
前言
感謝陪伴著我近一個月的鐵人勇者們,再堅持一下我們快到終點了!
我們的旅程始於可觀測性,並以此為基點,深入到了 LLM 與 AI 應用的多個進階議題。這麼設計的初衷很簡單:任何複雜的系統,尤其是像 LLM 這樣的非確定性「黑盒子」,其可靠性都建立在深刻的可觀測性之上。 看不見,就無法優化,更談不上掌控。
本文旨在提出一個三階段的架構演進路線圖,它描繪了一個 LLM 應用如何從一個孤立的概念驗證 (PoC),逐步演化為一個具備持續優化能力的生產級應用,並最終昇華為一個支撐整個企業 AI 創新的、可治理的生態平台。每個階段的演進,都是為了解決前一階段所暴露出的、不可避免的技術債與規模化瓶頸。
我們不會一開始就拋出那張看起來有些複雜的終極架構圖。相反,我們將跟隨一個新創團隊的腳步,從一個最簡單的 PoC 開始,經歷兩個階段的重大進化,最終親手繪製出那張代表著成熟與遠見的企業級 LLM 生態系統架構圖。
LLM 基礎設施與架構的戰略重要性
Grafana Lab 曾經在一場對外的演說中表示:「可觀測性基礎設施應該像水和電一樣,自然而然地從牆壁裡出現。如果有一天它們消失了,只需打個電話,它們就能完好如初地恢復運作。」
在現代平台工程的理念中,一個成熟的基礎設施平台應該像水電一樣,成為一種穩定、可靠且隨取隨用的企業級服務。對於應用開發者而言,對底層大型語言模型的訪問能力包含其安全性、成本控管與模型路由,就應該是這樣一種標準化的服務。
唯有在如此穩固的基礎上,開發團隊才能真正解放生產力,專注於構建具有業務價值的 AI Agent 與應用,而非耗費心力在解決 API 金鑰管理、供應商鎖定、安全漏洞等基礎設施層面的複雜問題。當 LLM 能力能夠像電力一樣從企業的「牆壁」中自然流出時,才能達到最有效率的產出。
對於我們這些負責在企業內規劃並推動 AI 平台化的角色而言,這種將 LLM 能力「服務化」的理念,不僅是值得借鑒的哲學,更是我們設計下一代 AI 基礎設施的核心指導原則。它驅使我們深刻思考,一個成熟且穩健的 LLM 基礎設施,如何在需求不斷演進的背景下,從單一應用支持,逐步成長為支撐整個企業的戰略級平台。接下來,我們將一同探索這條必經的演進之路。
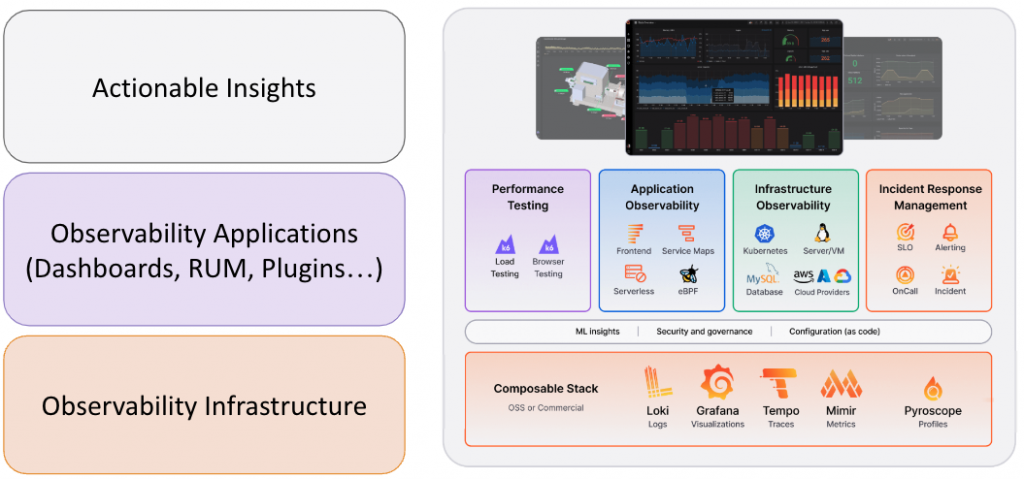
前情提要
在拉開這場架構演進帷幕之前,讓我們先來認識一下將在舞台上登場的各位演員(元件)。這將幫助我們在後續的架構演進中,快速理解每個角色的職責與價值。
接下來,我們將深入探討一個成熟的 LLM 應用架構的演變過程。此過程將以 LLM 為主軸,介紹一套具有高度通用性的架構演變方式。在此過程中,所有步驟都可根據實際情況進行最佳化調整,我們所使用的元件和工具也可以根據需求選擇其他同類服務來替代,並不局限於特定的技術或平台。
-
LLM Provider: 一切魔法的起點。提供基礎語言模型的服務,如 OpenAI, Google, Anthropic 等。
-
Chat UI: 最直接面對使用者的入口,負責提供良好的 AI 互動體驗。(詳見 【Day 13, Day 16, Day 17】)
-
LLM Agent: 整合上下文交互的大腦。負責理解使用者意圖、規劃任務、呼叫工具並生成最終回覆。(詳見 【Day 9, Day 11】)
-
Tools/Functions: Agent 的雙手。讓 Agent 能夠與外部世界互動的工具箱,例如 API 呼叫、資料庫查詢等。(詳見 【Day 10】)
-
Short/Long Term Memory: Agent 的記憶。讓對話能夠持續,並從過去的互動中學習。(詳見 【Day 11, Day 26】)
-
LLM Observability: 專門用於捕獲、追蹤和分析 LLM 應用內部複雜互動(如 Agent 思考鏈)的監控系統。(詳見 【Day 5, Day 6, Day 22, Day 23】)
-
LLM Evaluation: 一套用於評估 LLM 輸出品質、工具使用準確性和整體任務成功率的框架與系統。(詳見 【Day 25】)
-
LLM Gateway: 所有 LLM 流量的中央閘道,負責路由、負載平衡、快取、成本控制與安全過濾。(詳見 【Day 18, Day 19】)
-
Prompt Management: Agent 的劇本庫。用於對 Prompt 進行版本控制、測試、審批和部署的資產管理系統。(詳見 【Day 7, Day 8, Day 24】)
-
LLM Governance: 定義 LLM 使用規則與策略的框架,例如數據隱私、內容安全、合規性要求等,由 Gateway 負責執行。(詳見 【Day 20】)
-
Operators: 負責監督、評估和優化系統表現的人類專家。(詳見 【Day 25】)
我們將從三個階段出發:
-
概念驗證:如何快速啟動一個 Agent 應用。
-
生產級應用:當應用需要服務真實使用者時,如何建立品質與優化的閉環。
-
企業級生態:當應用需要規模化、多團隊協作時,如何構建平台級的治理與基礎設施。
POC 階段:最小可行 LLM Agent
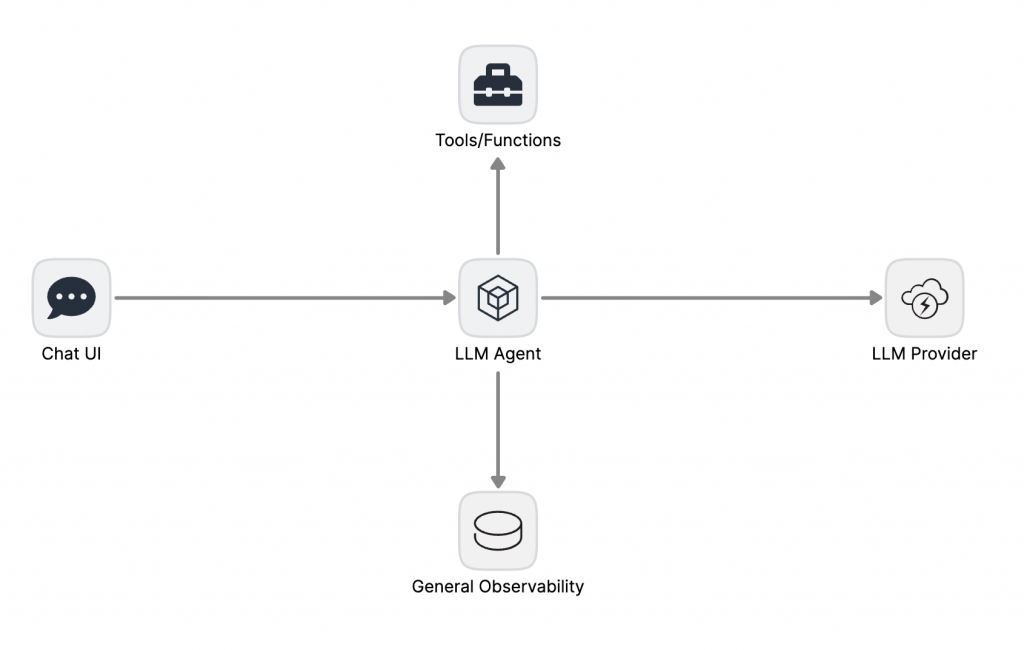
以最低的工程成本,快速驗證核心業務邏輯與 LLM Agent 模式的技術可行性。
此階段的架構是一個典型的單體式應用,重點將會在於 Prompt Engineering 和 Tool/Function 的定義。團隊的大部分時間都花在如何讓 Agent 正確理解指令和使用工具上。
架構中的 Chat UI 直接與後端的 LLM Agent 進行通信。Agent 內部耦合了 Prompt 模板、工具定義和對單一 LLM Provider 的直接 API 調用。可觀測性通常依賴於標準的應用日誌和基礎設施指標,缺乏對 LLM 語義層的洞察。
技術挑戰與瓶頸:
-
LLM 可觀測性缺失: 標準日誌無法有效追蹤 Agent 的非確定性執行路徑。當出現預期外的行為時,除錯過程極其困難,開發者無法區分是 Prompt 的問題、工具的問題還是模型本身的問題。
-
狀態管理缺失: 缺乏專門的記憶體模組,導致應用是無狀態的。這嚴重限制了其在多輪對話、個性化等需要上下文連貫性的場景中的應用潛力。
-
Prompt 即程式碼: 將 Prompt 寫死在應用服務的程式碼中,導致其生命週期與應用服務的生命週期緊密耦合。這使得 Prompt 的迭代、A/B 測試和版本控制變得異常困難,嚴重拖慢了優化速度。
-
供應商強耦合: 對 LLM Provider 的直接依賴不僅造成了供應商鎖定,還使得 API 金鑰管理、成本追蹤和速率限制等基礎治理功能分散在應用層,構成安全和維運風險。
這些痛點,驅使著團隊必須進行第一次重大進化。
生產階段:建立可量化、可觀測性驅動的優化閉環
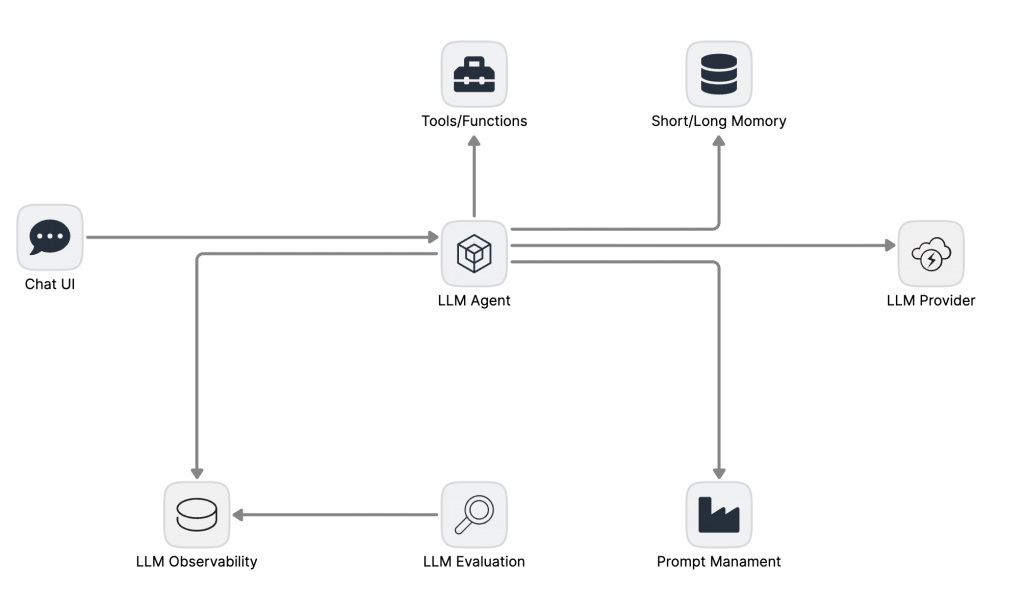
應用需要上線服務真實使用者,穩定性、可靠性和持續改進的能力變得至關重要。
團隊的目標是:讓它變得可維護、可持續優化。
從 PoC 邁向生產,核心的範式轉移是從「功能實現」轉向「品質與穩定性的可持續運營」。架構的目標不再是「它能跑」,而是建立一個系統,使其任何變更的影響都可被量化、任何問題的根源都可被追溯、任何優化都有數據支撐。
此階段的架構圍繞著一個核心的「觀測-評估-優化」閉環進行擴展:
-
引入 Short/Long Term Memory:解決了「失憶」問題,讓 Agent 能夠進行有上下文的、連貫的對話,是進一步實踐 Context Engineering 的必要條件。
-
LLM 專屬可觀測性平面: 這是與通用監控的根本區別。系統必須捕獲語義層面 (Semantic Layer) 的結構化事件。例如,對於 RAG 流程,不僅要記錄延遲,更要記錄檢索的 query、召回的文檔 ID 與分數、以及最終被上下文使用的片段。數據應被展平 (flatten) 並存儲於支援高基數查詢的數據庫 (如 ClickHouse),為精細的下鑽分析提供支持。
-
全面的 OpenTelemetry 集成: OTel 在此階段成為連接各組件的標準化神經網路。通過定義語義化的 Span 屬性 (e.g., prompt.version, rag.document.id, evaluation.result_id),我們將離散的事件串聯成一個完整的、富有上下文的因果鏈,實現從宏觀指標到單一請求軌跡的無縫下鑽。
-
Prompt 管理的流程化: Prompt Management 系統的引入,將 Prompt 的生命週期從開發者的個人靈感,轉變為一個受控的工程流程。一個成熟的流程應包含:設計、單元測試 (基於小樣本)、離線評估 (基於黃金樣本集)、線上金絲雀發布與全量部署。每一次晉級都需要有量化的評估報告作為支撐。
-
量化評估框架: LLM Evaluation 是決策的核心。
-
離線評估保證了變更的基礎品質,它在受控的樣本集上運行,評估指標涵蓋準確性、召回率、引用率等多個維度。
-
線上評估 (如 A/B 測試) 則驗證變更在真實流量下的表現。評估結果必須與可觀測性數據打通,允許從一個低的線上評估分數,直接下鑽到對應的一批失敗樣本軌跡。
-
上下文工程的可觀測性: 對於 RAG 等依賴上下文的應用,必須建立獨立的觀測指標,如檢索命中率和上下文有效性,以確保輸入給 LLM 的「燃料」本身是高品質的。
技術挑戰與瓶頸:
-
規模化難題:當公司內部其他團隊也想開發 LLM 應用時,他們需要重複造輪子嗎?
-
治理真空:如何確保全公司的 LLM 使用都符合安全與合規標準?
-
供應商鎖定:如果想換用另一個更便宜或更強大的 LLM Provider,是否需要重構所有應用?
應用成功了,但成功的應用也帶來了「甜蜜的負擔」,為了解決這些平台級、企業級的問題,最終的進化開始了。
平台化階段:打造成熟企業級 AI 平台
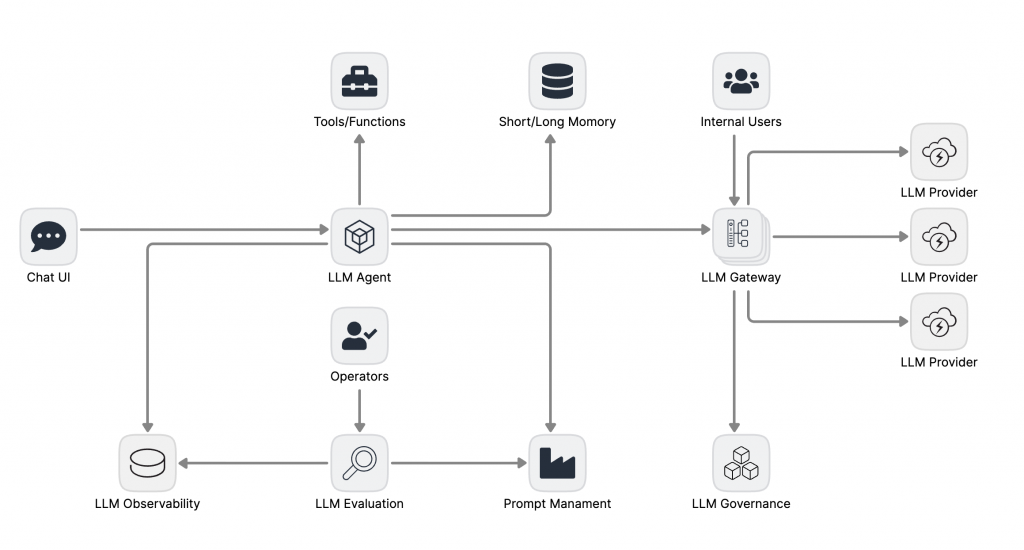
將 LLM 能力抽象為一個標準化、可治理、可複用的企業級平台,賦能全組織的 AI 創新,並實現規模化效益
當組織內有多個團隊、多個應用場景需要使用 LLM 時,架構的關注點必須從單一應用的成敗,上升到整個企業的標準化、複用性、安全性與成本效益。其核心設計哲學是將 LLM 的能力,從一系列分散的「項目」,抽象為一個集中供給、統一管理的「平台服務」。
此階段的演進核心是平台化 (Platformization),其標誌是 LLM Gateway 的引入。
-
中央控制平面 LLM Gateway: Gateway 成為組織所有 LLM 流量的入口,將第二階段的許多應用級關切點(如供應商集成、成本控制)提升為平台級能力。它解耦了應用開發與底層 LLM 基礎設施,其職責包括:
-
動態路由與負載平衡: 根據成本、性能、負載等策略,將請求路由到不同的 LLM Provider。
-
統一認證與鑑權: 為所有 LLM 訪問提供統一的安全入口。
-
成本管理與速率限制: 實現精細化的預算控制和流量整形。
-
通用快取: 對高頻、低變化的請求提供快取,降低成本和延遲。
-
治理框架的建立: LLM Governance 框架在此階段被正式定義。它制定宏觀策略(例如,禁止 PII 數據傳輸、必須進行內容安全審查),而 Gateway 則是這些 LLM Guardrail 策略的強制執行點,確保所有應用自動符合企業的合規與安全標準。
-
人機協同的評估體系: Operators 的角色被正式納入架構。他們可以是專業的領域專家或 LLM 工程師,利用 LLM Evaluation 產出的洞察,進行更高階的決策,例如判斷何時需要引入新的評估指標,或對複雜的失敗案例進行根本原因分析。
-
多租戶服務: Gateway 不僅服務於核心的 LLM Agent,也為其他 Internal Users(如進行數據分析的團隊)提供標準化的 LLM 訪問服務,真正實現了 LLM 基礎設施的平台化與民主化。
-
端到端的 LLOps 自動化: 最終形態是一個成熟穩定的「流水線工廠」。任何對系統的變更,無論是 Prompt、RAG 策略還是路由規則,都必須通過一條標準化的 CI/CD 流水線。這條流水線會自動執行離線評估、部署金絲雀、並基於實時的
成本/品質/延遲 指標進行自動化的檢查 ,最終決定是全量佈署還是自動回滾。
至此,我們構建的不再是一個應用,而是一個具備自我優化能力、能夠安全、高效地支撐整個企業 AI 創新的基礎設施平台。
將概念帶入 LLM 平台核心組件
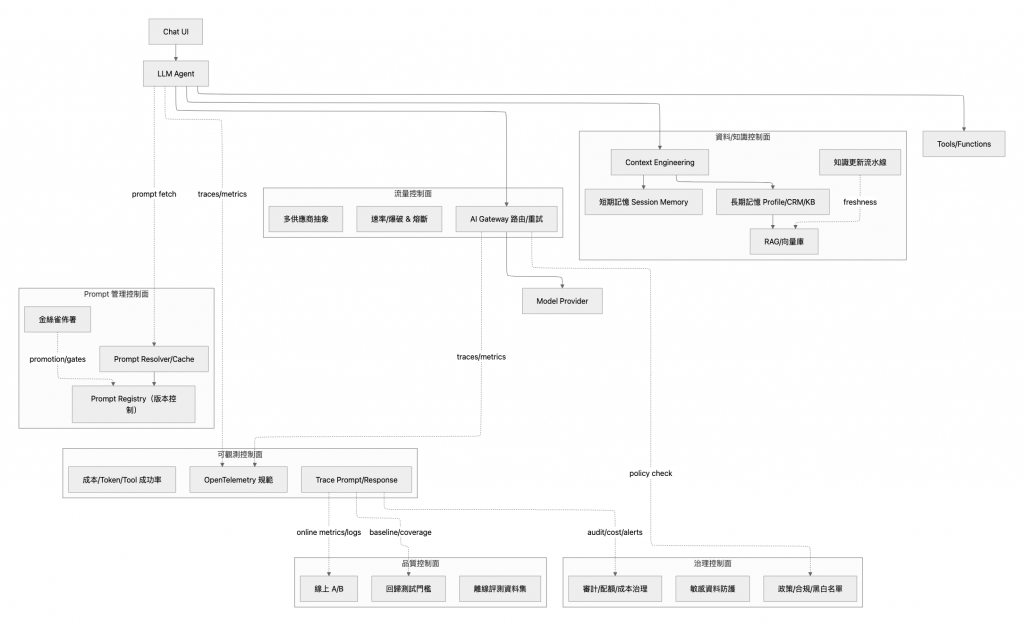
至此,我們已經透過一個三階段的演進過程,一步一腳印地建立了一個宏觀、穩健的企業級 AI 平台架構。我們理解了每個核心組件,不管是從 LLM Agent 到 Gateway,再到 Observability 和 Evaluation的「為何存在 」。
現在,讓我們將這些功能性的概念,順水推舟地映射到一份更貼近工程實現的詳細藍圖中。這張新的架構圖,不再僅僅展示組件,而是將它們組織為一系列職責明確的「控制平面 (Control Planes)」,揭示了系統內部的數據流與協同工作的「如何實現 (The How)」。
這張詳細藍圖,正是我們前面所構建宏觀架構的具體化身:
- 我們所討論的 LLM Gateway,在此化身為 流量控制面。它不再是一個黑箱,而是清晰地展現了其內部職責:執行多路徑的路由、緩存策略、A/B 測試的分流,以及作為所有流量的統一鑑權入口。
-
Short/Long Term Memory 與 RAG 的概念,被組織進 資料/知識控制面。這裡我們能看到更細緻的劃分:Session Memory 負責短期對話記憶,Profile/CRM/KB 構成長期記憶,而 RAG 檢索層 則負責從這些知識源中動態提取上下文。知識更新流水線 的存在,更點明了這是一個持續演進而非靜態的知識庫。
-
Prompt Management 的理念,在這裡演變為一個完整的 Prompt 管理控制面。它包含了一個帶有版本控制的 Prompt Registry 作為資產庫,以及一套 Resolver/Cache 機制來實現高效的 Prompt 提取與分發。
-
LLM Observability 和 LLM Evaluation 這對密不可分的組合,則共同構成了 可觀測控制面 與 品質控制面。前者遵循 OpenTelemetry 規範,負責捕獲與追蹤每一次請求的完整軌跡;後者則利用這些數據,驅動 線上 A/B 測試 的分析、建立 回歸測試門檻,並持續生成 離線評測資料集,形成數據驅動的品質保證閉環。
- 最後,LLM Governance 的宏觀策略,在 治理控制面 得以落地。這裡包含了成本審計、敏感資料的偵測,以及可動態配置的策略合規黑白名單。
從第一張清晰的功能元件圖,到這張控制平面圖,我們並未引入新的概念,而是將先前建立的每一個功能塊,都賦予了更清晰的工程職責與內部結構。
成熟架構下的請求生命週期
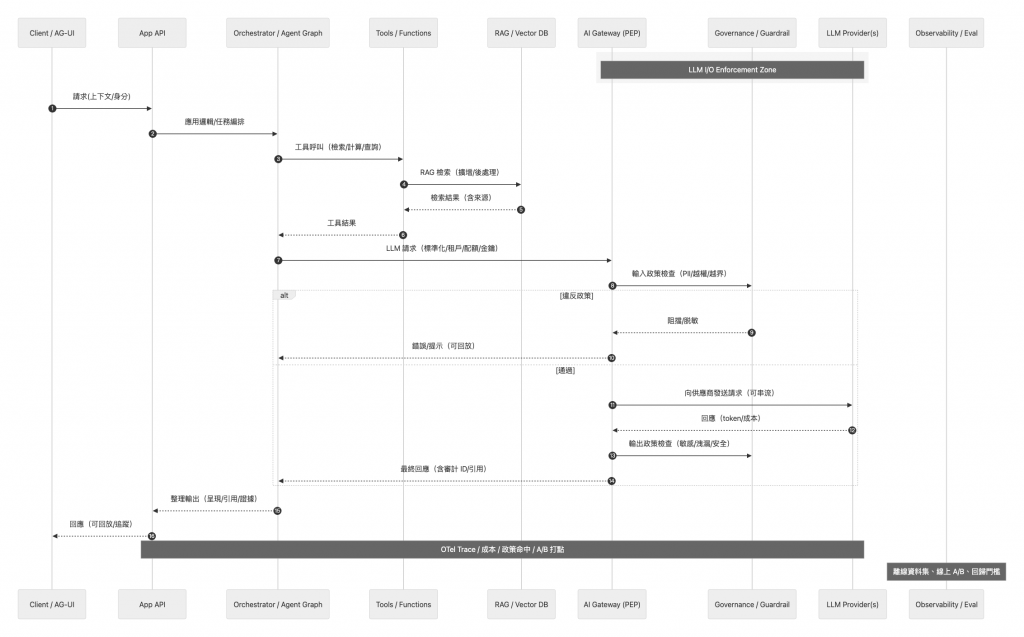
現在在讓我們換個角度的觀察一個企業級 AI 平台中使用者請求的生命週期,那都是被架構師與工程師一手精心設計的旅程。
在上圖中, 使用者的請求始於應用層的編排。當使用者請求透過 Client 抵達 App API 後,會被立即交由核心的 Orchestrator Agent。Orchestrator 作為應用的「大腦」,首先解析使用者意圖,並意識到僅憑原始輸入不足以完成任務。於是,它會並行地向外部 Tools 發起函數調用以獲取即時數據,並向 RAG 知識庫進行深度檢索,以增強與企業私有知識相關的上下文。這個階段的目標,是將一個簡單的使用者問題,豐富成一個包含了執行任務所需全部背景信息、且附帶來源引用的「上下文完備體」。
接著,這個被精心「預處理」過的請求,並不會直接發往語言模型,而是必須通過整個系統的中央控制平面 AI Gateway。這是一道至關重要的安全與治理關卡。Gateway 首先對輸入的 Prompt 執行嚴格的策略審查,與 Governance 模組聯動,掃描並攔截任何潛在的數據洩露、權限越界或惡意注入風險。只有通過這道「入境審查」的請求,才會被 Gateway 根據成本與性能等路由策略, intelligently 分派給最適當的 LLM Provider。
當 LLM Provider 以串流形式返回原始的 Token 輸出後,旅程並未結束。這些輸出流必須再次穿過 AI Gateway,接受同樣嚴格的「出境審查」,確保其中不含任何不應洩露的敏感信息或不當內容。
最終,通過所有關卡、被確認「安全無害」的回應,才會被送回 Orchestrator 進行最後的「修飾」。Orchestrator 會結合先前 RAG 檢索到的來源,為模型的回答附上可供查證的引用,並將其整理為前端所需的標準化格式。至此,一個安全、可信、且富有上下文的回應才算完成,並經由 App API 最終呈現給使用者。
貫穿這整個複雜旅程的,是一條統一的可觀測性軌跡 (OTel Trace)。它會將每一步操作、每一次決策、每一分成本都精確地記錄下來。這條軌跡不僅是問題排查的利器,更是整個平台自我進化的基石,並且源源不斷地為離線評估、A/B 實驗和自動化回歸測試提供著最寶貴的「素材」。
結論
到此為止,我們已經深入參與了一個企業級的 LLM 平台的誕生。至於平台工程的細節,我們都可以在先前的文章中,找到自己需要補足的內容。成功實現完整的 LLM 解決方案,離不開維護工程師、開發人員和運營團隊之間的緊密合作。所以,我們依然需要持續進行經驗分享,幫助團隊理解這些技術的優勢,並根據實際回饋不斷打磨細節。最終,我們的目標是通過技術的不斷進步,確保我們能夠在 AI 的巨浪中找到自己的一席之地,應對未來更加複雜的挑戰。

