Moon:「經過上次的說明,我總算對 PM 職能有點基本認識了!但是,基本認識了以後,只是了解而已,我的雙手還是沒法獲得解放阿~」
黛西:「沒關係!接下來我們可以先來循序漸進的認識一些 AI 工具,並了解他們可以如何應用!」
Moon:「黛西!我超期待的!但...要怎麼開始啊?面對那些聽起來很厲害的 AI 工具,我還是有點陌生,不知道該從哪裡下手耶!😳」
黛西:「沒問題!我們可以一起從簡單的大型語言模型來了解!」
黛西帶你回到現場~
你是不是也有 Moon 的困惑,覺得 AI 聽起來很棒,但一想到要開始用,就覺得有點不知如何開始,對 AI 工具感到陌生 ,甚至有點小小的焦慮呢?別擔心!這完全是正常的!
就像黛西當初一樣,一切的改變總是需要一個起點,對吧? 今天,我們就來啟動我們的第一個AI助手:大型語言模型!
什麼是大型語言模型呢?
大型語言模型 (Large Language Models, LLMs) 是一種人工智慧,能夠理解、生成和處理人類語言,透過分析和學習大量資料來運作,這些資料可能來自書籍、文章、網頁等。
我們可以把 LLMs 想成是一個博學又擁有強大語言組織能力的機器人,但要注意的是,它們的回應都是來自於訓練資料,所以會依照提供資料的時間點或內容,就跟人類唸書一樣,讀完書後對他進行提問,回答的內容都是依據「記憶」來回答,有時可能會產生不準確或錯誤的資訊,也就是所謂的「幻覺」(hallucinations)。
我的第一個AI助手:與大型語言模型對話
現在最受歡迎、也最容易上手的 AI 工具,就是能和我們「對話」的大型語言模型(Large Language Models, LLMs) 了!你可以把它們想像成自己最有耐心、24小時待命的「協作夥伴」,隨時準備好回答你的問題、協助你處理任務,甚至是陪你腦力激盪。
大型語言模型的訓練與文字回應基礎
大型語言模型(LLMs)的生成和訓練是一個相當複雜的過程,為了能比較好的使用他,我們先初步了解一下他的原理,我們可以將他的訓練主要邏輯拆解成三個核心概念:預測、Transformer 架構 和 訓練資料 。
⭐LLM 的運作核心非常簡單,就是:根據前面出現的詞,預測下一個最有可能出現的詞是什麼。
舉例來說,當我們輸入了:「今天天氣真…」,模型會根據它所學過的龐大文本,可能會先判斷出「好」或「糟」是往下出現機率最高的詞。這個過程不斷重複,每次都根據當前已生成的文字,來預測下一個詞,最終形成一個完整的句子、段落,甚至是整篇文章。
Transformer 是由 Google 在 2017 年所提出的神經網路架構,它徹底改變了 LLM 的發展。在此之前,模型處理語言時需要依賴順序(例如:RNNs),但這會讓處理長篇文章變得非常困難且低效。
Transformer 的關鍵在於它的 「注意力機制」(Attention Mechanism) 。它讓模型在生成某個詞時,能同時考慮到輸入文本中所有其他詞的重要性,而不再是單純地依賴順序。
舉個例子,當我們閱讀一個長句:「我把書放在桌子上,然後它不見了。」在判斷「它」指的是什麼時,應該要能夠判斷這個「它」其實是前面提到的「書」這個詞。Transformer 做的就是類似的事,它能快速地在大量內容中,找出與當前詞語最相關的其他詞,這會讓模型能夠理解更複雜的上下文和更長的句子。
⭐LLM 的訓練過程可以分為兩大階段:
階段一:預訓練(Pre-training)
這是最耗時也最昂貴的階段。研究人員會將模型「餵食」數以兆計的文本資料,這些資料來自於網路、書籍、維基百科等。模型在這個過程中會學習語法、詞彙、事實知識和各種語言模式,就像一個嬰兒透過大量閱讀來學習一樣。
預訓練的目標,就是讓模型能精準地完成「預測下一個詞」的任務。
階段二:微調(Fine-tuning)
預訓練完成後,模型雖然學會了語言,但還不擅長應對特定的任務,例如:回答問題、寫詩或遵循指令。
微調就是讓模型在更小、更專業的資料集上進行訓練。這一步通常會使用標註過的對話資料,讓模型學會如何以更有用、更安全的對話方式回應人類。這個過程也稱為人類回饋強化學習(RLHF, Reinforcement Learning from Human Feedback) ,是讓模型變得更像「對話助理」的關鍵。
舉例來說,很多工程師夥伴,在開發時會常使用 Claude,這是因為 Claude 在針對產出 Code 的這部分能力有被微調過,所以產出的程式碼,會比較符合工程師所需要的內容。
總結來說,LLMs 的核心邏輯是透過 Transformer 架構 ,從海量的預訓練資料 中學習如何預測下一個詞 ,最後再透過微調來讓它能應對更複雜的指令。
如何與大型語言模型進行有效的對話
與LLMs對話,就像是與一個很聰明,但需要你清晰引導的同事溝通。關鍵在於**「有效地提問」** 。這聽起來可能很簡單,但要怎麼讓 AI 看得懂,這也是一門學問。
常見大型語言模型比較
現在市面上很多不同的大型語言模型,以下整理了幾個常用的推薦工具:Google Gemini ,ChatGPT ,Claude ,Perplexity。這些工具各有千秋,選擇適合自己的,就是最好的「神隊友」!
表格一:四款大型語言模型比較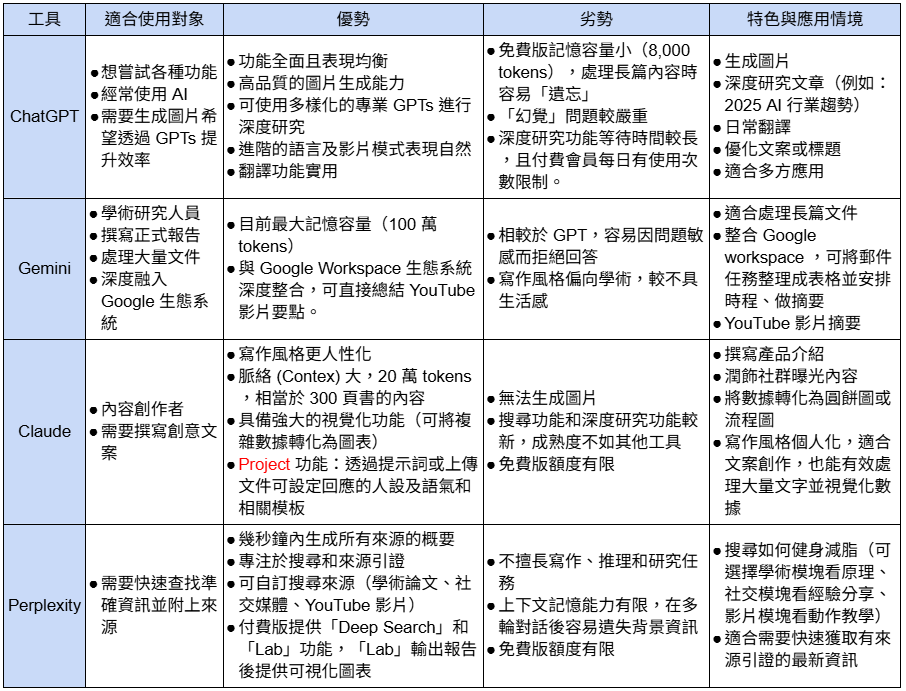
表格二:四款大型語言模型之免費、付費與適合升級對象整理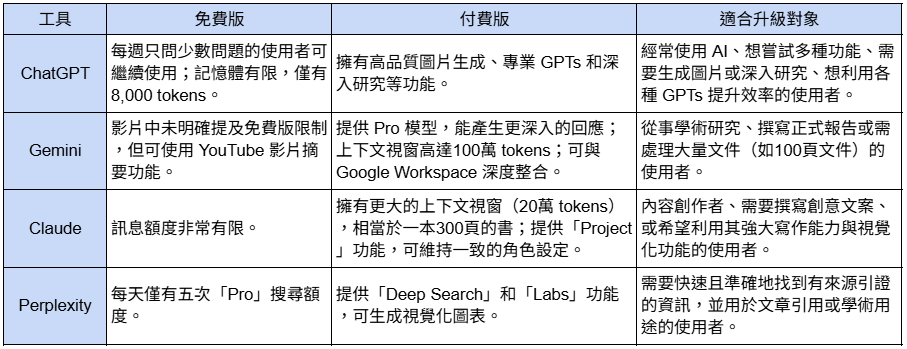
⭐⭐簡要總結 ⭐⭐
重點在問對問題
許多人初次接觸 AI 時的痛點:AI 輸出的內容不符合預期,需要反覆調整,最終心力交瘁,覺得 AI 既不聰明也不好用。 但問題的核心,或許不在 AI,而在於我們「提問的方式」。 給的指令(Prompt)越清晰、越具體,所回饋的成果就越有價值。
告別無效溝通:優質提示(Prompt)的五大黃金要素
一個好的提示詞( Prompt),就像一份清晰的專案簡報。與其給出模糊的指令,不如從一開始就建立好框架,提供清楚的背景資訊。根據與 AI 協作的最佳實踐,一份優質的提示,應該包含以下五個關鍵要素:
4.背景資訊 / 限制條件 (Context / Constraints)
5.格式 (Format)💥重要但非必要💥
實戰演練:從「初階」到「進階」的提示詞改造
⚡範例1
✌️ 初階的提示:
請幫我為即將上市的保養品製作一份行銷活動的策略簡報。
👍 進階的提示:
[人物設定] 你是一位品牌經理。[任務] 請幫我為即將上市的保健食品製作一份行銷活動的策略簡報。[受眾] 目標受眾是需要長期身體保養的銀髮族的家人。[背景資訊 / 限制] 我想做一些創新和有創意的事來提升品牌偏好。[格式] 請以標題和條列式來回覆。
⚡範例2
✌️ 初階的提示:
「進行智慧手錶產業的競品分析。」
這樣的提示太過模糊,AI 只能給我們一份泛泛的網路資料整理。
👍 進階的提示:
[人物設定] 你是市場研究分析師。[任務] 請進行智慧手錶產業的競品分析。[受眾] 我是產品經理,我的公司正在探索智慧手錶市場,這個分析對我來說要有所助益。[背景資訊 / 限制] 只要分析智慧手錶產業的前五大競爭者,並著重於 2024 年第一季的數據。 [格式] 把分析結果彙整成一個表格,欄位包含公司名稱、定價、優勢、目標受眾和市場佔有率。
透過提供完整的五大要素,我們將一個模糊的需求,轉化成一個清晰、可執行的任務。AI 的產出將不再是隨機的資料拼湊,而是一份結構化、符合你需求的初步分析報告。這就是「說對話」的威力:可透過建立提示草稿、測試、再修改的迭代過程,逐步打磨出最優質的指令。
Moon:「哇!原來跟 AI 說話也是有技巧的耶!而且還有這麼多不一樣的 AI 助手可以選,感覺好像在玩遊戲,可以用不同的指令去探索它們的能力!我迫不及待想試試看了!🤩」
黛西:「沒錯!這就是打破框架的開始!透過不斷的嘗試、學習,並且內化為自己的知識,就能突破以往的工作框架,達到工作上的成長與成就感!準備好讓你的AI助手上線了嗎?Let's AI!Go!🚀

