
昨天我們完成了一個相對完整的 LangChain 實戰案例,也更深刻地體會到在開發 LLM 應用時,程式執行結果往往不是單一步驟的產物,而是由多個提示詞、工具、API 呼叫以及資料處理流程組合而成。一旦流程變得複雜,若中間某個環節出錯,往往很難憑肉眼或最終輸出結果判斷是哪裡出了問題。
這些問題在單步測試時可能沒那麼明顯,但在多步驟的 AI 流程中,任何一個細節出錯都可能讓整個應用的回應變得奇怪或失效。因此,我們需要一套能夠完整觀察與記錄 AI 應用執行過程的方式,協助我們快速定位並解決問題。
在開發 LLM 應用的過程中,流程往往由多個步驟組成,例如提示詞設計、外部 API 呼叫、資料處理與結果組合。這也意味著任何一個環節出錯,都可能影響到最終輸出。我們常會遇到以下情況:
若缺乏完善的觀察機制,開發者往往只能依靠猜測,或在程式中插入大量 console.log() 來排查問題。這種方式不僅耗時,還可能在流程複雜時遺漏關鍵細節,導致問題難以重現或持續存在。
有了流程觀察機制,開發者能更容易做到:
流程觀察的核心目的,就是讓每個步驟的輸入、輸出與執行狀態透明化,讓我們在 AI 應用開發中更快找到問題並持續優化系統。
為了協助開發者更有效地追蹤與分析 LLM 應用的運作過程,LangChain 內建了多種觀察與記錄機制,其中最常用的包括:
透過這些觀察工具,開發者能夠以結構化方式全面掌握 AI 應用的運作脈絡。不論是快速驗證功能,還是深入分析效能,你都能更清楚地理解應用程式「背後到底發生了什麼事」。
在本地開發階段,最直接的除錯方式就是把每個元件的輸入與輸出完整印在 Console 上,方便觀察模型的提示詞、回應內容與中間處理狀態。
LangChain 內建了 Verbose 模式,能自動輸出這些資訊,開啟方式也非常簡單。
若專案已透過 dotenv 套件載入環境變數,只需在 .env 檔案中加入:
LANGCHAIN_VERBOSE=true
這樣就能全域啟用 Verbose 模式,在所有 LangChain 元件執行時自動輸出詳細資訊。
若只想針對特定元件開啟詳細輸出,可以在建立物件時指定 verbose: true:
import { ChatOpenAI } from "@langchain/openai";
const llm = new ChatOpenAI({
model: 'gpt-4o-mini',
verbose: true, // 僅針對這個 LLM 啟用
});
這樣就能避免全域輸出過多資訊,聚焦在需要檢查的部分。
以下是一個最小範例:
import { ChatOpenAI } from '@langchain/openai';
const llm = new ChatOpenAI({
model: 'gpt-4o-mini',
});
llm.invoke('Hello, World!');
若有啟用 LANGCHAIN_VERBOSE=true 或 verbose: true,執行後會在終端機看到類似輸出:
[llm/start] [1:llm:ChatOpenAI] Entering LLM run with input: {
"messages": [
[
{
"lc": 1,
"type": "constructor",
"id": [
"langchain_core",
"messages",
"HumanMessage"
],
"kwargs": {
"content": "Hello, World!",
"additional_kwargs": {},
"response_metadata": {}
}
}
]
]
}
[llm/end] [1:llm:ChatOpenAI] [1.50s] Exiting LLM run with output: {
"generations": [
[
{
"text": "Hello! How can I assist you today?",
"message": {
"lc": 1,
"type": "constructor",
"id": [
"langchain_core",
"messages",
"AIMessage"
],
"kwargs": {
"content": "Hello! How can I assist you today?",
"additional_kwargs": {},
"response_metadata": {
"tokenUsage": {
"promptTokens": 11,
"completionTokens": 9,
"totalTokens": 20
},
"finish_reason": "stop",
"model_name": "gpt-4o-mini-2024-07-18",
"usage": {
"prompt_tokens": 11,
"completion_tokens": 9,
"total_tokens": 20,
"prompt_tokens_details": {
"cached_tokens": 0,
"audio_tokens": 0
},
"completion_tokens_details": {
"reasoning_tokens": 0,
"audio_tokens": 0,
"accepted_prediction_tokens": 0,
"rejected_prediction_tokens": 0
}
},
"system_fingerprint": "fp_8bda4d3a2c"
},
"id": "chatcmpl-CCMwGYzDokpNDIvgk2kh7yDgQrLI1",
"tool_calls": [],
"invalid_tool_calls": [],
"usage_metadata": {
"output_tokens": 9,
"input_tokens": 11,
"total_tokens": 20,
"input_token_details": {
"audio": 0,
"cache_read": 0
},
"output_token_details": {
"audio": 0,
"reasoning": 0
}
}
}
},
"generationInfo": {
"finish_reason": "stop"
}
}
]
],
"llmOutput": {
"tokenUsage": {
"promptTokens": 11,
"completionTokens": 9,
"totalTokens": 20
}
}
}
透過 Verbose 模式,我們可以驗證模型實際收到的提示詞是否正確,並直接觀察回應內容與資料結構,確認格式是否符合後續需求。同時,它也會輸出 Token 使用量與請求耗時,方便在開發階段監控效能並評估是否需要調整提示詞或模型參數。
實務上,開發時建議啟用 Verbose 模式以便即時追蹤與定位問題;但在正式部署時應將其關閉,以避免日誌過於龐大並降低敏感資料外洩風險。若只需檢查特定模組,也可在程式碼中針對單一鏈或模型啟用 verbose: true,以減少不必要的輸出干擾。
在開發階段,Verbose 模式是一個方便的除錯工具,可以即時在終端機輸出每個步驟的輸入、輸出與執行細節。不過,一旦進入生產環境,它的限制就會浮現:輸出內容龐大且持續累積,不利於長期保存與檢索;同時,終端機輸出的資訊也不適合用於跨團隊協作與系統化分析。
因此,當 LLM 應用上線後,我們需要一種更適合長期維運的觀察機制,能將執行過程結構化保存並支援回溯分析,而這正是 LangSmith 發揮價值的地方。
LangSmith 是 LangChain 官方推出的雲端可觀測平台,專門用來完整記錄 LLM 應用的執行過程。它會將每一次執行的提示詞、模型回應、Token 使用量、耗時統計,以及整個鏈(Chain)或代理(Agent)的流程,結構化地保存到雲端,並透過後台提供可視化介面與搜尋功能,方便檢索與分析。
與本地的 Verbose 模式不同,LangSmith 不會將資料直接輸出到終端機,而是集中管理在雲端後台。開發者可以隨時回溯歷史記錄、重播執行情境,甚至比較不同版本的提示詞效果。這讓它即使在應用已部署上線後,仍能精準追蹤流程、檢查提示詞內容、分析效能瓶頸,非常適合用於生產環境的長期監控與團隊協作。
在使用 LangSmith 前,需要先建立並設定 API 金鑰,讓本地端的 LangChain 應用能將執行資料安全地傳送到雲端平台。
以下是取得 API 金鑰的步驟說明。
前往 LangSmith 並註冊登入;LangSmith 支援 US 與 EU 兩個區域,企業若有資料駐留需求可選擇 EU。區域建立後目前不支援跨區搬遷,請在建立時就選好。
登入 LangSmith 之後,請點選側邊欄的「Settings」。
進入 API 金鑰管理頁後,可以點選右上方「+ API Key」按鈕建立 API 金鑰。
LangSmith 目前提供「Service Key」與「Personal Access Token」兩種型態,皆可用於呼叫 API;建立時可以設定到期日(或永不過期)。
API 金鑰建立完成後,系統只會顯示一次金鑰內容。請立即複製並安全保存,避免遺失或外洩。
如果專案已透過 dotenv 套件載入環境變數,你只要在專案的 .env 檔案中加入:
LANGSMITH_TRACING="true"
LANGSMITH_API_KEY=your_langsmith_api_key
# 可選:不設定會用 default
LANGSMITH_PROJECT=My-AI-Debug-Project
建立一個最小的測試程式,呼叫一次模型 API。
如果環境變數正確,執行資料會自動送到 LangSmith:
import { ChatOpenAI } from '@langchain/openai';
const llm = new ChatOpenAI({
model: 'gpt-4o-mini',
});
llm.invoke('Hello, World!');
若環境變數設定正確,執行資料會自動送到 LangSmith。
回到 LangSmith 後台,即可在指定的 Project 中看到新的 Trace/Run,其中包含提示詞、模型回應、耗時與 Token 使用統計。
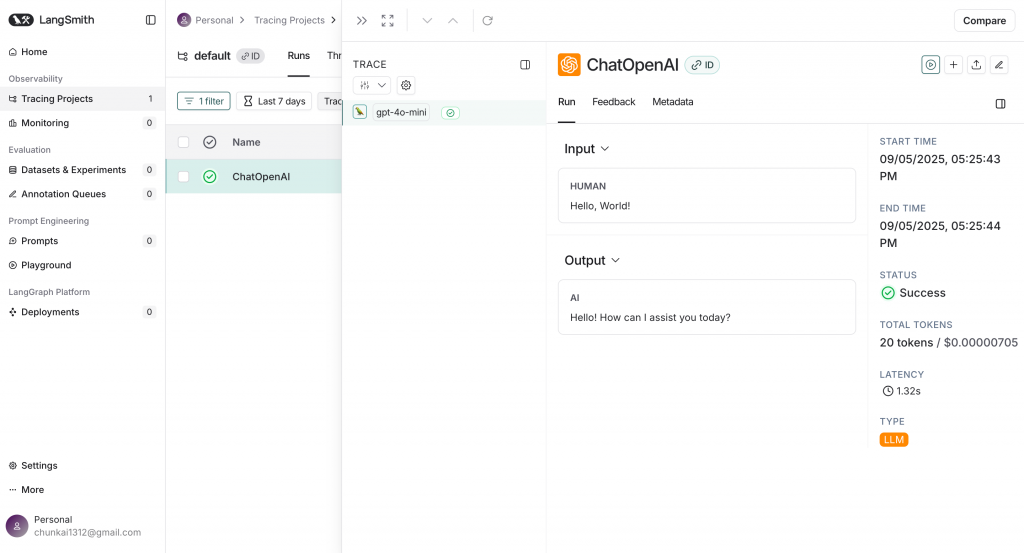
Note:除了 LangChain 官方推出的 LangSmith,社群也提供了開源方案 Langfuse,同樣具備 LLM 的可觀測與分析能力。它的特色在於可自行部署,彈性高且資料掌控度完整,特別適合需要自建基礎設施或重視資料隱私的團隊。不過在本系列中,我們主要聚焦在 LangChain 生態系,有興趣的讀者可進一步探索 Langfuse。
今天我們介紹了如何透過 LangChain 提供的 Verbose 模式 與 LangSmith 來提升 LLM 應用的觀察性與除錯效率:
LANGCHAIN_VERBOSE=true 或在 LangChain 元件中設定 verbose: true 來啟用。LANGSMITH_TRACING, LANGSMITH_API_KEY, LANGSMITH_PROJECT)。總結來說,Verbose 幫助我們在開發中快速除錯,而 LangSmith 則讓應用在上線後仍能持續被觀察與優化,兩者搭配能有效提升 LLM 系統的可靠性與可維運性。
本系列文已正式出版為《Node.js 生成式 AI 應用開發實戰:實作 OpenAI API × LangChain × LangGraph × RAG,打造從雲端到本地 LLM 的混合式安全架構》。內容全面升級,提供更完整的實戰範例與 LLM 應用架構設計。歡迎參考選購,開啟你的生成式 AI 開發之路!
天瓏網路書店連結:https://www.tenlong.com.tw/products/9786264144964


 iThome鐵人賽
iThome鐵人賽