的技術選型上,我們就能夠有更多的選擇空間,。
References:

