神經網路(Neural Network)是深度學習的基石,不管是大語言模型(ChatGPT)或生成式AI(MidJourney、Stable Diffusion...等)都是以各式神經層建構的神經網路,這些產品的模型是如何被訓練出來的? 答案就是『梯度下降法』(Gradient Descent),以下我們就用大量圖表及實作說明梯度下降法、優化器(Optimizer)、損失函數(Loss Function)...等概念。
神經網路是由多個的神經層構成的,如下圖,第一層是輸入層,中間是隱藏層(Hidden Layer),最後一層稱為輸出層。每一層內的圓圈代表輸出入的神經元(Nourons)。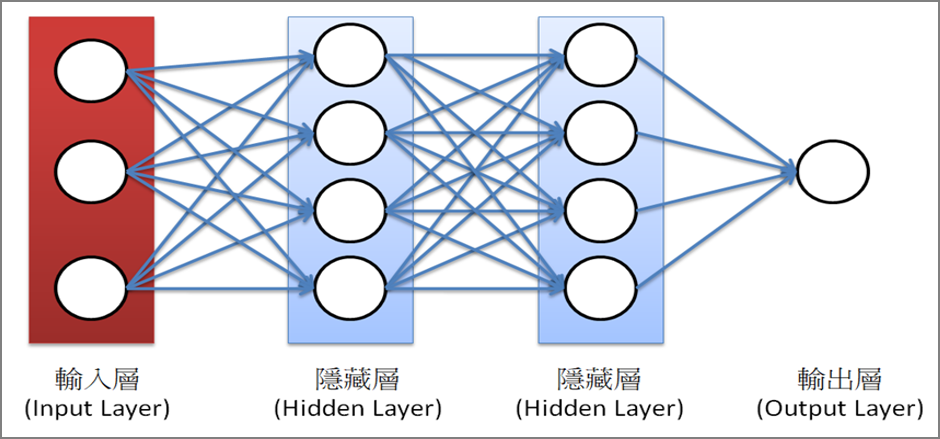
圖一. 神經網路的構成
以TensorFlow官網首頁程式碼為例,它主要是要辨識圖片中的手寫阿拉伯數字,其中有關神經網路模型建構的程式碼如下:
# 建立模型
model = tf.keras.models.Sequential([
tf.keras.layers.Input((28, 28)),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(10, activation='softmax')
])
模型內的神經層可任意組合,也可以使用Functional API定義非順序型的複雜模型,如下圖,有3個Input、2個Output。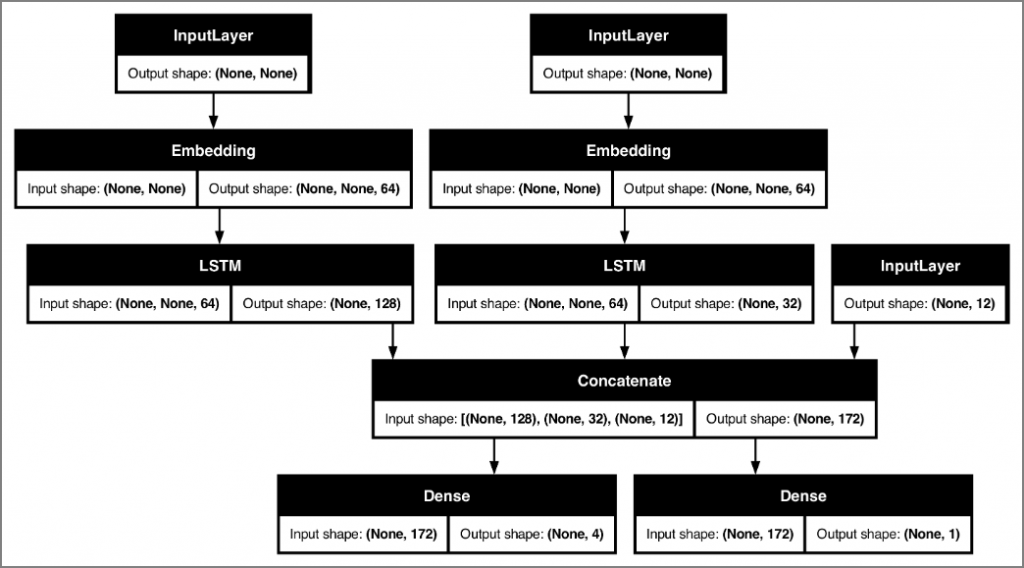
圖二. Functional API 神經網路
第一個Dense參數128代表會輸出128個神經元,而輸入就是Input層定義的784個神經元,如不考慮其他參數,可以展開為128條迴歸線,每條迴歸線有784個特徵(X),公式如下: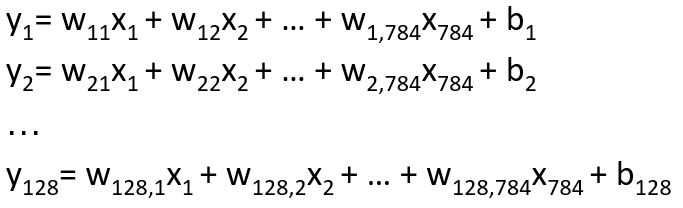
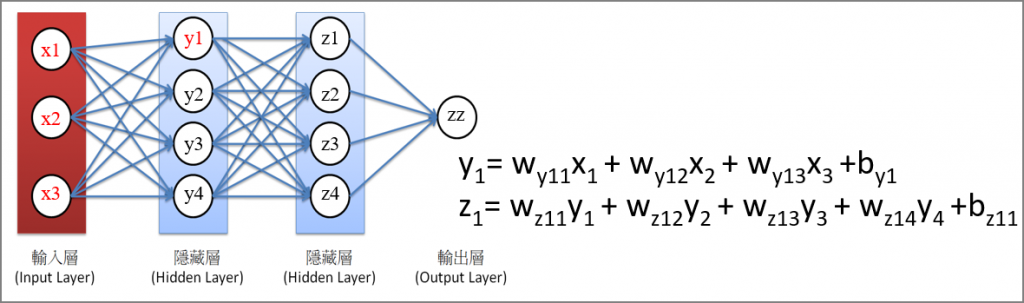
圖三. 將神經網路視為多條迴歸線的組合
光一層Dense就有這麼多的w及b,要怎麼求解呢? 再加上其他參數,如非線性函數 activation function,求解更加複雜,關鍵答案就是優化(Optimization),以逼近法求近似解,演算法有很多種,例如最普遍的梯度下降法(Gradient Descent)及最新的KAN,本系列文章會仔細的探討梯度下降法。
在討論梯度下降法之前,我們先小幅修改TensorFlow官網首頁程式碼,它主要是要辨識手寫阿拉伯數字:
import tensorflow as tf
mnist = tf.keras.datasets.mnist
(x_train, y_train),(x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
model = tf.keras.models.Sequential([
tf.keras.layers.Input((28, 28)),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(10, activation='softmax')
])
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
model.fit(x_train, y_train, epochs=5)
loss, accuracy = model.evaluate(x_test, y_test, verbose=False)
print(f'loss={loss}, accuracy={accuracy}')
完整程式碼如下,可另存為01_tf1.py。
# 手寫阿拉伯數字辨識
# 載入套件
import tensorflow as tf
# 載入手寫阿拉伯數字訓練資料(MNIST)
mnist = tf.keras.datasets.mnist
(x_train, y_train),(x_test, y_test) = mnist.load_data()
# 特徵縮放
x_train, x_test = x_train / 255.0, x_test / 255.0
# 建立模型
model = tf.keras.models.Sequential([
tf.keras.layers.Input((28, 28)),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(10, activation='softmax')
])
# 設定優化器(optimizer)、損失函數(loss)、效能衡量指標(metrics)的類別
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# 訓練模型
model.fit(x_train, y_train, epochs=5)
# 模型評分
loss, accuracy = model.evaluate(x_test, y_test, verbose=False)
print(f'loss={loss}, accuracy={accuracy}')
TensorFlow將所有的求解過程隱藏在一行程式碼 model.fit 中,下一篇我們就來仔細解析內部原理及相關參數設定。
徹底理解神經網路的核心 -- 梯度下降法 (1)
徹底理解神經網路的核心 -- 梯度下降法 (2)
徹底理解神經網路的核心 -- 梯度下降法 (3)
徹底理解神經網路的核心 -- 梯度下降法 (4)
徹底理解神經網路的核心 -- 梯度下降法的應用 (5)
梯度下降法(6) -- 學習率動態調整
梯度下降法(7) -- 優化器(Optimizer)
梯度下降法(8) -- Activation Function
梯度下降法(9) -- 損失函數
梯度下降法(10) -- 總結
 I code so I am
I code so I am
