
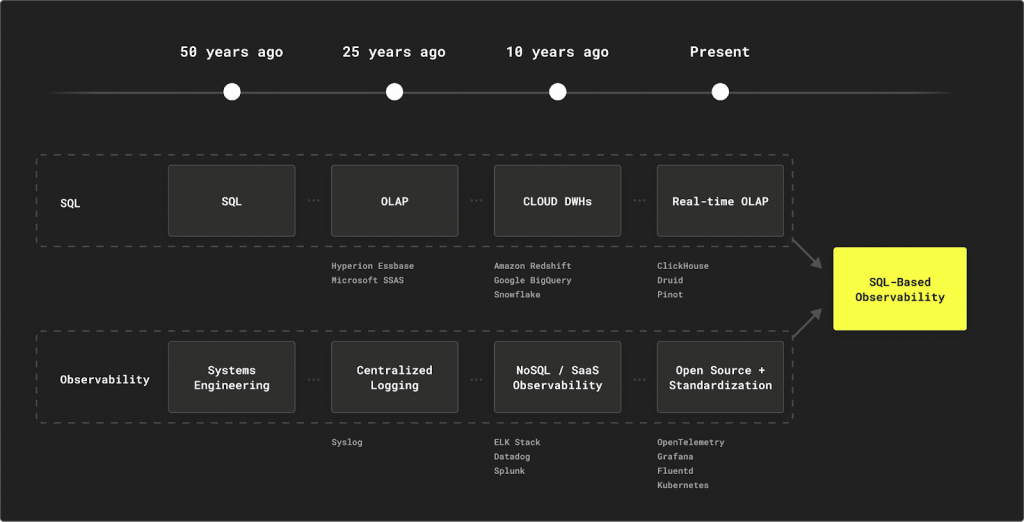
在上一篇文章中,我們探討了從傳統監控邁向『可觀測性 2.0』的關鍵轉變,其核心在於能夠應對海量、高基數的遙測資料,並進行即時的探索式分析。這對後端的資料庫提出了極為嚴苛的要求,而傳統的時序資料庫 (TSDB) 或日誌搜尋引擎已漸顯疲態。這正是 OLAP 資料庫登上舞台的時刻。
然而,在眾多 OLAP 解決方案中,為何 ClickHouse 這顆開源新星能夠脫穎而出,成為 SigNoz、Semtry、Uptrace 等新一代可觀測性平台共同的選擇?答案就在其為大規模分析而生的底層設計哲學中。

可觀測性的核心是「提出從未想過的問題」。
ClickHouse 的亞秒級查詢能力讓這種探索成為可能,而不是漫長的等待。
透過 Column-based 資料庫的強大查詢特性,我們不需要像 Row-based 資料庫般將整個 Row 讀取後才能取得眾多欄位中的少數幾個,這完整的貼合可觀測性中提倡不該限制你捨棄任何有加值的屬性,就算他是個高基數欄位。
而除了效能以外,另一個讓 2016 年才發佈的 ClickHouse 可以快速擴散到各個領域的最大原因,在於其使用了社群最熟悉的 SQL 語法為基底,而不需要為特定領域學習對應的語言如 PromQL、LogQL、TraceQL。這大大的降低了團隊學習曲線 — 你的後端工程師、數據分析師,甚至產品經理,都可以使用他們熟悉的 SQL 來探索資料,不再有語言壁壘。
可觀測性不應該成為企業的財務黑洞。
ClickHouse 透過極致的壓縮和高效的硬體效率,顯著降低成本。
ClickHouse 另一個最大的特點在於其壓縮效率帶來的成本優勢,它可以針對不同資料類型使用專門的壓縮編碼器 (Codecs),如 ZSTD、Delta、Gorilla。對於可觀測性領域統一標準的 OpenTelemetry Data Model 通常能實現 10 倍以上的壓縮比。
以 ClickHouse 官方的內部實踐為例:在比較 Datadog 與基於 ClickHouse 內部的 Log 儲存方案(LogHouse)後,他們發現 Datadog 成本高出約 200 倍,於是將所有日誌遷移至 ClickHouse。遷移後,資料保留期從 30 天提升到 180 天,每年仍可節省數百萬美元;同時將 約 19 PiB 的原始資料壓縮至 約 1 PiB,達到 約 17 倍壓縮比。
https://clickhouse.com/blog/optimize-clickhouse-codecs-compression-schema
現代應用程式的遙測資料是半結構化的,欄位會不斷變化。ClickHouse 的設計天然地擁抱這種「混亂」。
如果對於 OpenTelmetry 有初步理解的話,就會理解 OpenTelmetry 的 Attributes 設計會產生大量欄位,ClickHouse 對擁有數百甚至數千個欄位的『寬表』性能極佳,能將每個屬性映射為一個獨立的欄位進行索引和查詢。
ClickHouse 的靈活性並不止於它對寬表的親和性,還有原生對於半結構化的支援,如 JSON (Object)、Map、Array 等資料類型。你可以靈活地選擇將某些屬性攤平為欄位以獲得極致查詢效能,或將其他不常用的屬性塞進一個 Map 欄位,兼顧了效能和靈活性。
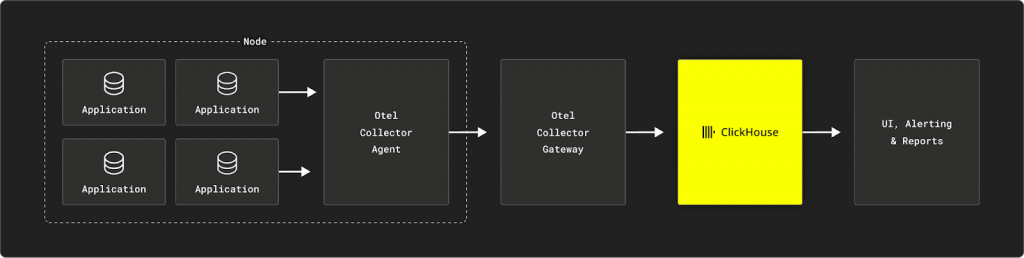
我們已經瞭解了像 ClickHouse 這樣的工具如何幫助我們處理大量可觀測性數據,使其成為專有系統之外可行的開源替代方案。基於 SQL 的可觀測性非常適合熟悉 SQL 的團隊,能夠控製成本並提高可擴展性。隨著 OTel 等開源工具的不斷發展,這種方法對於擁有大量資料需求的組織來說變得越來越實用。
基於 SQL 的可觀測性堆疊的一個關鍵元件是 OpenTelemetry Collector。 OTel Collector 從 SDK 或其他來源收集遙測數據,並將其轉發到支援的後端。它充當接收、處理和導出遙測資料的集中式樞紐。 OTel Collector 既可以作為單一應用程式的本機收集器,也可以作為多個應用程式的集中式收集器。
接下來,就讓我們一起來看看 ClickHouse 在各種應用場景下提供的完整體驗。
網路基礎設施巨擘 Cloudflare 因為其巨量的使用規模,使其不得不總是走在各種技術的最前沿,而他們在資料領域面臨的大規模資料基礎設施挑戰之一是為客戶提供 HTTP 流量分析。
2014 年,Cloudflare 的上一代 Log Pipeline 以 CitusDB 擴展 PostgreSQL(Cloudflare Analytics)為核心。該架構讓系統從一開始的每秒不到 100 萬請求,成長到每秒 600 萬;多年來表現穩定,但隨著需求改變也逐漸暴露出限制。他們意識到:系統需要在合適時機重新設計。
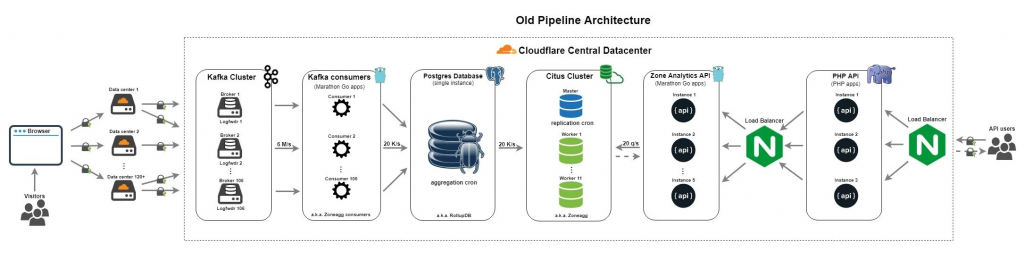
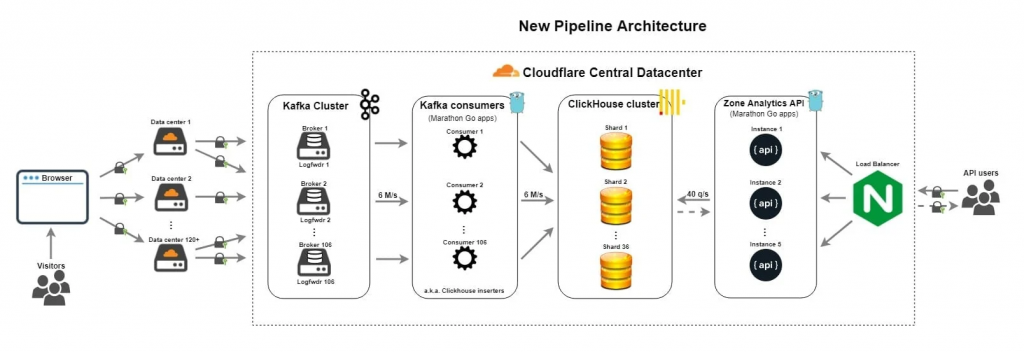
2016 年 ClickHouse 開源,Cloudflare 在 2018 年看到其潛力並啟動遷移。最終結果是:大幅簡化架構、消除 PostgreSQL 主節點單點故障(SPOF) 風險,並在更低 API 延遲下,將吞吐提升至每秒 600–800 萬請求。

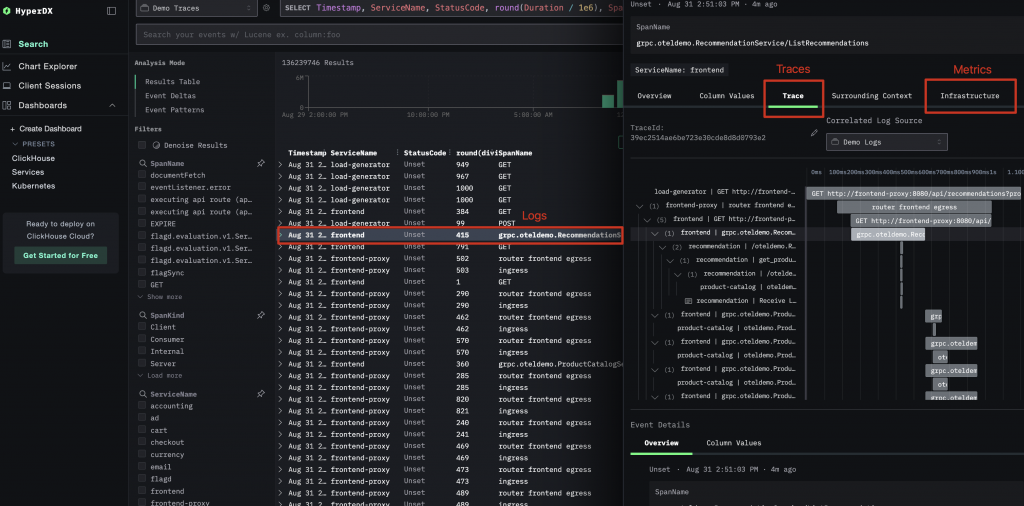
ClickStack 是 ClickHouse 官方在 2025 年五月發佈的一站式可觀測性平台,而 HyperDX 這個開源專案則是促使這個黃金組合最關鍵的拼圖。HyperDX 是一個專門基於 ClickHouse 構建的開源可觀察可視化工具,並且於 2024 年底開源了他們的 V2 UI,ClickHouse 團隊快速意識到這正式他們缺少的那塊關鍵拼圖『使用者體驗介面』,在此之前 ClickHouse 並沒有自己的專屬介面而是依附在如 Grafana 等可視化解決方案上。最終,HyperDX 與 ClickHouse 團隊達成一致的共識,在 2025 三月正式加入了 ClickHouse 團隊,並且在短短兩個月推出 ClickStack 這套 ClickHouse Cloud 上的一站式可觀測性平台解決方案。
ClickStack 基於 ClickHouse 構建生產級別的可觀測性平台,將日誌、跟踪、指標甚至是 Session 統一在一個高性能儲存後端中。ClickStack 專為監控和調試複雜系統而設計,使開發人員和 SRE 能夠端到端地跟踪問題,而無需在工具之間切換或使用時間戳或相關 ID 手動拼接數據。
ClickStack 的核心是一個簡單但強大的想法:所有可觀察性數據都應作為廣泛、豐富的事件攝取。這些事件按資料類型(日誌、追蹤、指標和會話)儲存在 ClickHouse 表中,但在資料庫層級保持完全可查詢和交叉關聯,這也一再一再與 OpenTelemetry 的精神不約合同。
當我們進入 AI 時代,特別是 LLM 大行其道時,可觀測性的維度發生了根本性的變化。我們不僅要關心延遲、錯誤率,更要關心提示 (Prompt) 的內容、回應 (Response) 的品質、Token 的消耗,甚至是 Embedding 向量之間的語義相似性。
當我們從傳統的雲原生應用邁向 AI 驅動的時代,可觀測性迎來了全新的挑戰與維度。我們關心的不再僅僅是 CPU 使用率、請求延遲和錯誤碼。對於大型語言模型 (LLM) 應用,我們迫切需要回答更複雜的問題:
這些問題的核心,是對海量、高基數、且包含語義資訊的資料進行即時分析。傳統的可觀測性工具鏈對此力不從心,而這正是 ClickHouse 發揮其獨特價值的舞台。
當我們檢視市面上新興的 LLM 可觀測性工具時,會發現一個驚人的共同點:
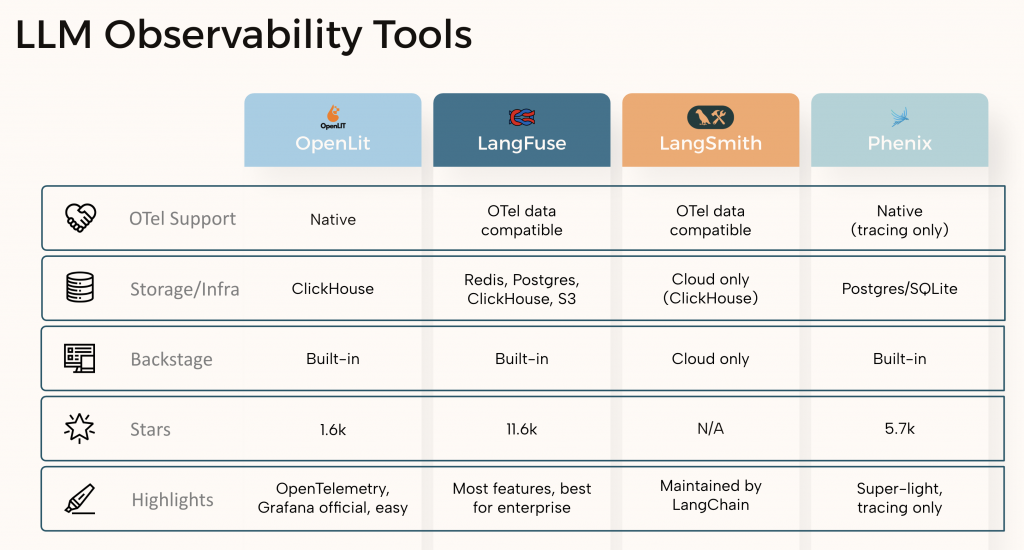
正如上圖所示,無論是 OpenTelemetry 官方推薦的 OpenLIT、功能強大的開源方案 LangFuse,還是由 LangChain 維護的 LangSmith (Cloud 版本),它們都不約而同地選擇了 ClickHouse 作為核心的儲存與分析引擎。
這絕非巧合,而是深思熟慮後的技術選型。因為要應對 LLM 應用可預見的龐大數據分析需求,只有像 ClickHouse 這樣的架構才能勝任。
更具革命性的是,ClickHouse 還可以作為一個高效能的向量資料庫。LLM 應用中的 Prompt 和 Response 可以被轉換為 Embedding 向量,這些向量在數學上代表了它們的語義。ClickHouse 內建了 L2Distance、cosineDistance 等多種距離計算函數,並支援近似最近鄰 (ANN) 索引,讓我們可以直接用 SQL 進行語義搜尋和分析。
這意味著你可以在同一個資料庫裡,無縫地執行兩種查詢:
SELECT avg(token_count)
FROM traces
WHERE app_name = 'chatbot-v2';
WITH {q:Array(Float32)} AS query_embedding
SELECT prompt
FROM traces
ORDER BY cosineDistance(prompt_embedding, query_embedding) ASC
LIMIT 5;
這種將 OLAP 分析和向量搜尋統一在單一資料庫中的能力,是 ClickHouse 的殺手級特性。它極大地簡化了 LLM 應用的技術棧,避免了在多個數據系統之間同步數據的複雜性和成本。
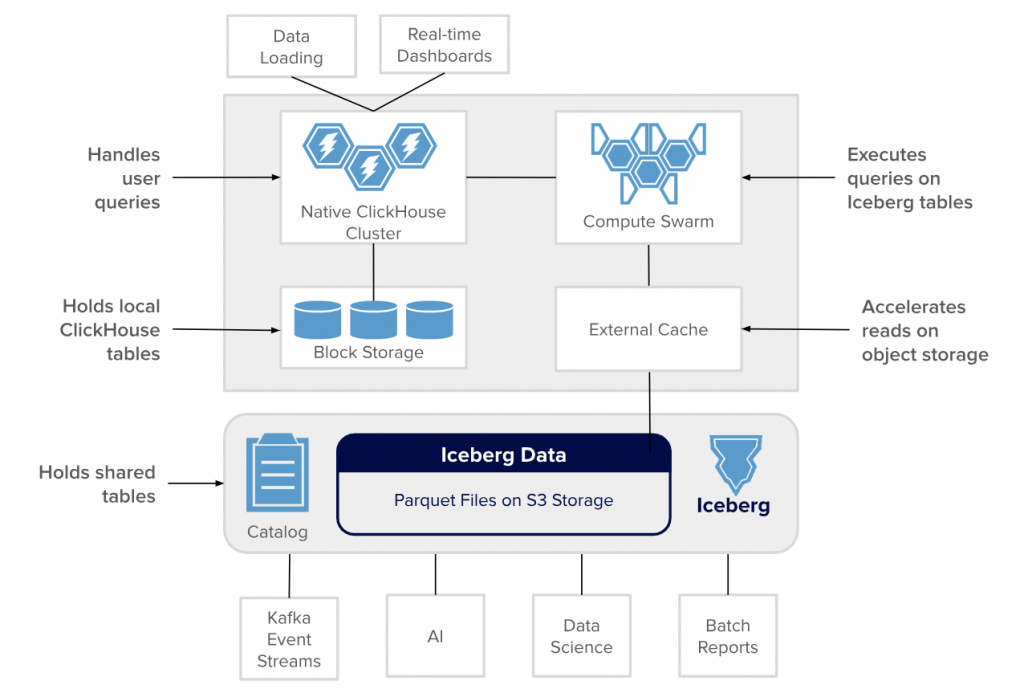
當我們討論 ClickHouse 的強大能力時,傳統上我們指的是它在自身儲存格式 (MergeTree) 上實現的極致效能。然而,Clickhouse 的未來藍圖遠不止於此。一個由 Altinity 的 ClickHouse 託管供應商發起名為 「Project Antalya」 的最新發展,預示著 ClickHouse 將演變成一個更加開放、可擴展的分析核心,而其關鍵就在於與 Apache Iceberg 的深度整合。
簡單來說,Apache Iceberg 是一種開放的表格式 (Open Table Format),專為存放在雲端物件儲存 (如 AWS S3, Google GCS) 上的龐大分析資料集而設計。它提供了一層抽象,帶來了類似傳統資料庫的可靠性、事務性 (ACID) 和時間旅行 (Time Travel) 功能,但底層資料卻是儲存在成本極其低廉的物件儲存上。
Project Antalya 的核心目標,是讓 ClickHouse 能夠直接、高效地查詢存放在 Iceberg 表中的資料。這種整合帶來了幾個革命性的優勢:
計算與儲存的終極分離 (Decoupling Compute and Storage):
這是最重要的架構演進。你可以將海量的、不常變動的歷史遙測資料或 AI 訓練資料存放在成本比本地 SSD 低數十倍的 S3 物件儲存中,並以 Iceberg 格式管理。同時,你可以根據查詢負載,彈性地擴展或縮減 ClickHouse 的計算節點。這意味著你不再需要為了儲存幾 PB 的歷史資料而維持一個龐大且昂貴的 ClickHouse 叢集。
打破數據孤島,擁抱開放生態系:
一旦你的資料以 Iceberg 的開放格式儲存,它就不再被 ClickHouse「鎖定」。同一個 Iceberg 資料表,不僅可以被 ClickHouse 查詢,還可以被 Spark、Trino、Flink、Dremio 等其他主流計算引擎存取。這為企業建立一個統一的數據湖 (Data Lakehouse) 架構鋪平了道路。例如,你的可觀測性團隊可以用 ClickHouse 進行即時查詢,而數據科學團隊可以用 Spark 在同一份數據上進行複雜的模型訓練,彼此互不干擾。
近乎無限的擴展性與成本效益:
對於可觀測性場景而言,資料量通常會隨著時間無限增長。將資料儲存在雲端物件儲存中,你幾乎擁有了無限的儲存空間。ClickHouse on Iceberg 的架構讓你可以輕鬆地保留數年的完整遙測資料以供合規性審計或長期趨勢分析,而不用擔心儲存成本失控。
到目前為止,我們可以從各種生態趨勢看出 ClickHouse 的三大優勢(速度、成本、靈活性)以及其作為統一數據平台的潛力。投資 ClickHouse 不僅僅是選擇一個資料庫,更是選擇一種能夠從容應對未來數據挑戰的現代化架構。在現今的 AI 潮流下他的聲浪不減反增,彷彿是以勢如破竹之姿宣告著它將會整個 AI 技術棧建立了一個統一、高效、且具備未來擴展性的數據基石。
ClickHouse 不僅是自帶體系的生態王者,更準備好成為更廣闊、更開放的現代數據棧中的核心計算層。這項投資不僅僅是為了解決今天的可觀測性問題,更是為企業未來十年的數據架構打下了一個堅實、開放且極具成本效益的基礎。
References:

