
到目前為止,我們已經學會了如何在 LangChain 中進行提示設計、輸出解析、流程控制,以及工具調用等核心技巧。當這些功能能夠靈活組合時,AI 就不再只是回答問題,而是能夠完成更具挑戰性的複雜任務。
在今天的篇章中,我們要將這些技巧整合起來,挑戰一個完整的案例:具備網路搜尋能力的 AI 部落格寫手。這不僅是對前面技術的驗證,更能展示 LangChain 如何幫助 AI 連結外部世界,成為真正實用的內容生成助手。
在進入程式碼之前,我們先從整體角度來看「AI 部落格寫手」的運作方式。這個應用的核心任務,是根據使用者輸入的主題,生成一篇結構完整的文章;同時在需要的情況下,還要能即時搜尋並整合外部資料。
整體流程可以拆解成以下幾個步驟:
graph TD
A[主題輸入] --> B[需求判斷]
B -->|需要| C[資料搜尋]
C --> D[內容整合]
B -->|不需要| D
D --> E[草稿與關鍵字]
E --> F[最終輸出]

這樣的設計能讓 AI 在處理題目時更具彈性:它不再只依賴模型訓練時的靜態知識,而是能動態補充最新資訊,輸出的文章也就更符合實際應用情境與讀者需求。
在設計 AI 部落格寫手的時候,「即時搜尋」是一個關鍵能力。模型本身的知識有時候會過時,特別是遇到需要引用最新新聞、研究或產業動態時,沒有外部搜尋的幫助就難以生成可靠的內容。這時,我們就需要一個能與 LangChain 無縫整合的搜尋服務。
在眾多搜尋服務中,Tavily 是目前 LangChain 官方推薦的選擇之一,原因有以下幾點:
@langchain/tavily 套件中提供工具類別 TavilySearch,只需要幾行程式碼就能完成 Tavily Search API 的整合。換句話說,Tavily 讓我們能快速為 AI 加上「查找並整合外部知識」的能力,而不用額外花時間處理複雜的搜尋 API 或資料清洗流程。
在開始使用 Tavily Search API 之前,我們需要先準備好 API 金鑰,才能在程式中成功呼叫服務。
以下是取得 API 金鑰的步驟說明。
打開瀏覽器,進入 Tavily 官方網站。若尚未註冊帳號,請點選右上角的「Sign Up」註冊;已有帳號則點選「Log In」。
登入成功後,系統會自動導向 Dashboard 管理頁面。在這裡可以查看 API 使用情況與相關設定。
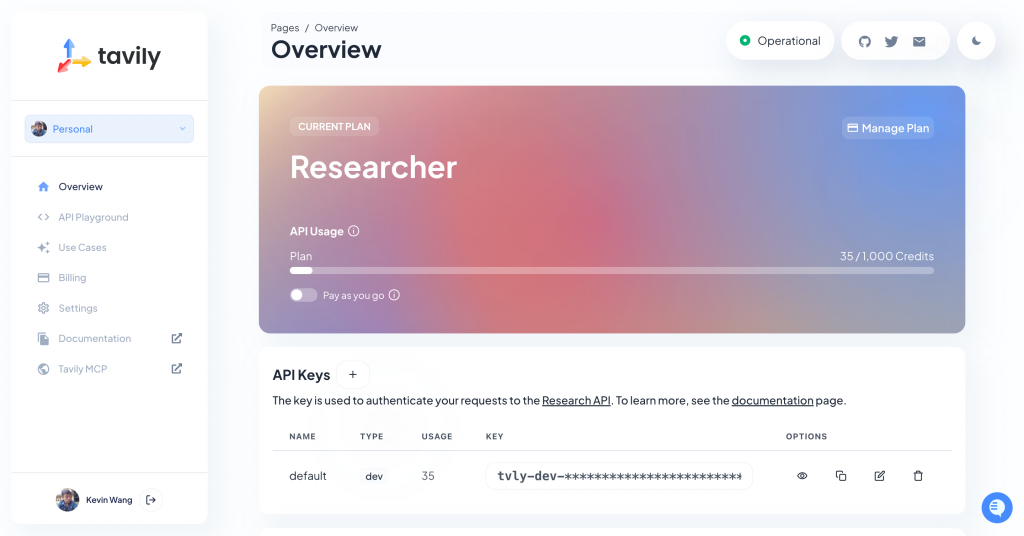
在 Dashboard 首頁的下方,可以找到「API Keys」區域。Tavily 預設會為每個帳號建立一把可用的金鑰,開發者只需將它複製下來,並妥善保存到專案的環境變數設定中,這樣之後就能在程式中安全地呼叫 Tavily Search API 了。
準備好 Tavily API 金鑰後,我們就能開始動手實作一個具備搜尋能力的 AI 部落格寫手。這個實作的核心概念是:將 LLM 與搜尋工具結合,讓模型能先決定是否需要搜尋,再將取得的結果整合成一篇完整文章。
在開始之前,請先初始化一個新的專案,命名為 blog-writer,我們將在這個專案中完成實作內容。
Note:如果你對 Node.js 專案初始化流程還不熟悉,可以先回顧 Day 01 中「建立 Node.js 專案與 TypeScript 開發環境」的內容。
建立專案環境後,請在專案根目錄中執行以下指令,安裝所需依賴套件:
npm install @langchain/core @langchain/openai @langchain/tavily dotenv inquirer ora zod
@langchain/core:LangChain 的核心模組,提供所有開發元件的共通介面與執行邏輯。@langchain/openai:LangChain 提供的 OpenAI 模型整合套件。@langchain/tavily:LangChain 官方支援的 Tavily Search API 工具整合套件。dotenv:用來讀取 .env 檔案中的環境變數,例如 API 金鑰。inquirer:建立互動式命令列介面,讓使用者可以輸入主題、確認是否繼續產生下一篇文章等。ora:在命令列介面中顯示動態的 loading 動畫與狀態提示,提升使用者體驗。zod:用來定義資料結構並驗證輸出的資料格式,確保 JSON 回傳內容符合我們預期的欄位與型別。在專案根目錄建立 .env 檔案,填入你的 OpenAI API 與 Tavily 金鑰:
OPENAI_API_KEY=sk-...
TAVILY_API_KEY=tvly-dev-...
在程式中,我們會透過 dotenv 套件自動載入 .env 檔案中的內容,並用 process.env.OPENAI_API_KEY 與 process.env.TAVILY_API_KEY 讀取這些金鑰。
為了讓程式碼易於維護與擴充,我們會將不同職責的程式碼拆分成模組化結構,如下所示:
blog-writer/
├── src/
│ ├── tools/ # 外部工具整合模組
│ │ └── search.tool.ts # Tavily Search 工具設定
│ ├── prompts/ # LLM 提示模板模組
│ │ ├── researcher.prompt.ts # 生成背景知識
│ │ ├── writer.prompt.ts # 產生文章草稿
│ │ ├── seo.prompt.ts # 產出 SEO 關鍵字
│ │ ├── editor.prompt.ts # 組合最終 Markdown 輸出
│ ├── parsers/ # LLM 輸出解析模組
│ │ ├── researcher.parser.ts # 驗證背景知識輸出
│ │ ├── writer.parser.ts # 驗證文章草稿輸出
│ │ ├── seo.parser.ts # 驗證 SEO 關鍵字輸出
│ │ └── editor.parser.ts # 處理最終 Markdown 輸出
│ └── index.ts # 程式進入點
├── package.json # 專案設定與依賴套件清單
├── tsconfig.json # TypeScript 編譯設定
└── .env # 環境變數設定
專案結構遵循模組化原則,不同功能各自獨立,便於閱讀與維護。同時具備可擴充性,例如更換搜尋服務或新增輸出格式時,只需改動對應模組即可。index.ts 則作為單一入口,負責串接所有模組並執行完整流程。
在這個專案中,我們需要一個能即時取得網路資訊的工具,來補足 LLM 在最新事件與動態資訊上的不足。
這裡我們使用 Tavily Search API,它專為 AI 應用設計,回傳的搜尋結果是結構化的資料(包含標題、URL、摘要與原始內容),比傳統搜尋引擎更方便與 LLM 整合。
請在 tools 資料夾中建立 search.tool.ts,並加入以下程式碼:
// src/tools/search.tool.ts
import { TavilySearch } from '@langchain/tavily';
export const searchTool = new TavilySearch({
tavilyApiKey: process.env.TAVILY_API_KEY,
maxResults: 5,
topic: 'general',
includeAnswer: true,
includeRawContent: true
});
在這段程式碼中,我們設定了以下參數:
tavilyApiKey:從 .env 中讀取的 API 金鑰,用來驗證請求權限。maxResults:限制回傳結果的數量,避免資料過多造成處理負擔。topic:設定搜尋的主題類別,例如 general(一般)、news(新聞)等,能提升搜尋精準度。includeAnswer:若為 true,Tavily 會自動整合搜尋結果並提供摘要,方便直接使用。includeRawContent:若為 true,會包含原始網頁的文字內容,適合需要自行進一步分析的情境。這個 searchTool 稍後會透過 LangChain 的 Tool Calling 機制綁定到 LLM,讓模型能在需要最新資訊時,自動呼叫它並取得搜尋結果。
在這個專案中,我們將 AI 賦予不同的角色任務,讓模型在各階段能以明確的身份來執行工作。這樣的設計能幫助模型專注於單一職責,並且產出符合我們需求的格式與內容。整體規劃如下:
這樣的拆分能讓各個 Prompt 責任清晰、模組化,後續若要調整文章風格或增加輸出格式,只需要修改個別檔案即可,不會影響到整體流程。
第一步是讓模型扮演「研究員」的角色,判斷主題是否需要搜尋最新資料,並將背景知識整理成標準化的 JSON 輸出。
請在 prompts 資料夾中建立 researcher.prompt.ts,並加入以下程式碼:
// src/prompts/researcher.prompt.ts
import { ChatPromptTemplate, HumanMessagePromptTemplate, SystemMessagePromptTemplate } from '@langchain/core/prompts';
export const researcherPrompt = ChatPromptTemplate.fromMessages([
SystemMessagePromptTemplate.fromTemplate(`
你是一位技術研究員,可以根據主題提供足夠的背景知識。
任務:
1. 根據主題判斷是否需要呼叫工具搜尋最新資料。
- 涉及最新資訊、時效性話題(版本、發布、價格、趨勢等)才需要搜尋。
- 如果知識已足夠,可直接回答,不必搜尋。
2. 有搜尋時,整合結果成背景知識,並列出參考資料(title + url)。
3. 無搜尋時,依你的知識整理背景知識,references 為空陣列。
4. 輸出格式:JSON,必須符合以下格式:
{format_instructions}
`),
HumanMessagePromptTemplate.fromTemplate(`
主題:{input}
請先判斷是否需要搜尋;若需要,請呼叫工具並整理背景知識後輸出 JSON。
`),
]);
這個 Prompt 的重點在於「判斷與決策」:只有在遇到時效性或需要補充資料的主題時才會呼叫 Tavily Search,否則就直接依照模型既有知識輸出結果。如此能避免不必要的 API 呼叫,並確保輸出是一份統一格式的 JSON。
第二步是讓模型扮演「部落格寫手」,根據提供的背景知識撰寫一份結構完整的文章草稿。
請在 prompts 資料夾中建立 writer.prompt.ts,並加入以下程式碼:
// src/prompts/writer.prompt.ts
import { PromptTemplate } from '@langchain/core/prompts';
export const writerPrompt = PromptTemplate.fromTemplate(`
你是一位部落格寫手,請根據以下背景知識撰寫文章。
背景知識:
{background}
輸出格式:
{format_instructions}
`);
這個 Prompt 的任務是將背景知識轉換為完整的文章內容,但此階段尚未包含 SEO 關鍵字與引用資料,專注於生成可讀性與結構兼具的初稿。
第三步是由模型扮演「SEO 專員」,從背景知識中提取 5–10 組關鍵字,方便後續用於標註或搜尋引擎優化。
請在 prompts 資料夾中建立 seo.prompt.ts,並加入以下程式碼:
// src/prompts/seo.prompt.ts
import { PromptTemplate } from '@langchain/core/prompts';
export const seoPrompt = PromptTemplate.fromTemplate(`
根據以下背景知識,產出 5–10 組 SEO 關鍵字。
背景知識:
{background}
輸出格式:
{format_instructions}
`);
透過這個步驟,文章在完成後除了具備內容完整度,還能同時兼顧 SEO 需求,增加實際應用價值。
最後一步是「編輯」的任務,將文章草稿、SEO 關鍵字與參考資料整合起來,並輸出為 Markdown 格式的最終成品。
請在 prompts 資料夾中建立 editor.prompt.ts,並加入以下程式碼:
// src/prompts/editor.prompt.ts
import { PromptTemplate } from '@langchain/core/prompts';
export const editorPrompt = PromptTemplate.fromTemplate(`
根據提供資訊 {data},輸出 Markdown 格式的文章。
`);
這樣的輸出方式讓結果能直接應用在部落格或任何支援 Markdown 的平台,從輸入主題到最終文章形成了一個完整的自動化流程。
LLM 在不同階段會產生不同格式的回應,例如 JSON、清單或純文字。若沒有正確的驗證與解析,後續流程可能會因格式錯誤而中斷。因此,我們需要為每個主要任務設計對應的輸出解析器,確保生成結果結構正確、可安全存取,並維持整個流程的穩定性。
背景知識是文章生成的基礎,必須保證內容足夠且格式正確。這裡我們要求 background 至少 100 個字,並讓 references 保持為標題與 URL 的清單。
請在 parsers 資料夾中建立 researcher.parser.ts,並加入以下程式碼:
// src/parsers/researcher.parser.ts
import { StructuredOutputParser } from '@langchain/core/output_parsers';
import { z } from 'zod';
export const researcherParser = StructuredOutputParser.fromZodSchema(
z.object({
topic: z.string(),
background: z.string().min(100),
references: z.array(z.object({
title: z.string(),
url: z.string().url()
})).default([])
}),
);
這樣一來,不論模型是否使用搜尋工具,輸出的背景知識都會以一致的 JSON 結構呈現,並且參考資料清單符合網址格式。
文章草稿需要包含標題與主要內容,因此這裡的結構設計相對簡單。
請在 parsers 資料夾中建立 writer.parser.ts,並加入以下程式碼:
// src/parsers/writer.parser.ts
import { StructuredOutputParser } from '@langchain/core/output_parsers';
import { z } from 'zod';
export const writerParser = StructuredOutputParser.fromZodSchema(
z.object({
title: z.string(),
content: z.string(),
}),
);
這樣能保證每篇草稿至少有標題與正文,不會出現缺欄位或格式錯誤的情況。
SEO 關鍵字通常以逗號分隔字串的形式產生,因此可以直接使用 LangChain 內建的 CommaSeparatedListOutputParser。
請在 parsers 資料夾中建立 seo.parser.ts,並加入以下程式碼:
// src/parsers/seo.parser.ts
import { CommaSeparatedListOutputParser } from '@langchain/core/output_parsers';
export const seoParser = new CommaSeparatedListOutputParser();
透過這個解析器,模型回傳的字串能立即轉換為陣列,方便後續處理與使用。
最終文章需要以 Markdown 格式輸出,因此只需要一個能處理純字串的解析器即可。
請在 parsers 資料夾中建立 editor.parser.ts,並加入以下程式碼:
// src/parsers/editor.parser.ts
import { StringOutputParser } from '@langchain/core/output_parsers';
export const editorParser = new StringOutputParser();
這讓我們能直接取得乾淨的 Markdown 文字,不必再額外處理結構化資料。
最後一步,我們要把前面設計好的工具、提示模板和輸出解析器串接在一起,形成一個完整的流程,並透過 CLI 與使用者互動。
以下是 src/index.ts 的完整程式碼:
// src/index.ts
import 'dotenv/config';
import inquirer from 'inquirer';
import ora from 'ora';
import { ChatOpenAI } from '@langchain/openai';
import { RunnableSequence, RunnableParallel, RunnableLambda } from '@langchain/core/runnables';
import { searchTool } from './tools/search.tool';
import { researcherPrompt } from './prompts/researcher.prompt';
import { writerPrompt } from './prompts/writer.prompt';
import { seoPrompt } from './prompts/seo.prompt';
import { editorPrompt } from './prompts/editor.prompt';
import { researcherParser } from './parsers/researcher.parser';
import { writerParser } from './parsers/writer.parser';
import { seoParser } from './parsers/seo.parser';
import { editorParser } from './parsers/editor.parser';
const llm = new ChatOpenAI({
model: 'gpt-4o-mini',
});
const llmWithTools = llm.bindTools([searchTool]);
const chain = RunnableSequence.from([
RunnableLambda.from(async (input: string) => {
const formatInstr = researcherParser.getFormatInstructions();
const messages = await researcherPrompt.formatMessages({ input, format_instructions: formatInstr });
const aiMessage = await llmWithTools.invoke(messages);
messages.push(aiMessage);
const toolCalls = aiMessage.tool_calls || [];
if (toolCalls.length) {
for (const toolCall of toolCalls) {
const toolMessage = await searchTool.invoke(toolCall);
messages.push(toolMessage);
}
const followup = await llmWithTools.invoke(messages);
messages.push(followup);
}
const lastMessage = messages.slice(-1)[0].content as string;
return researcherParser.parse(lastMessage);
}),
RunnableParallel.from({
draft: RunnableLambda.from(async (input) => {
return await writerPrompt
.pipe(llm)
.pipe(writerParser)
.invoke({
background: input.background,
format_instructions: writerParser.getFormatInstructions(),
});
}),
keywords: RunnableLambda.from(async (input) => {
return await seoPrompt
.pipe(llm)
.pipe(seoParser)
.invoke({
background: input.background,
format_instructions: seoParser.getFormatInstructions(),
});
}),
references: RunnableLambda.from((input) => input.references),
}),
RunnableLambda.from(async (input) => {
return await editorPrompt
.pipe(llm)
.pipe(editorParser)
.invoke({
data: JSON.stringify({
title: input.draft.title,
content: input.draft.content,
keywords: input.keywords,
references: input.references,
}),
});
}),
]);
async function main() {
console.log('=== Blog Writer 已啟動 ===');
while (true) {
const { topic } = await inquirer.prompt<{ topic: string }>([
{
type: 'input',
name: 'topic',
message: '請輸入文章主題:',
filter: (v) => (v ?? '').trim(),
},
]);
if (!topic) break;
const spinner = ora('正在產生內容, 請稍候...').start();
try {
const result = await chain.invoke(topic);
spinner.succeed('完成!');
console.log('\n=== 產出結果 ===\n');
console.log(result);
console.log('\n=================\n');
} catch (err) {
spinner.fail('發生錯誤:');
console.error(err);
}
const { again } = await inquirer.prompt<{ again: boolean }>([
{
type: 'confirm',
name: 'again',
message: '要再產生一篇嗎?',
default: false,
},
]);
if (!again) break;
}
}
main().catch((e) => {
console.error(e);
process.exit(1);
});
這段程式的流程可以分為三個部分:
searchTool,最後輸出完整的背景知識 JSON。RunnableParallel 平行處理。同時,CLI 部分使用 inquirer 來接收使用者輸入與重複執行的選項,並透過 ora 提供動態的 Loading 動畫。
這樣,我們就完成了一個可以反覆使用的 AI 部落格寫手:從主題輸入到文章輸出,全流程自動化完成。
完成所有程式碼後,就可以透過以下指令啟動專案:
npm run dev
程式啟動後,終端機會提示你輸入想要撰寫的主題,例如:AI 金融。
以下是一個完整的執行範例:
=== Blog Writer 已啟動 ===
✔ 請輸入文章主題: AI 金融
✔ 完成!
=== 產出結果 ===
# AI在金融業中的革命:2025年的展望
隨著科技的迅猛發展,人工智能(AI)在金融行業的影響力日益增強。根據最新報告,2025年全球人工智能金融市場的估值預計將達到436億美元,並以34%的年增長率蓬勃發展。AI技術正逐步優化金融流程,使風險管理能力得到了顯著提升,並通過改進詐騙檢測和信用評估實現了成本的有效節省。
## AI在金融中的應用
AI在金融中的主要應用涵蓋以下幾個方面:
- **自動化的貸款審批和風險評估系統**:AI能快速分析客戶的財務狀況,從而提高貸款審批的效率。
- **精確的預測模型**:這些模型有助於金融機構預測市場趨勢和客戶行為,從而做出更準確的決策。
- **智能化的客戶服務**:通過AI聊天機器人和自動客服系統,金融機構能提供24/7的客戶服務,提升客戶體驗。
這些應用不僅提升了金融機構的運作效率,還為客戶提供了更加個性化的服務。面對市場競爭的加劇,金融機構採用AI技術已成為保持競爭優勢的重要策略之一。
## 未來展望
隨著AI技術的不斷進步,金融行業將能更有效地處理海量數據,提高服務的個性化程度,更好地滿足客戶的需求。未來,AI預計將推動整個金融行業的革新,對信貸決策、風險管理及客戶服務等所有環節帶來新的變革。
總之,AI在金融業的應用不僅是技術的進步,更是金融領域未來發展的重要驅動力。
## 參考資料
- [AI in Finance: Applications, Examples & Benefits | Google Cloud](https://cloud.google.com/discover/finance-ai)
- [20 Challenges AI Poses For The Finance World And How ... - Forbes](https://www.forbes.com/councils/forbesfinancecouncil/2025/04/29/20-challenges-ai-poses-for-the-finance-world-and-how-to-overcome-them/)
- [24 Examples of AI in Finance 2025 | Built In](https://builtin.com/artificial-intelligence/ai-finance-banking-applications-companies)
- [Top 20 AI in Finance Case Studies [2025] - DigitalDefynd](https://digitaldefynd.com/IQ/ai-in-finance-case-studies/)
- [How artificial intelligence is reshaping the financial services industry](https://www.ey.com/en_gr/insights/financial-services/how-artificial-intelligence-is-reshaping-the-financial-services-industry)
---
關鍵字:AI金融應用, 金融風險管理, 詐騙檢測技術, 信用評估系統, 自動化貸款審批, 個性化金融服務, AI在金融市場, 金融科技創新, 預測模型應用, 金融行業數據處理
=================
? 要再產生一篇嗎? (y/N)
如上所示,程式會自動完成以下流程:
這樣,你就擁有一個可以根據任意主題快速產出文章的 AI 部落格寫手,並能依需求多次重複使用。
今天我們把前面學到的 提示模板、輸出解析、流程控制、工具調用 等技巧整合起來,完成了一個具備 即時搜尋能力的 AI 部落格寫手:
inquirer、ora)提供互動體驗。透過這個案例,我們看到 LangChain 不只是單純的 LLM 包裝,而是能把 AI、外部工具與應用流程整合起來,真正打造出實用且可持續擴充的內容生產助手。
本系列文已正式出版為《Node.js 生成式 AI 應用開發實戰:實作 OpenAI API × LangChain × LangGraph × RAG,打造從雲端到本地 LLM 的混合式安全架構》。內容全面升級,提供更完整的實戰範例與 LLM 應用架構設計。歡迎參考選購,開啟你的生成式 AI 開發之路!
天瓏網路書店連結:https://www.tenlong.com.tw/products/9786264144964


 iThome鐵人賽
iThome鐵人賽