上一篇介紹神經網路的基本概念,這次透過簡單的範例理解梯度下降法的運作。
範例. 以神經網路建構攝氏與華氏溫度轉換的模型,我們收集7筆資料如下:
| 攝氏(X) | 華氏(Y) |
|---|---|
| -40 | -40 |
| -10 | 14 |
| 0 | 32 |
| 8 | 46 |
| 15 | 59 |
| 22 | 72 |
| 38 | 100 |
import tensorflow as tf
import numpy as np
c = np.array([-40, -10, 0, 8, 15, 22, 38], dtype=float)
f = np.array([-40, 14, 32, 46, 59, 72, 100], dtype=float)
model = tf.keras.models.Sequential([
tf.keras.layers.Input((1,)),
tf.keras.layers.Dense(1)
])
model.compile(optimizer=optimizer=tf.keras.optimizers.Adam(0.1),
loss='mse',
metrics=['accuracy'])
model.fit(c, f, epochs=500)
x_test = np.array([50., 100.], dtype=float)
y_test = np.array([50., 100.], dtype=float) * 1.8 + 32
loss, accuracy = model.evaluate(x_test, y_test, verbose=False)
print(f'loss={loss:4f}, accuracy={accuracy:4f}')
plt.xlabel('Epochs')
plt.ylabel("Loss")
plt.plot(history.history['loss'])
plt.show()
print(f'模型權重(w, b):{model.weights[0][0][0].numpy()},
{model.weights[1][0].numpy()}')
import matplotlib.pyplot as plt
plt.plot(c, f, 'g')
plt.plot(c, model.predict(c, verbose=False), 'r')
plt.show()
完整程式碼如下,可另存為 02_攝氏與華式溫度轉換.py。
# 攝氏與華式溫度轉換
# 載入套件
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
# 載入上述表格資料
c = np.array([-40, -10, 0, 8, 15, 22, 38], dtype=float)
f = np.array([-40, 14, 32, 46, 59, 72, 100], dtype=float)
# 建立模型
model = tf.keras.models.Sequential([
tf.keras.layers.Input((1,)),
tf.keras.layers.Dense(1)
])
# 設定優化器(optimizer)、損失函數(loss)、效能衡量指標(metrics)的類別
model.compile(optimizer=tf.keras.optimizers.Adam(0.1),
loss='mse',
metrics=['accuracy'])
# 訓練模型
history = model.fit(c, f, epochs=500)
# 繪圖觀察損失趨勢
plt.xlabel('Epochs')
plt.ylabel("Loss")
plt.plot(history.history['loss'])
plt.show()
# 模型評分
x_test = np.array([50., 100.], dtype=float)
y_test = np.array([50., 100.], dtype=float) * 1.8 + 32
loss, accuracy = model.evaluate(x_test, y_test, verbose=False)
print(f'loss={loss:4f}, accuracy={accuracy:4f}')
# 顯示模型權重(w, b)
print(f'模型權重(w, b):{model.weights[0][0][0].numpy()}, \
{model.weights[1][0].numpy()}')
# 繪圖
plt.plot(c, f, 'g')
plt.plot(c, model.predict(c, verbose=False), 'r')
plt.show()
損失(Loss):即MSE,約為1.698075。
訓練至450週期,損失已趨收斂,不再明顯減少。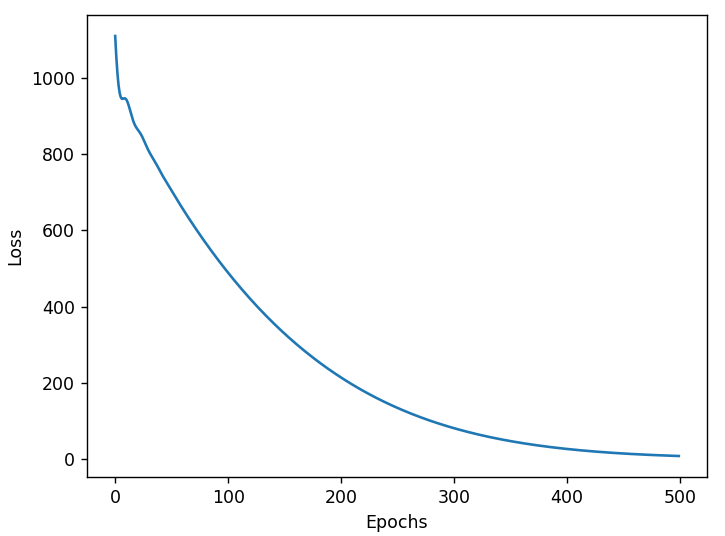
模型權重(w, b)分別為 1.8201, 29.3206,與理論公式『華氏 = 1.8 * 攝氏 + 32』略有差異。
繪圖觀察:綠線為理論公式,紅線為預測公式,差異不大。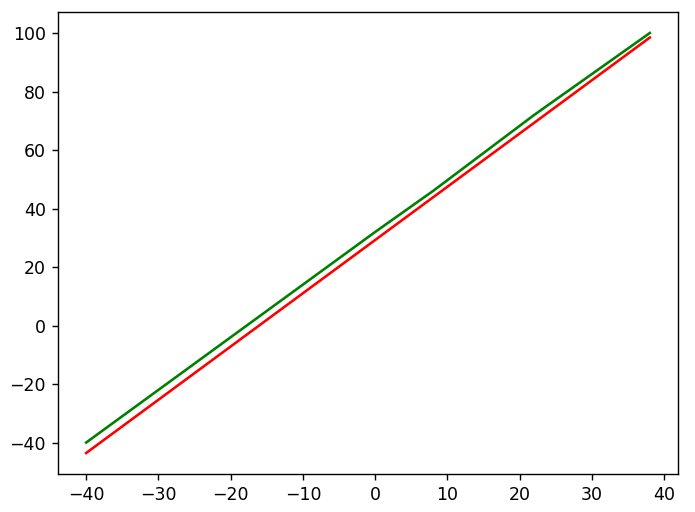
為了讓模型更準確,可以進行效能調校,有下列方向:
以下實驗前兩種方式。
原來是7筆訓練資料,現在改用程式產生1000筆資料。
c = np.linspace(-100, 100, 1000)
f = c * 1.8 + 32
執行結果:模型權重(w, b):1.8000006675720215, 32.00000762939453,幾乎與理論公式相同,可見梯度下降法確實可以訓練出近乎精準的模型。
仍然只用7筆訓練資料,改用更複雜的模型,再加一層隱藏層(Dense),可設定任意個數神經元,筆者設為10,模型會增加10條迴歸線,模型建構如下:
model = tf.keras.models.Sequential([
tf.keras.layers.Input((1,)),
tf.keras.layers.Dense(10),
tf.keras.layers.Dense(1)
])
執行結果:
損失(Loss):即MSE,約為0.043138,比原來的1.698075小的多。
不到100個訓練週期就收斂了。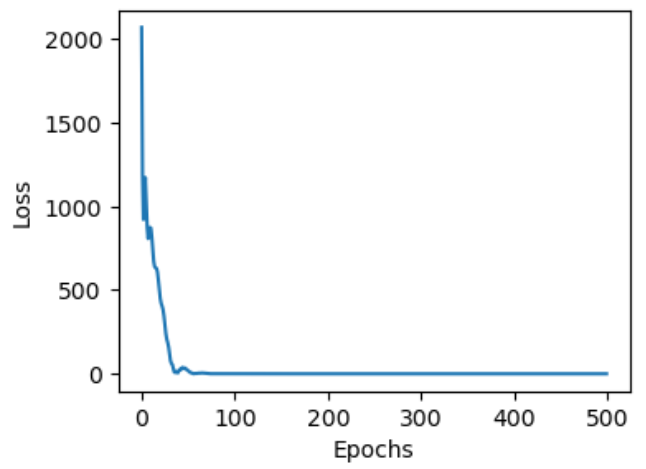
使用下列程式碼可取得每一層Dense的權重(w, b)。
# 顯示模型第1個Dense權重(w, b)
print(f'第1個Dense權重(w, b):{model.layers[0].weights[0][0].numpy()}, \
{model.layers[0].weights[1].numpy()}')
# 顯示模型第2個Dense權重(w, b)
print(f'第2個Dense權重(w, b):{model.layers[1].weights[0][0].numpy()}, \
{model.layers[1].weights[1].numpy()}')


以上使用很簡單的神經網路,建構攝氏與華式溫度轉換模型,下次我們再進一步說明為什麼梯度下降法面對各式的訓練資料都可以找到最佳解。
Happy Data Science !!
徹底理解神經網路的核心 -- 梯度下降法 (1)
徹底理解神經網路的核心 -- 梯度下降法 (2)
徹底理解神經網路的核心 -- 梯度下降法 (3)
徹底理解神經網路的核心 -- 梯度下降法 (4)
徹底理解神經網路的核心 -- 梯度下降法的應用 (5)
梯度下降法(6) -- 學習率動態調整
梯度下降法(7) -- 優化器(Optimizer)
梯度下降法(8) -- Activation Function
梯度下降法(9) -- 損失函數
梯度下降法(10) -- 總結
 I code so I am
I code so I am
