魔鬼藏在細節裡,要讓模型訓練更快速、更準確,必須進一步掌握模型的超參數(Hyperparameters)設定,包括如何動態調整學習率、選用各種優化器、損失函數、Activation function...等,本篇先探討學習率的調整,並尋找最佳學習率初始值。
註:超參數(Hyperparameters)是指模型訓練前可以調整的參數,例如權重初始值、學習率、執行週期,如以程式角度而言,優化器、損失函數、Activation function也都是函數的參數,而一般參數通常指的是模型的權重(Weight)與偏差(Bias)。
如下圖,反向傳導會使用優化器(Optimizer)更新權重,公式如下:
新權重 = 原權重 — 學習率(learning rate) * 梯度(gradient)
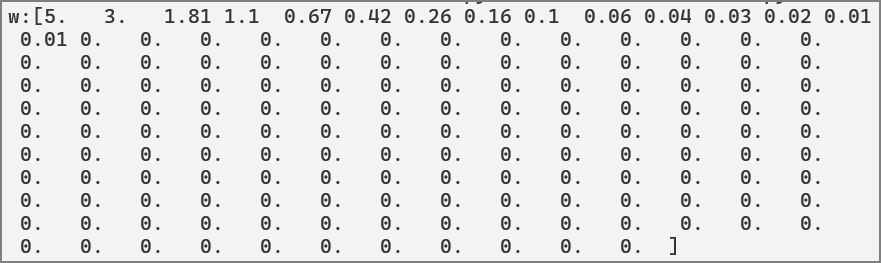
在前幾篇我們都設定學習率為固定值,更好的方法是動態調整學習率,訓練一開始,離最佳解很遠時,可設定較大的學習率,快步前進,之後逐步縮小,避免錯過最佳解,並找到更精準的解。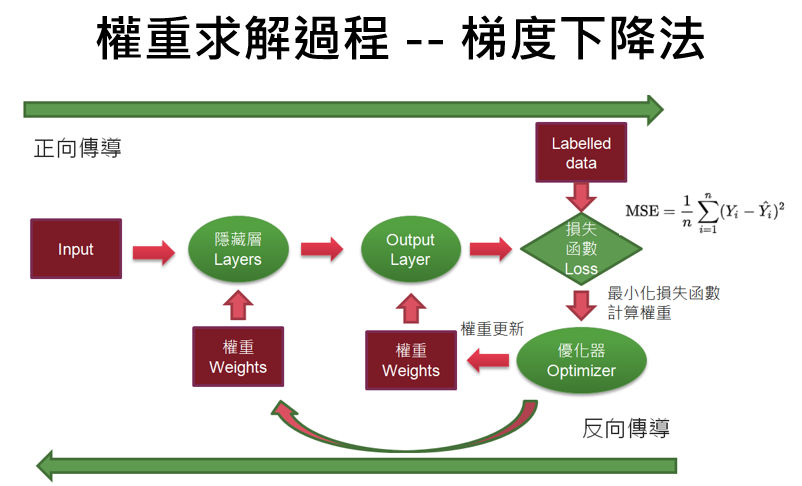
圖一. 梯度下降法的權重求解過程
範例1. 動態調整學習率,加速簡單損失函數求解。
def train(w_start, epochs, lr):
w_list = np.zeros(epochs+1)
w = w_start
w_list[0] = w
# 執行N個訓練週期
for i in range(epochs):
# 權重的更新W_new
# W_new = W — learning_rate * gradient
w -= dfunc(w) * lr
w_list[i+1] = w
lr -= lr/100 # 學習率每週期減少1/100
return w_list
lr = 0.2 # 學習率
如何在TensorFlow中動態調整學習率呢? 請看下列範例。
範例2. 動態調整學習率與取得學習率。
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
def get_lr_metric(optimizer):
def lr(y_true, y_pred):
return optimizer._get_current_learning_rate()
return lr
model = tf.keras.models.Sequential([tf.keras.layers.Input((20,)), tf.keras.layers.Dense(10)])
optimizer = tf.keras.optimizers.Adam()
lr_metric = get_lr_metric(optimizer)
model.compile(optimizer, loss='sparse_categorical_crossentropy', metrics=['accuracy', lr_metric])
def scheduler(epoch, lr):
if epoch < 10:
return lr
else:
return np.float64(lr * tf.math.exp(-0.1)) # 學習率每週期約減少1/10
callback = tf.keras.callbacks.LearningRateScheduler(scheduler)
history = model.fit(np.arange(100).reshape(5, 20), np.zeros(5),
epochs=15, callbacks=[callback], verbose=2)
plt.figure(figsize=(8, 6))
plt.plot(history.history['lr'], 'r')
plt.show()
完整程式碼如下,另存為 16_Get_learning_rate.py。
執行:python 16_Get_learning_rate.py。
執行結果:後5個週期逐次減少1/10。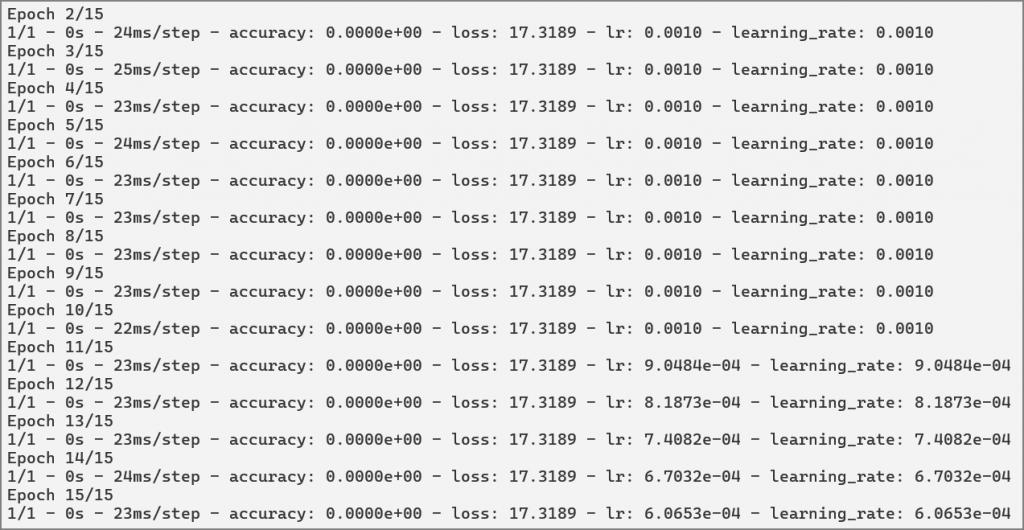
繪圖。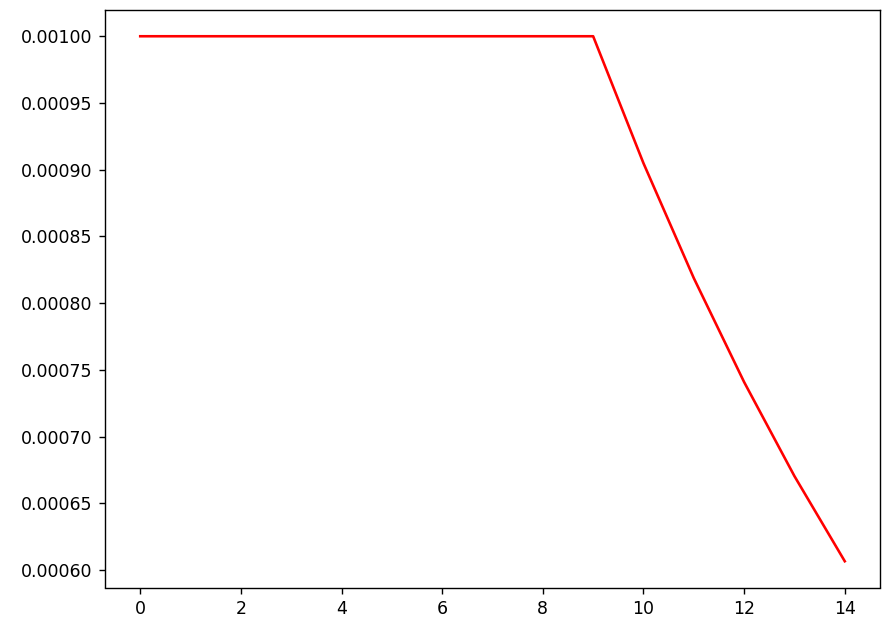
知道如何動態調整學習率後,那學習率初始值要設多少呢?
範例3. 動態調整學習率與取得學習率。
import tensorflow as tf
from tensorflow.keras.layers import Conv2D, MaxPool2D, Flatten, Dense, Dropout
import matplotlib.pyplot as plt
from lr_finder import LRFinder
fashion_mnist = tf.keras.datasets.fashion_mnist
(x_train, y_train), (x_valid, y_valid) = fashion_mnist.load_data()
x_train, x_valid = x_train / 255.0, x_valid / 255.0
x_train = x_train[..., tf.newaxis]
x_valid = x_valid[..., tf.newaxis]
train_ds = tf.data.Dataset.from_tensor_slices((x_train, y_train)).shuffle(10000).batch(32)
valid_ds = tf.data.Dataset.from_tensor_slices((x_valid, y_valid)).batch(32)
def build_model():
return tf.keras.models.Sequential([
Conv2D(32, 3, activation='relu'),
MaxPool2D(),
Flatten(),
Dense(128, activation='relu'),
Dropout(0.1),
Dense(10, activation='softmax')
])
lr_finder = LRFinder()
model = build_model()
adam = tf.keras.optimizers.Adam(learning_rate=1e-1)
model.compile(optimizer=adam, loss='sparse_categorical_crossentropy', metrics=['accuracy'])
model.fit(train_ds, epochs=5, callbacks=[lr_finder])
lr_finder.plot()
plt.axvline(1e-3, c='r');
plt.show()
_, accuracy = model.evaluate(valid_ds, verbose=False)
print(f'accuracy={accuracy}')
model = build_model() # reinitialize model
adam = tf.optimizers.Adam(1e-3)
model.compile(optimizer=adam, loss='sparse_categorical_crossentropy', metrics=['accuracy'])
_ = model.fit(train_ds, validation_data=valid_ds, epochs=5, verbose=True)
_, accuracy = model.evaluate(valid_ds, verbose=False)
print(f'最佳學習率 accuracy={accuracy}')
# 尋找最佳學習率初始值
# 載入套件
import tensorflow as tf
from tensorflow.keras.layers import Conv2D, MaxPool2D, Flatten, Dense, Dropout
import matplotlib.pyplot as plt
from lr_finder import LRFinder
# 載入訓練資料
fashion_mnist = tf.keras.datasets.fashion_mnist
(x_train, y_train), (x_valid, y_valid) = fashion_mnist.load_data()
x_train, x_valid = x_train / 255.0, x_valid / 255.0
x_train = x_train[..., tf.newaxis]
x_valid = x_valid[..., tf.newaxis]
train_ds = tf.data.Dataset.from_tensor_slices((x_train, y_train)).shuffle(10000).batch(32)
valid_ds = tf.data.Dataset.from_tensor_slices((x_valid, y_valid)).batch(32)
# 模型定義
def build_model():
return tf.keras.models.Sequential([
Conv2D(32, 3, activation='relu'),
MaxPool2D(),
Flatten(),
Dense(128, activation='relu'),
Dropout(0.1),
Dense(10, activation='softmax')
])
# 模型訓練
lr_finder = LRFinder()
model = build_model()
adam = tf.keras.optimizers.Adam(learning_rate=1e-1)
model.compile(optimizer=adam, loss='sparse_categorical_crossentropy', metrics=['accuracy'])
model.fit(train_ds, epochs=5, callbacks=[lr_finder])
# 對訓練過程的學習率繪圖
lr_finder.plot()
plt.axvline(1e-3, c='r');
plt.show()
# 模型評分
_, accuracy = model.evaluate(valid_ds, verbose=False)
print(f'accuracy={accuracy}')
# 採用最佳學習率重新訓練。
model = build_model() # reinitialize model
adam = tf.optimizers.Adam(1e-3)
model.compile(optimizer=adam, loss='sparse_categorical_crossentropy', metrics=['accuracy'])
_ = model.fit(train_ds, validation_data=valid_ds, epochs=5, verbose=True)
_, accuracy = model.evaluate(valid_ds, verbose=False)
print(f'最佳學習率 accuracy={accuracy}')
import matplotlib.pyplot as plt
import tensorflow as tf
from tensorflow.keras.callbacks import Callback
class LRFinder(Callback):
"""`Callback` that exponentially adjusts the learning rate after each training batch between `start_lr` and
`end_lr` for a maximum number of batches: `max_step`. The loss and learning rate are recorded at each step allowing
visually finding a good learning rate as per https://sgugger.github.io/how-do-you-find-a-good-learning-rate.html via
the `plot` method.
"""
def __init__(self, start_lr: float = 1e-7, end_lr: float = 10, max_steps: int = 100, smoothing=0.9):
super(LRFinder, self).__init__()
self.start_lr, self.end_lr = start_lr, end_lr
self.max_steps = max_steps
self.smoothing = smoothing
self.step, self.best_loss, self.avg_loss, self.lr = 0, 0, 0, 0
self.lrs, self.losses = [], []
def on_train_begin(self, logs=None):
self.step, self.best_loss, self.avg_loss, self.lr = 0, 0, 0, 0
self.lrs, self.losses = [], []
def on_train_batch_begin(self, batch, logs=None):
self.lr = self.exp_annealing(self.step)
self.model.optimizer.learning_rate=self.lr
def on_train_batch_end(self, batch, logs=None):
logs = logs or {}
loss = logs.get('loss')
step = self.step
if loss:
self.avg_loss = self.smoothing * self.avg_loss + (1 - self.smoothing) * loss
smooth_loss = self.avg_loss / (1 - self.smoothing ** (self.step + 1))
self.losses.append(smooth_loss)
self.lrs.append(self.lr)
if step == 0 or loss < self.best_loss:
self.best_loss = loss
if smooth_loss > 4 * self.best_loss or tf.math.is_nan(smooth_loss):
self.model.stop_training = True
if step == self.max_steps:
self.model.stop_training = True
self.step += 1
def exp_annealing(self, step):
return self.start_lr * (self.end_lr / self.start_lr) ** (step * 1. / self.max_steps)
def plot(self):
fig, ax = plt.subplots(1, 1)
ax.set_ylabel('Loss')
ax.set_xlabel('Learning Rate (log scale)')
ax.set_xscale('log')
ax.xaxis.set_major_formatter(plt.FormatStrFormatter('%.0e'))
ax.plot(self.lrs, self.losses)
執行:python 17_tf_lr_finder.py。
執行結果:最佳學習率為10**-3,該點以前損失減少的幅度非常小,從10**-3開始可以有效地降低損失。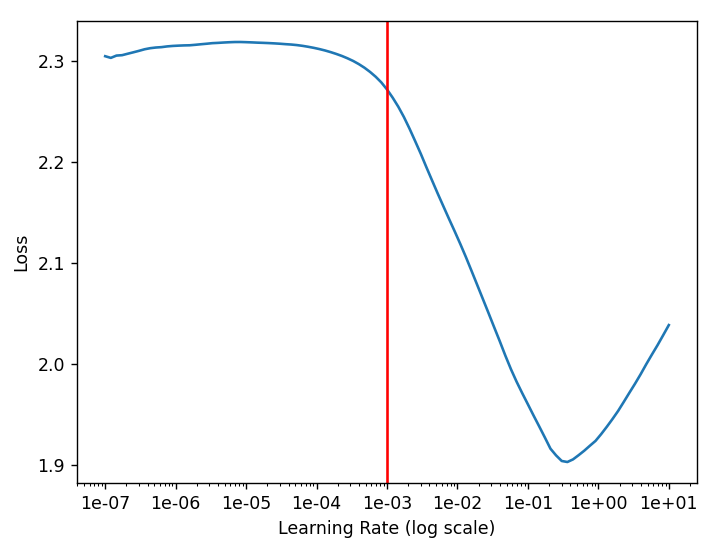
使用動態調整學習率的模型訓練與採用最佳學習率(10**-3)重新訓練結果相同,表示lr_finder.py確實可以找到最佳學習率初始值。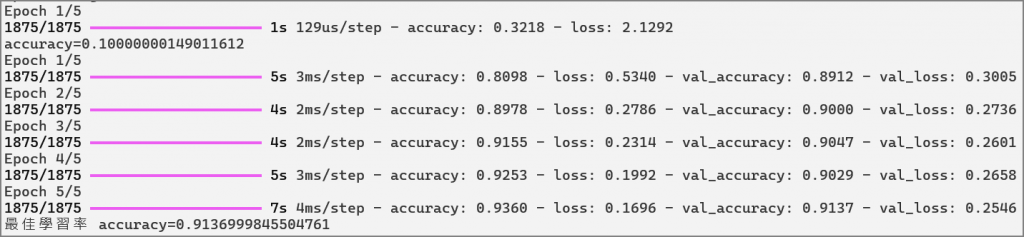
動態調整學習率可以很複雜,不僅讓模型訓練更快速、更準確,也希望避開區域最小值(Local minimum),找尋全局最小值(Global minimum),有興趣的讀者可參閱『A Gentle Introduction to Learning Rate Schedulers』及相關論文。
徹底理解神經網路的核心 -- 梯度下降法 (1)
徹底理解神經網路的核心 -- 梯度下降法 (2)
徹底理解神經網路的核心 -- 梯度下降法 (3)
徹底理解神經網路的核心 -- 梯度下降法 (4)
徹底理解神經網路的核心 -- 梯度下降法的應用 (5)
梯度下降法(6) -- 學習率動態調整
梯度下降法(7) -- 優化器(Optimizer)
梯度下降法(8) -- Activation Function
梯度下降法(9) -- 損失函數
梯度下降法(10) -- 總結
有沒實作可以看看動態跟不動態的分別? 建議生成個美女圖實作示範
範例1是一個簡單的比較,不過,大哥應該不會太滿意,較複雜的實驗可參考『How to Use Cosine Decay Learning Rate Scheduler in Keras』,內含許多圖表,以各種參數比較收斂速度及模型評分,要知道的更詳細,可參閱『SGDR: Stochastic Gradient Descent with Warm Restarts』,它以CIFAR 10/100資料集為例,進行實驗。
大哥建議生成個美女圖實作示範,我也很想,目前力有未逮,等未來擴充軍火設備後,優先考慮大哥建議。
 I code so I am
I code so I am

 iThome鐵人賽
iThome鐵人賽