想像你正在異地旅行。早上原本要去戶外景點,但一出門發現下雨,整個計畫被打亂。如果此時有個智慧助手,它能即時查天氣、重新規劃路線,甚至找到附近的咖啡館避雨——這就是我們對 Agentic AI 的期待:不只是單步回答,而是能隨環境動態調整,持續幫助你達成目標。
然而問題來了:要打造這樣的智慧助手,我們究竟該走哪條路?
這正是今天要回答的問題:為什麼我們選擇 LLM 作為 Agent 的基礎,而不是一開始就重訓或微調模型。
還記得 AlphaGo 橫掃世界冠軍的那一年嗎?
它靠 強化學習 自我對弈、修正策略,最終在圍棋這個明確規則的領域達到超越人類的水準。當時許多人認為,這就是智慧 Agent 的未來。
RL 的流程看似簡單:
在棋局裡,獎勵函數很明確:贏就是 +1,輸就是 -1。
但如果要把 RL 用在旅行規劃呢?獎勵該怎麼設?是預算最省?景點最多?還是舒適度最高?這些標準模糊、多維度,難以量化。
換句話說,RL 很強,但它的強項是 封閉、單一標準的環境。一旦進入複雜、多元的人類世界,設計成本與訓練門檻都變得極高。
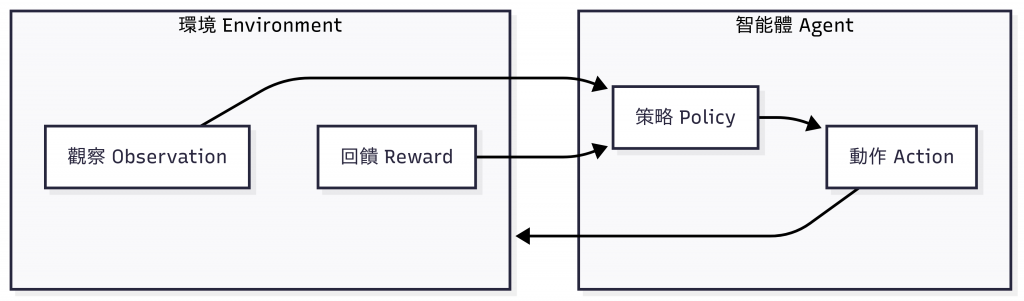
圖:強化學習(RL)的 Agent–Environment 架構。此閉環在棋盤等封閉環境效果卓越,但在旅行規劃等開放任務上設計成本極高。
眼尖的朋友可能會發現,這張圖其實和 昨天 (Day 2) 所講的 Agentic AI 的運作概念很相似:同樣是「觀察 → 行動 → 回饋 → 策略修正」的循環。
差別在於,RL 必須透過明確定義的獎勵函數與環境模擬來推進,而 Agentic AI 則能藉由 LLM 所帶來的語言理解能力,並透過工具、記憶與規劃等機制,去處理開放且複雜的真實環境。
若要用 RL 訓練一個「維也納旅行 Agent」,幾乎得為每一位旅客重建一個環境並訓練,難以普及。
大型語言模型(LLM) 帶來了轉折。
LLM 的本質是「基於機率分布、不斷進行文字接龍來生成下一個字」的強大預測器;然而,因為訓練語料涵蓋了龐大的知識與語境,它意外地展現出理解與推理的能力,能處理各種開放性問題,而不需要像 RL 那樣事先定義所有狀態與獎勵。
更重要的是,LLM 提供了三個關鍵優勢:
講到這裡,可能有人會問:既然 RL 在現實任務上不易直接落地,那是否可以透過 重新訓練(Pre-training) 或 微調(Fine-tuning, SFT/RLHF),打造一個更專屬的 Agent 模型?
這確實是一條可能的路,只是以「今天要快速打造能用的 Agent」為目標,重新訓練或微調並不是最務實的起點:
相比之下,善用現成的 LLM(例如 ChatGPT、Gemini、Claude、Llama 等)更有彈性:
換句話說,現階段最好的策略不是「一開始就重訓模型」,而是「讓現有的 LLM 逐步學會當 Agent」。
等到我們累積了更多經驗與需求,或許才會進一步用 SFT 來優化行為,甚至重新設計 RL 框架 來提升特定能力。
前三天我們主要談的是 「為什麼」:
Day 1|啟程!踏上 Agentic AI 的探索之旅
→ 從動機出發,說明為什麼需要 Agentic AI。
Day 2|從工具到夥伴:Agentic AI 的核心能力與設計模式
→ 建立能力樹與設計模式的藍圖。
Day 3|為什麼是 LLM?從強化學習到語言模型的轉折
→ 解釋為什麼選擇以 LLM 為基礎,而不是一開始就走 RL 或重新訓練。
這三天像是完整的「啟程篇」,先釐清方向,再鋪好基礎。
接下來,從 Day 4 開始,我們將正式進入 「怎麼做」:逐步讓 LLM 學會推理、檢索、工具使用、規劃、記憶與反思,並最終具備協作與適應的能力。換句話說,從明天起,我們會把理論真正轉化為實作,一步一步養成能持續進化的 Agent。

圖:維也納史蒂芬大教堂(St. Stephen's Cathedral)在夜幕中巍然矗立,屋頂繁麗的花紋與尖塔的輪廓在黑暗裡閃耀。正如 LLM 的出現,讓智慧代理從侷限的規則系統,邁向開放而無限的真實世界。(攝影:作者自攝)


 iThome鐵人賽
iThome鐵人賽