
前些陣子,社群上開始興起了 RAG 已死的言論,因為主流大模型的 Token 窗口已經大幅度的成長到百萬級別,足以消化大部分的資料並即時回應。這也使得一部分的文章開始鼓吹這種極度搏眼球的行銷話題。
但研究顯示,RAG 並非消亡,而是持續演化,它正在適應大型 LLM 擴展後的更大上下文能力,同時在處理龐大且動態的資料集時依然不可或缺。由向量資料庫驅動的語義搜尋仍然在人工智慧中扮演關鍵角色,因其能以高效率進行基於相似度的檢索。然而,業界討論的焦點也逐漸轉向具備自主推理能力的 Agent 系統。各種證據顯示,混合式架構依然佔據優勢,甚至更加被器重。因為它在複雜查詢情境中平衡完整上下文處理與資料檢索能力,並在技術創新存在多種優化路徑。
儘管有人宣稱,隨著 LLM 上下文視窗擴展(例如 Gemini 的上下文長度達 200 萬 tokens),RAG 已無用武之地,但事實上 RAG 正在演化成更進階的型態,例如「Agentic RAG」。在這種架構下,LLM 能夠協調多步驟的資料檢索與工具調用,在企業級應用場景中,大幅提升回應的準確性與深度。
RAG 的核心價值主張因此依然明確且不可或缺:
這背後強大的檢索能力,有很大的一部分正是由語意搜尋所驅動,而語意搜尋的基石,就是我們接下來要深入探討的主題「向量資料庫」。
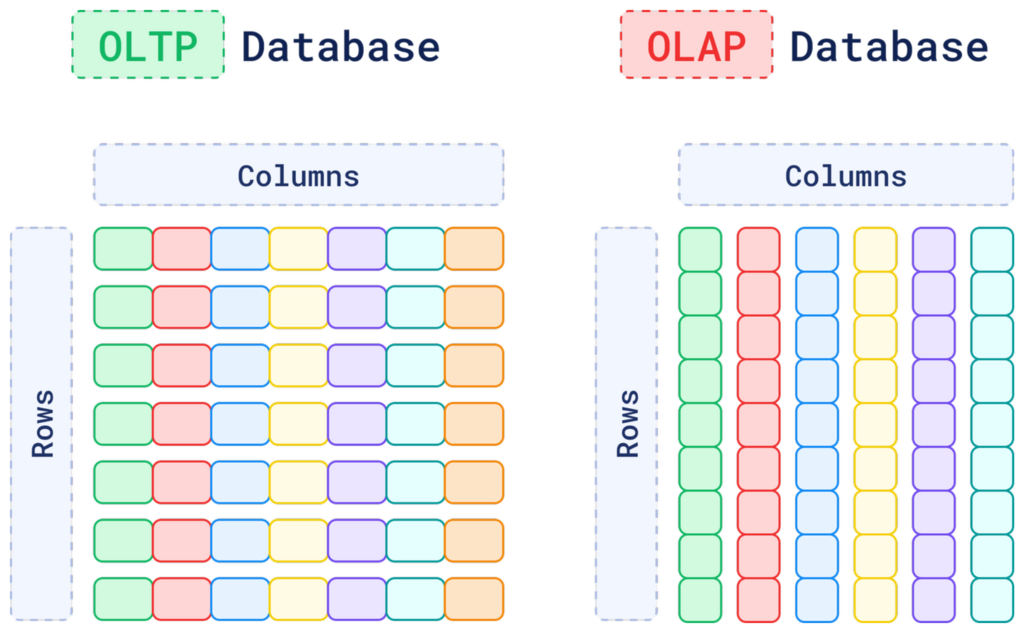
數十年來,我們的數位世界建立在兩類主要的資料庫之上:OLTP (線上交易處理) 和 OLAP (線上分析處理)。
這兩者共同構成了結構化資料的堅固堡壘,但面對今日爆炸性增長的非結構化資料的文字、圖片、音訊、影片,它們卻顯得力不從心。
傳統資料庫可以儲存一張圖片的檔案,卻無法「理解」圖片裡是一隻貓還是一隻狗;它可以儲存一份 PDF 文件,卻無法理解文件內容的語意。當你的搜尋需求從「找出訂單編號 12345」變成「找一些和這張圖片風格類似的圖片」時,傳統資料庫就束手無策了。
這正是向量資料庫應運而生的契機。它不關心資料的格式,只關心資料的語意和上下文。
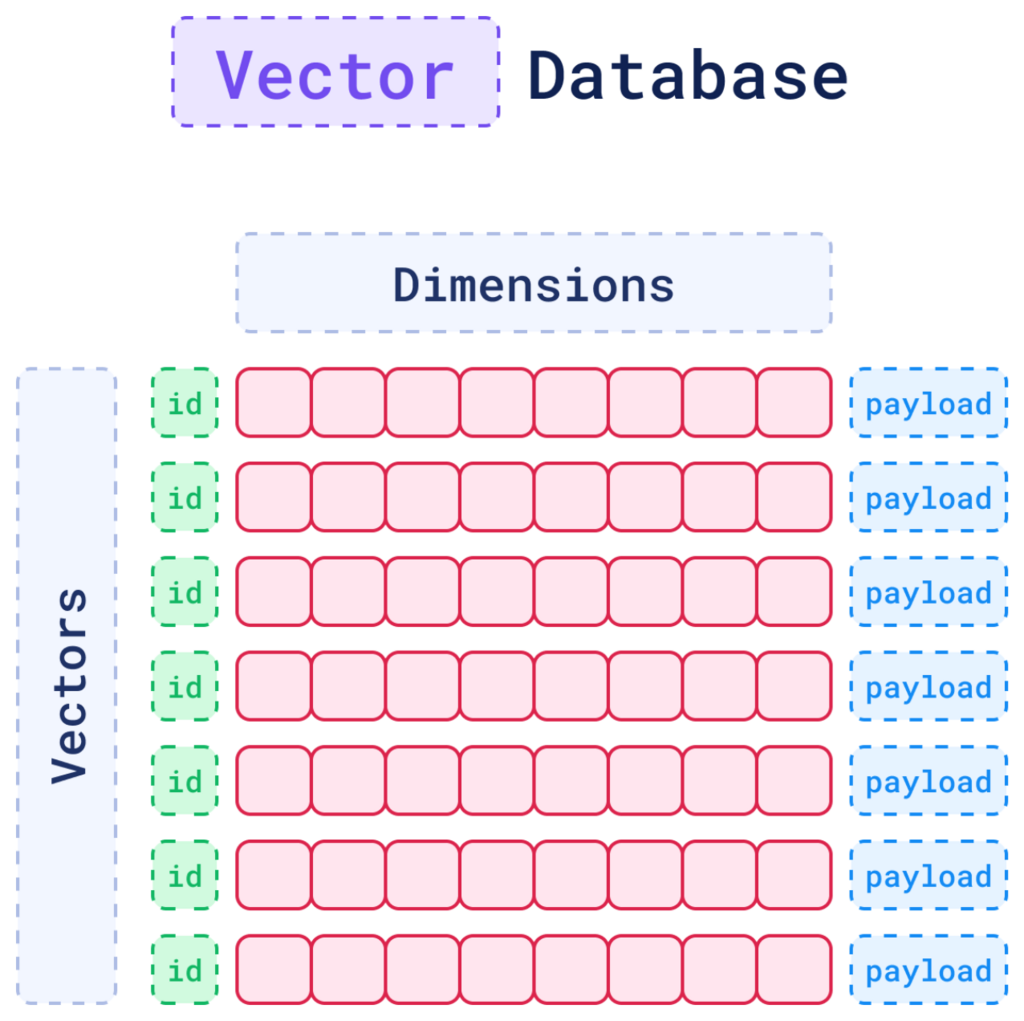
向量資料庫是一種專門設計用來儲存、管理和搜尋「向量嵌入 (Vector Embeddings)」的資料庫。
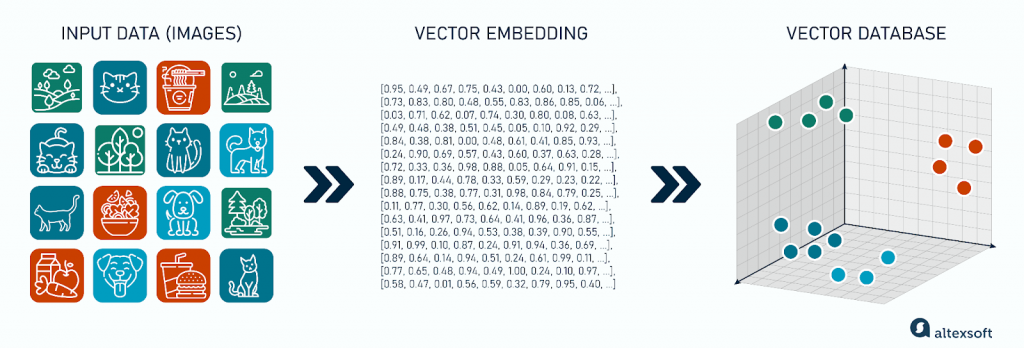
不同於儲存行列分明的表格資料,向量資料庫將所有資料,無論是文字、圖片還是聲音都可以轉化為一串數字,即「向量」。
可以把它想像成一個巨大的多維空間,每一個資料點(例如,一句話、一張圖片)都被轉換成這個空間裡的一個點(向量)。這些點的奇妙之處在於,它們在空間中的相對位置代表了它們在語意上的關聯性。「貓」和「小貓」的向量在空間中會非常接近,而「貓」和「汽車」的向量則會相距甚遠。
| 特徵 | OLTP 資料庫 | OLAP資料庫 | 向量資料庫 |
|---|---|---|---|
| 資料結構 | 列和行 | 列和行 | 向量 (多維空間中的點) |
| 資料類型 | 結構化 | 結構化/部分非結構化 | 非結構化 |
| 查詢方法 | SQL (精確匹配) | SQL (聚合、分析) | 向量搜尋 (基於相似性) |
| 儲存焦點 | 交易與更新 | 讀取與分析 | 上下文與語意 |
| 核心用途 | 訂單處理、CRM | 商業智慧、資料倉儲 | 相似性搜尋、推薦系統、RAG |
https://www.altexsoft.com/blog/vector-database/
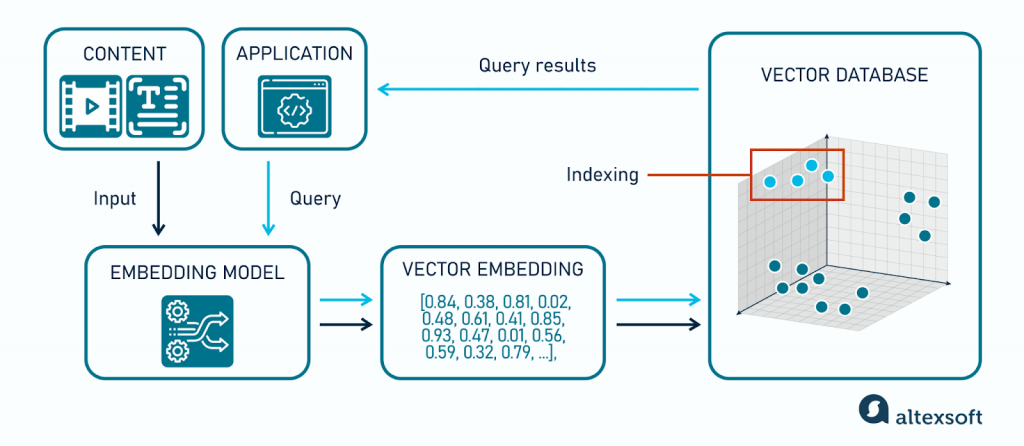
要真正理解向量資料庫的運作方式,讓我們跟隨一個電影推薦系統的完整流程。這個例子將生動地展示從資料輸入到結果輸出的每一步。
旅程的起點是「內容」。假設你剛剛在串流平台上看完了一部電影《全面啟動》(Inception)。
現在,當你回到首頁,應用程式 (Application) 需要為你推薦下一部電影時:
透過這個簡單的流程,向量資料庫就完成了一次從理解非結構化資料(電影資訊)到執行複雜語意查詢(推薦品味相似的電影)的魔法。現在,我們已經掌握了它的運作全貌,接下來將深入其內部,揭開讓這一切變得高效的演算法秘密。
https://www.altexsoft.com/blog/vector-database/
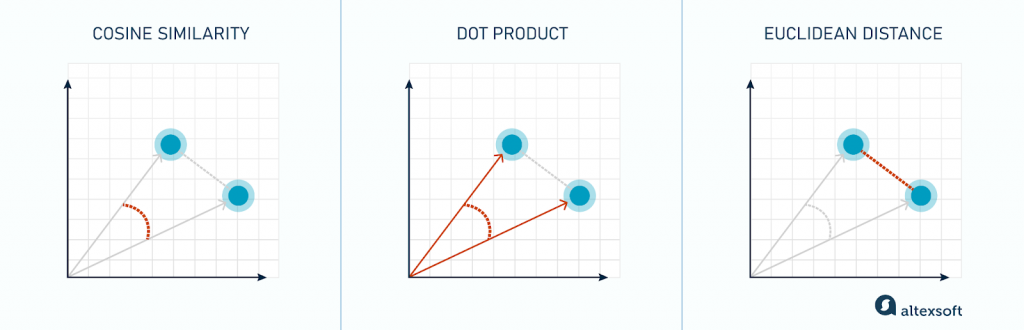
「距離最近」這個概念,是透過相似性度量 (Similarity Measures) 來實現的。 這是決定向量間關係的數學基礎,常見的度量方式有:
餘弦相似度 (Cosine Similarity):計算兩個向量之間的夾角。夾角越小,相似度越高。它只關心方向而不關心大小,非常適合用於比較文本內容的語意。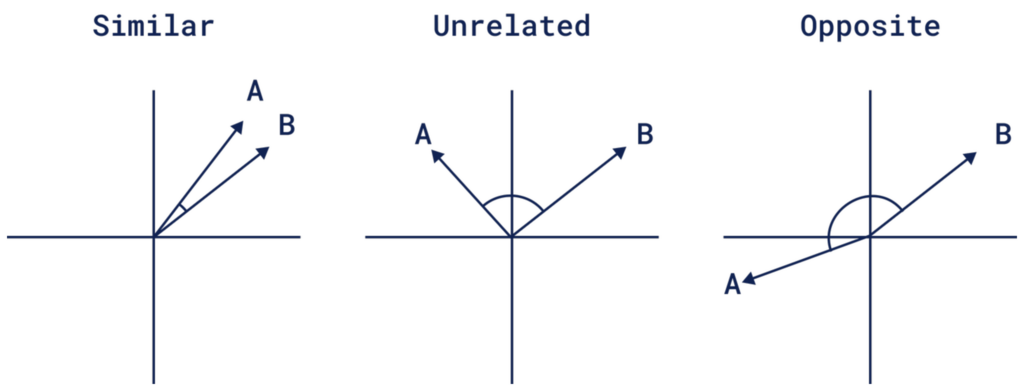
歐氏距離 (Euclidean Distance):計算兩個向量在多維空間中的直線距離。距離越近,表示越相似。
點積 (Dot Product):同時考慮了向量的角度和大小(模長),在某些推薦系統場景中非常有效。
https://www.altexsoft.com/blog/vector-database/
當資料庫中有數百萬甚至數十億個向量時,逐一比較查詢向量與庫中每個向量的距離(即暴力搜尋)是極其耗時且不切實際的。為了解決這個問題,向量資料庫採用了近似最近鄰 (Approximate Nearest Neighbor, ANN) 演算法來建立索引。
ANN 的核心思想是:犧牲一點點的準確性,來換取巨大的查詢速度提升。 它不會保證 100% 找到最接近的那個點,但能以極高的機率找到非常接近的點,而這在大多數應用中已經足夠。
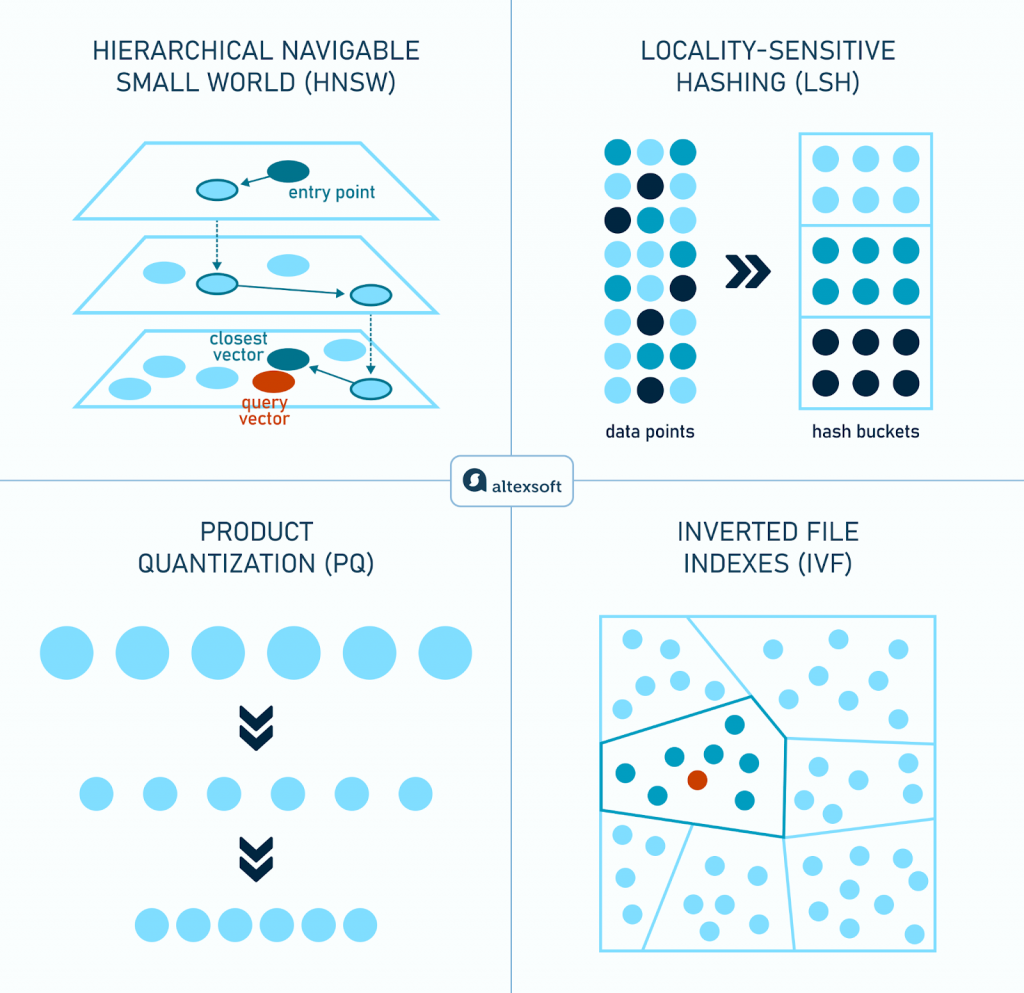
索引 (Indexing) 則是將這些 ANN 演算法應用於資料,建立起高效搜尋結構的過程。讓我們來看看幾種主流的索引方法:
HNSW (Hierarchical Navigable Small World)
HNSW 使用多層圖結構來組織向量。可以把它想像成一個多層級的高速公路網:頂層的「公路」連接稀疏但距離很遠的節點,讓你可以快速穿越整個向量空間;底層的「市區道路」則密集地連接鄰近的節點,用於精準定位。
搜尋時,從頂層的「入口點 (entry point)」開始,沿著最高速的公路快速跳轉到目標大致區域,然後逐層向下,最終在最精細的底層網路中找到與查詢向量最接近的鄰居。這種分層導航的機制,讓 HNSW 在速度和準確性上取得了絕佳的平衡,是目前最受歡迎的演算法之一。
LSH (Locality-Sensitive Hashing)
LSH 是一種基於雜湊 (Hashing) 的技術。它的核心理念是,設計一組特殊的雜湊函式,讓原本在向量空間中相近的點,有更高的機率被對應到同一個「雜湊桶 (hash bucket)」中。
當查詢時,我們只需要計算查詢向量的雜湊值,然後只在對應的桶裡進行比較,而不用搜索整個資料集,從而大幅縮小了搜尋範圍。
IVF (Inverted File Indexes)
IVF 的原理類似於教科書的目錄。它首先透過聚類演算法(如 K-Means)將所有向量分成多個「簇 (cluster)」或「單元 (cell)」。查詢時,系統會先判斷查詢向量屬於哪個簇,然後只在該簇(以及可能相鄰的幾個簇)內部進行搜尋。
這種方法避免了對整個資料集的無差別掃描,顯著提高了查詢效率,尤其是在資料量巨大的情況下。
PQ (Product Quantization)
PQ 演算法的核心目標是壓縮,以節省記憶體並加快計算速度。它會將一個高維度的長向量,切分成多個低維度的短向量區段,然後對每個區段進行量化,將其轉換為一個更短的程式碼表示。
經過 PQ 壓縮後,整個資料庫佔用的記憶體會大幅減少。在進行距離計算時,也是基於這些壓縮後的短程式碼,速度遠快於對原始向量的計算。PQ 常常與 IVF 等其他索引方法結合使用,以在記憶體、速度和準確性之間取得最佳平衡。
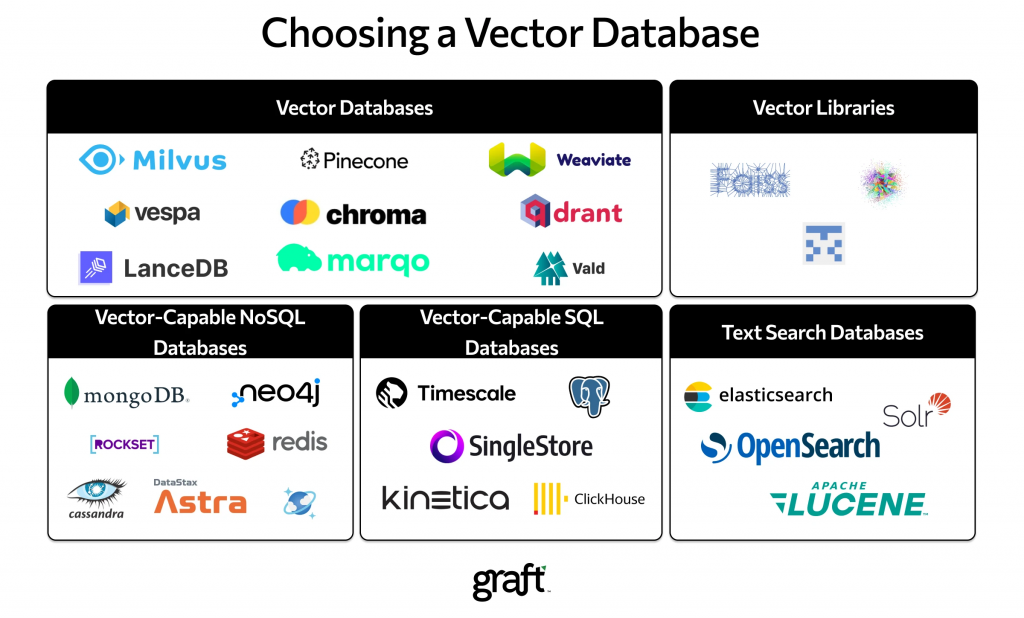
https://www.graft.com/blog/top-vector-databases-for-ai-projects
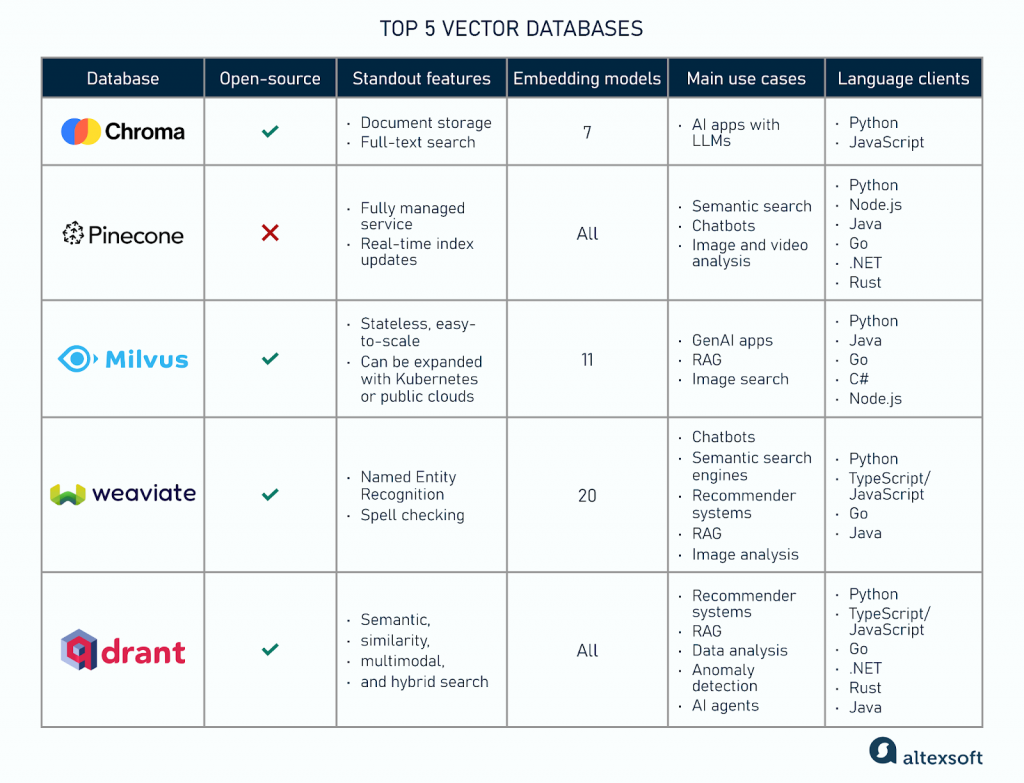
向量資料庫市場正在蓬勃發展,從開源專案到全託管的雲端服務,選擇眾多。一些主流的向量資料庫包括 Milvus、Pinecone、Qdrant、Weaviate、Chroma 等。
https://www.altexsoft.com/blog/vector-database/
了解了如何進行評估之後,讓我們來認識幾位市場上最受矚目、各具特色的供應商:
Milvus 是一個畢業於 CNCF (雲原生運算基金會) 的開源專案,專為大規模、生產級的 AI 應用而設計。它的架構採用了儲存與運算分離的雲原生設計,使其具備極高的擴展性,能夠處理十億級別的向量資料。 Milvus 提供了豐富的索引類型 (如 HNSW, IVF) 和靈活的 API,非常適合需要對底層架構進行深度客製化的大型企業。其商業版本由 Zilliz 公司提供支援。
Pinecone 是最早提供全託管向量資料庫服務 (SaaS) 的公司之一,其核心價值在於「簡單易用」。開發者無需關心底層的伺服器、擴展或維運,只需透過簡單的 API 即可快速搭建高效能的向量搜尋應用。 Pinecone 專注於提供極低的查詢延遲和高可用性,是那些希望快速將產品推向市場、不想被基礎設施束縛的團隊的理想選擇。
Qdrant 是一個使用 Rust 語言編寫的開源向量資料庫,這賦予了它記憶體安全和極高執行效率的先天優勢。Qdrant 的一大亮點是其強大且靈活的元資料過濾能力。它允許使用者在進行向量相似性搜索的同時,附加複雜的過濾條件,且能保證高效能,這在真實世界的複雜應用場景中至關重要。 Qdrant 同時提供開源版本和全託管的雲端服務。
Weaviate 是一個開源的向量資料庫,其獨特之處在於其「模組化」的設計。它內建了與 OpenAI, Cohere, Hugging Face 等模型提供商的整合模組,可以在資料寫入時自動進行向量化 (vectorization),開發者無需自己管理嵌入流程。 Weaviate 另一個顯著特點是支援 GraphQL API,讓開發者能以非常直觀的方式進行語意搜尋和資料關聯查詢。
Chroma (或稱 Chroma DB) 是一個開源的、以開發者為中心的向量資料庫,常被譽為「向量界的 SQLite」。它的設計理念是極簡和易於上手,可以輕鬆地在你的應用程式中直接運行,非常適合本地開發、原型驗證和中小型專案。 Chroma 專注於簡化工作流程,讓開發者能以最少的程式碼快速實現向量搜尋功能,是許多人入門向量資料庫的首選。
向量資料庫市場正在蓬勃發展,從開源專案 Milvus、Qdrant,到雲端服務 Pinecone、Zilliz Cloud,選擇眾多。但如何客觀比較它們的效能,遠比想像中複雜。
過去,許多效能報告都存在一個致命缺陷:過度簡化。單純比較在小型、乾淨資料集(如 SIFT)上的 QPS(每秒查詢數)或平均延遲,往往會產生嚴重誤導。這就像只在專業賽道上測試一輛車的極速,卻忽略了它在城市壅塞路況、惡劣天氣下的真實表現。
業界專家指出,這種簡化測試忽略了三個關鍵的生產環境挑戰:
https://zilliz.com/vdbbench-leaderboard
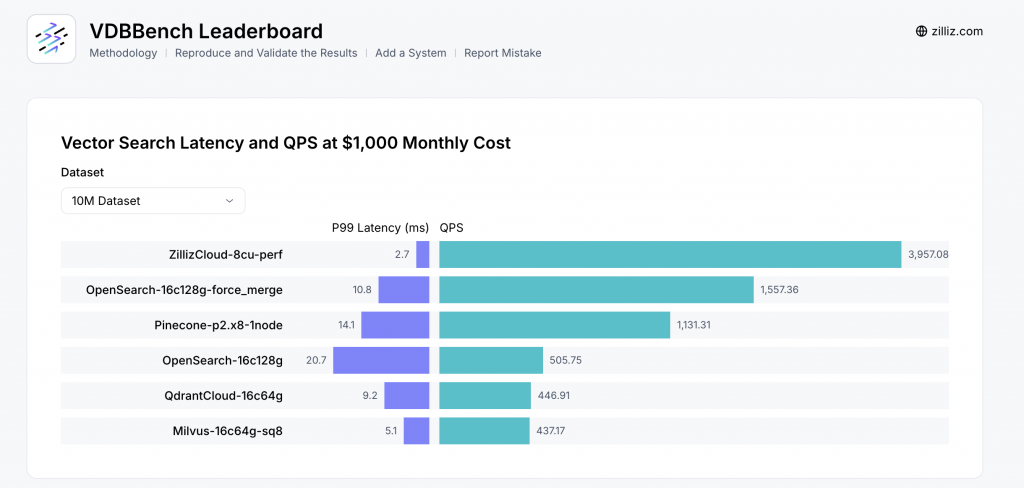
為了解決這個問題,Zilliz 推出了開源的效能測試平台 VDBBench,旨在模擬真實世界的生產環境負載。它不再只看單一的「虛榮指標」,而是從多個層面進行綜合評估,以預測資料庫在實際部署時的行為。
VDBBench 的評估重點包括:
因此,當我們看到 VDBBench 的效能排行榜時,需要理解其背後的嚴謹設定。下圖顯示的是在「每月 1,000 美元成本」和「10M (一千萬) 資料集」的條件下,各個向量資料庫的 P99 延遲與 QPS 表現。
這種帶有明確限制條件的綜合性比較,才對開發者在技術選型時具有真正的參考價值,幫助我們避免「測試環境的王者,生產環境的小貓咪」的窘境。
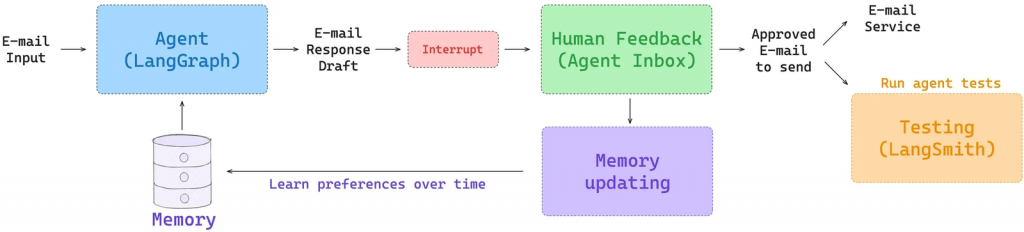
向量資料庫的價值遠不止於 RAG。在更先進的 AI Agent 中,它扮演了「長期記憶」和「即時上下文」的關鍵角色。如下圖 LangChain 的 Agent 範例所示,Agent 在處理任務(如回覆郵件)時,可以將新的互動和人類回饋即時轉化為向量存入記憶體(向量資料庫)。
https://blog.langchain.com/context-engineering-for-agents/
讓我們透過 LangChain 提出的這個架構,來看一個智慧電郵助理是如何「進化」的:
這就是質變的發生點。透過「查詢-行動-回饋-記憶更新」這個不斷循環的閉環,AI Agent 能夠持續學習、適應,並進化。向量資料庫在這裡不再僅僅是一個被動的資料檢索工具,而是成為了 Agent 儲存經驗、塑造個性、實現個人化的主動學習系統。
從最初駁斥「RAG 已死」的論調,到深入探索向量、嵌入、ANN 演算法的內部奧秘,再到評鑑百家爭鳴的資料庫生態,我們已經完整地描繪出向量資料庫作為現代 AI 基石的核心地位。它不僅僅是一種新的儲存技術,更是一種理解和操作非結構化資料的全新思維典範。
我們看到,向量資料庫讓 AI 得以克服傳統資料庫的限制,處理複雜的語意關係;它透過 RAG 為 LLM 提供了對抗幻覺、連接即時與專有知識的橋樑;更令人興奮的是,它正在成為 AI Agent 的「長期記憶」,為打造能夠從經驗中學習、持續進化的個人化 AI 鋪平了道路。
然而,擁有一個強大的記憶引擎,並不等於自動建成一個健全、可靠的智慧體。這條路,我們才剛剛起步。當我們從理論走向實踐,會立刻撞上一堵名為「上下文工程 (Context Engineering)」的高牆。
未來的競爭,將不僅僅是模型大小或資料庫速度的競爭,更是「上下文工程」能力的競爭。誰能更精準地為 LLM 在正確的時間、提供正確的上下文,誰就能打造出更智慧、更可靠、也更值得信賴的 AI。
References:

