當我們想要的,不只是一個粗略的矩形邊界框,而是物體每一個像素級別的精確輪廓,例如精準描繪出腫瘤的位置,這時單靠我們前幾天學的方法已經不敷使用。這時,我們需要依靠影像分割 (image segmentation) 來達到目的。
影像分割主要可分成兩個大類:語義分割 (semantic segmentation) 跟實例分割 (instance segmentation)。
語意分割的目標是,為影像中的每一個像素,都分配一個類別標籤。它只關心「這是一個什麼類別的像素」,而不區分同類別的不同實例。
舉例來說,在一張街景圖中,語意分割會將所有屬於「汽車」的像素都標記為同一個顏色(例如藍色),所有屬於「人」的像素都標記為另一個顏色(例如紅色),所有屬於「道路」的像素標記為灰色。它無法告訴你,畫面中藍色區域裡,到底有幾輛獨立的汽車。
實例分割則是一個更複雜、更精細的任務。它在語意分割的基礎上,更進一步,需要區分出同類別的不同實例。
同樣是在街景圖中,實例分割不僅會將所有汽車的像素標記為「汽車」,還會為第一輛車的所有像素分配一個唯一的標識(例如深藍色),為第二輛車的所有像素分配另一個唯一的標識(例如淺藍色)。
因此,實例分割可以看作是目標偵測和語意分割的結合體:它既像目標偵測一樣,找到了每個獨立的物體實例;又像語意分割一樣,為每個實例提供了像素級的精確輪廓(稱為遮罩)。
傳統的 CNN 分類網路(如 VGG, ResNet),在最後通常會接幾個全連接層,將特徵圖攤平成一維向量,最終輸出一個類別分數。這個過程丟失了所有的空間資訊。
全卷積網路 (Fully Convolutional Network, FCN) 為解決這個問題,選擇將分類網路末尾的全連接層,全部替換成 1×1 的卷積層。這樣整個網路就只由卷積層和池化層構成,故得此名。
因為由於 CNN 中的池化層會不斷縮小特徵圖的尺寸,FCN 輸出的熱力圖解析度很低,邊界非常粗糙。為了解決這個問題,FCN 引入了上採樣或反卷積操作,並結合了來自淺層網路的、解析度更高但語意資訊較弱的特徵圖(透過跳躍連接),從而生成一張與原圖等大的、精細的分割結果。
U-Net 是以 FCN 為基礎,設計給生醫影像分割任務的架構,將跳躍連接發揮到極致。
U-Net 的網路結構呈現出一個非常對稱的 U 型
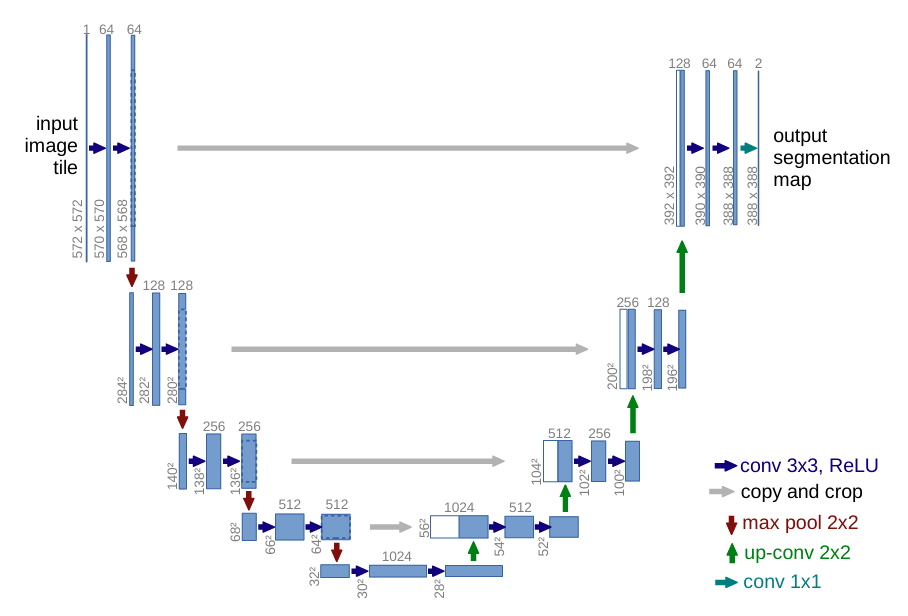
(U-Net: Convolutional Networks for Biomedical Image Segmentation)
左側是編碼器 (encoder) 或收縮路徑 (contracting path):這部分就是一個標準的 CNN,由一系列的卷積和最大池化層組成,負責從影像中提取層級化的特徵,並逐步降低空間解析度。
右側是解碼器 (decoder) 或擴展路徑 (expansive path):這部分負責將編碼器提取出的低解析度、高語意的特徵圖,逐步地上採樣回原始影像的尺寸。
長跳躍連接 (long skip connections):這是 U-Net 的精髓。它會在解碼器的每一層,都將上採樣後的特徵圖,與編碼器中對應解析度的特徵圖,在通道維度上進行拼接 (concatenate)。
這個設計帶來了好處:解碼器在重建精細邊界時,能夠直接利用來自編碼器淺層的高解析度、低階特徵(如邊緣訊息),從而產生非常精確的分割結果,也令他至今仍是醫療影像分割領域最常用、最基礎的架構之一。
實例分割最常用的方法則是 Mask R-CNN,原理是在一個成功的目標偵測器上,再增加一個小小的分支來預測物體的輪廓。
的架構,就是在 Faster R-CNN 基礎上,進行了擴展:
骨幹網路 (backbone):使用 ResNet-FPN 等強大的網路來提取特徵。
候選區域網路 (RPN):與 Faster R-CNN 完全相同,用來生成候選的物體邊界框 (RoI)。
RoIAlign:Faster R-CNN 中的 RoI 池化,在從特徵圖上提取區域時,會進行取整操作,導致像素級的錯位,這對於分割任務是致命的。因此,Mask R-CNN 使用了一個改進版的 RoIAlign,它使用雙線性插值,來更精確地對齊特徵。
並行的頭部網路:對於每個經過 RoIAlign 處理後的候選區域,Mask R-CNN 會並行地送入兩個分支:
分支一(分類與回歸)與 Faster R-CNN 完全相同,預測該區域的類別和邊界框的精確位置。
分支二 (遮罩預測):這是新增的分支。它是一個小型的 FCN,負責為該區域內的每一個像素,預測一個二值的分割遮罩(前景 vs. 背景)。
import torch
import torchvision
import torchvision.transforms as transforms
from PIL import Image, ImageDraw
import requests
from io import BytesIO
import numpy as np
import cv2
import random
# --- 1. 載入預訓練的 Mask R-CNN 模型 ---
print("正在載入預訓練的 Mask R-CNN 模型...")
model = torchvision.models.detection.maskrcnn_resnet50_fpn(pretrained=True)
model.eval()
print("模型載入完成!")
# --- 2. 準備 COCO 類別標籤 (與 Day 19 相同) ---
COCO_INSTANCE_CATEGORY_NAMES = [
'__background__', 'person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus',
'train', 'truck', 'boat', 'traffic light', 'fire hydrant', 'N/A', 'stop sign',
'parking meter', 'bench', 'bird', 'cat', 'dog', 'horse', 'sheep', 'cow',
'elephant', 'bear', 'zebra', 'giraffe', 'N/A', 'backpack', 'umbrella', 'N/A', 'N/A',
'handbag', 'tie', 'suitcase', 'frisbee', 'skis', 'snowboard', 'sports ball',
'kite', 'baseball bat', 'baseball glove', 'skateboard', 'surfboard', 'tennis racket',
'bottle', 'N/A', 'wine glass', 'cup', 'fork', 'knife', 'spoon', 'bowl',
'banana', 'apple', 'sandwich', 'orange', 'broccoli', 'carrot', 'hot dog', 'pizza',
'donut', 'cake', 'chair', 'couch', 'potted plant', 'bed', 'N/A', 'dining table',
'N/A', 'N/A', 'toilet', 'N/A', 'tv', 'laptop', 'mouse', 'remote', 'keyboard', 'cell phone',
'microwave', 'oven', 'toaster', 'sink', 'refrigerator', 'N/A', 'book',
'clock', 'vase', 'scissors', 'teddy bear', 'hair drier', 'toothbrush'
]
# --- 3. 準備輸入圖片 ---
img_pil = Image.open("bird.jpg").convert("RGB")
transform = transforms.Compose([transforms.ToTensor()])
img_tensor = transform(img_pil)
# --- 4. 進行預測 ---
with torch.no_grad():
prediction = model([img_tensor])
# prediction[0] 包含 'boxes', 'labels', 'scores', 'masks'
# --- 5. 視覺化結果 ---
def visualize_instance_segmentation(image_pil, prediction, threshold=0.5):
img_cv = np.array(image_pil)
# 創建一個顏色列表
colors = [[random.randint(0, 255) for _ in range(3)] for _ in COCO_INSTANCE_CATEGORY_NAMES]
for i in range(len(prediction[0]['scores'])):
score = prediction[0]['scores'][i]
if score > threshold:
# 獲取遮罩
mask = prediction[0]['masks'][i, 0].mul(255).byte().cpu().numpy()
label_id = prediction[0]['labels'][i].item()
# 獲取該實例的顏色
color = colors[label_id]
# 將顏色應用到遮罩區域
# 創建一個與原圖同尺寸的彩色遮罩
colored_mask = np.zeros_like(img_cv, dtype=np.uint8)
colored_mask[mask > 127] = color # 閾值設為 127
# 將彩色遮罩半透明地疊加到原圖上
img_cv = cv2.addWeighted(img_cv, 1, colored_mask, 0.5, 0)
# 繪製邊界框 (可選)
box = prediction[0]['boxes'][i].numpy().astype(int)
cv2.rectangle(img_cv, (box[0], box[1]), (box[2], box[3]), color, 2)
return Image.fromarray(img_cv)
result_image = visualize_instance_segmentation(img_pil, prediction, threshold=0.7)
result_image.show()
結果


 iThome鐵人賽
iThome鐵人賽