
想像一下,一個大型語言模型(LLM)就像一位博學多聞、記憶力驚人的天才,但他的知識卻永遠停留在了「畢業」的那一天。對於畢業後世界上發生的任何新知、或是特定領域內的獨家資訊,他都一無所知。這就是傳統 LLM 面臨的困境:知識的陳舊性與「一本正經胡說八道」的幻覺問題。
為了解決這個問題,檢索增強生成(Retrieval-Augmented Generation, RAG) 技術應運而生。它就像是給了這位天才一本可以隨時翻閱的、即時更新的百科全書,讓他能夠「開卷考試」,根據最新的資料來回答問題。
然而,如果問題變得複雜,答案線索分散在好幾本書、一篇網路文章和一份內部報告中呢?這時,僅僅會「翻書」就不夠了。我們需要一位懂得如何規劃、如何選擇查閱哪些資料、甚至在找不到答案時會換個方法再試一次的智慧研究助理。這,就是 Agentic RAG 登場的時刻。
本文將帶你從 RAG 的基礎概念出發,深入探討傳統 RAG 的瓶頸,並揭示 Agentic RAG 如何透過賦予 AI 「思考」與「行動」的能力,將其從一個被動的問答機器,升級為能夠主動解決複雜問題的智慧代理人,徹底釋放企業內部知識的巨大價值。
https://weaviate.io/blog/what-is-agentic-rag
GPT-3 這樣強大的生成式模型出現之前,自然語言處理領域的主力是像 BERT、RoBERTa 這樣的編碼器模型(Encoder-based Models)。這些模型非常擅長「理解」文本,但不擅長「生成」新的文本。因此,當時的問答系統主流是「抽取式問答(Extractive Question Answering)」。
讓我們用這個視角,重新審視 RAG 的三步驟:
這一步的核心目標始終不變:從龐大的資料庫中,找出與使用者問題最相關的幾段文字。 但在技術選擇上,除了向量檢索,還有更傳統且依然非常有效的方法:
在那個時代,一個典型的檢索系統通常會結合關鍵字檢索和初步的向量檢索(當時的詞向量模型如 Word2Vec、GloVe),先用 BM25 快速篩選出數百篇可能相關的文件,再用向量模型做更精細的排序,最終選出最相關的幾個段落。
目標: 無論用什麼方法,這一步的產出都是一樣的:幾個最有可能包含答案的「候選段落(Candidate Passages)」。
這一步在概念上完全相同:將檢索到的資訊和原始問題結合在一起。但它的目的有細微的差別。
它不是為了打造一個讓 LLM 能「自由發揮」的提示詞,而是為了構建一個標準的「閱讀理解任務(Reading Comprehension Task)」的輸入。
這個輸入格式通常是這樣的:
{
"question": "愛因斯坦在哪一年提出了相對論?",
"context": "[...這裡貼上從維基百科檢索到的段落,其中包含句子:'阿爾伯特·愛因斯坦在1905年發表了關於狹義相對論的開創性論文...']"
}
這個「增強」後的組合,是專門餵給下一步的「閱讀理解模型」的標準格式。
這是最關鍵的區別。在前 LLM 時代,沒有一個模型能像現在的 LLM 一樣,流暢地「生成」一個完整的句子來回答問題。
取而代之的,是像 BERT 這樣的閱讀理解模型。BERT 的工作方式不是生成,而是「標記」。
當 BERT 接收到上一步的「問題」和「上下文」後,它會做兩件事:
以上述例子來說,BERT 會在「上下文」中進行分析,最終的輸出結果極有可能是:
系統根據這兩個位置,從原文中「抽取(Extract)」出 1905 這個詞作為最終答案。它不會生成「愛因斯坦是在1905年提出相對論的」這樣一句完整的話。
在我們了解 Agentic RAG 之前,我們必須深入的了解 LLM 作為一個超級大腦的先天缺陷,其次是傳統 RAG 作為外部知識庫的後天瓶頸。
LLM 就像是一個博學但只能「閉卷考試」的學生,它的知識完全來自於訓練時所學習的龐大資料庫。如果我們只依賴一個獨立的、未經 RAG 增強的 LLM,我們會立即面臨三大根本性難題:
傳統 RAG 的出現,正是為了解決上述三大缺陷。它提供了即時性、事實依據和領域專業性。然而,當我們滿心歡喜地為 LLM 接上這個外部知識管道後,卻發現這個管道本身存在著新的、更棘手的問題。
傳統 RAG 雖然能帶著各種參考書籍的進行「開卷考」,但這個考試的規則卻過於死板。它在解決舊問題的同時,暴露了自身作為一個「單純工具」的三大瓶頸。
傳統 RAG 的流程是線性的、一次性的。它就像一個只會聽從單一指令的初級實習生。你叫他去資料庫找資料,他執行一次搜尋,把找到的結果給你,任務就結束了。他缺乏批判性思維:
這種缺乏驗證與迭代的機制,導致整個系統的成敗完全押寶在第一次檢索的運氣上。一旦首次檢索的資訊有偏差,後續的結果也將是「在錯誤的基礎上,做出精美的回答」。
真實世界的問題往往需要多個步驟的推理和資訊整合,也就是所謂的「多跳問題」。傳統 RAG 在這類問題面前幾乎束手無策。
例如,一個使用者可能會問:「對於我上個月用『SUMMER2024』折扣碼買的那台筆電,退貨政策是什麼?」
要完美回答這個問題,一個智慧系統需要執行一個查詢鏈:
傳統 RAG 缺乏一個「規劃大腦」。它無法將這個複雜問題拆解成上述三個子任務並依次執行。它很可能只完成了步驟一,找到一般退貨政策,從而給出一個不完整甚至完全錯誤的答案。
企業的知識資產天然就是分散的:技術文件是存放在文件庫的 PDF,市場分析報告在公司網站上,而銷售和客戶數據則存於結構化的 SQL 資料庫中。
傳統 RAG 的管道通常被設計為針對單一的知識來源。它就像一個只會使用圖書館某一種索引卡的管理員。你讓他找書,他只會去查作者卡,但如果答案需要結合書名卡和主題卡才能找到,他就無能為力了。它無法根據問題的性質,智慧地判斷此刻應該查詢文件庫、瀏覽網站,還是對資料庫下 SQL 指令。
| 維度 | LLM | 傳統 RAG |
|---|---|---|
| 核心定位 | 一個「閉卷考試」的博學天才 | 一個「單純開卷考試」的應試者 |
| 知識來源與時效性 | 靜態的、凍結於訓練資料截止日期 | 可連接外部知識庫,具備即時性 |
| 事實依據與可靠性 | 容易產生「幻覺」,捏造事實 | 高度依賴檢索品質,答案有據可循 |
| 領域專業知識 | 缺乏對企業內部私有知識的了解 | 核心優勢,專為查詢內部知識而生 |
| 問題解決模式 | 單一步驟的生成,缺乏規劃能力 | 僵化的線性流程 (檢索→增強→生成) |
| 處理複雜問題 | 無法處理需外部知識的多步驟問題 | 無法處理需從多個來源/多次檢索的「多跳問題」 |
| 資料來源彈性 | 無法主動連接外部資料源 | 通常被設計為針對單一知識來源,缺乏彈性 |
| 核心缺陷 | 與現實和私有數據脫節 | 流程僵化,缺乏推理與策略規劃能力 |
看到這裡,我們可以發現一個強大但與世隔絕的 LLM 大腦,以及一個能連接外部世界但運作方式僵硬且單一的 RAG,比較下就像是天平上的兩個極端點。
如果我們能給這個 RAG 管道本身也裝上一個「大腦」,讓它不只會被動地檢索,更能主動地思考、規劃和行動呢?這正是下一代技術 Agentic RAG 想要詮釋的完美解答。
為了解決上述瓶頸,Agentic RAG 應運而生。它的核心思想,是在傳統 RAG 流程中引入一個「智慧代理人(Agent)」。這個 Agent 不再是被動執行指令的工具,而是一個具備規劃、決策、與反思能力的大腦,將整個 RAG 流程從一個固定的管道,轉變為一個動態的、可循環的解決問題框架。

這個智慧代理人,就像從初級實習生進化為了資深研究助理,他擁有了幾項關鍵的能力:
就讓我們繼續深入 Agentic RAG 這個超級大腦是如何運作。
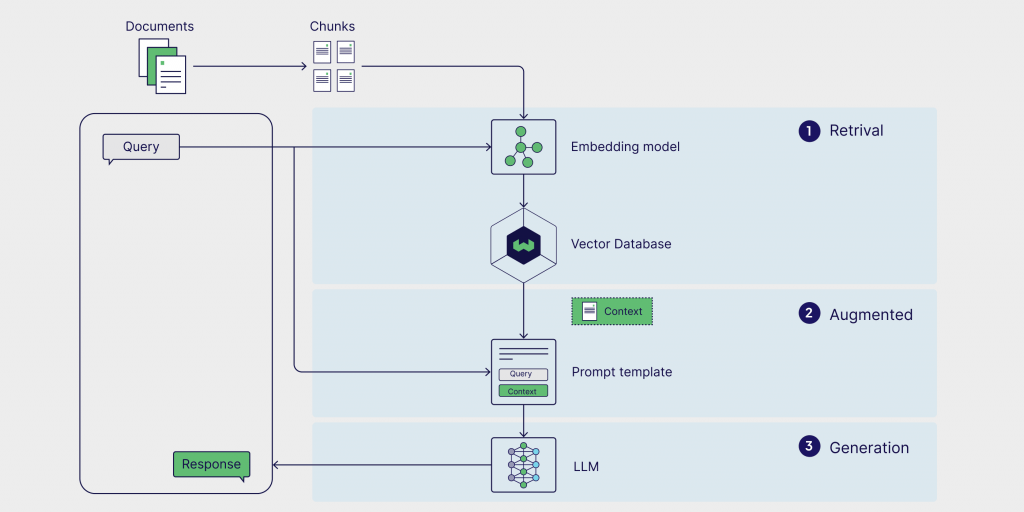
Agentic RAG 的運作流程並非一條直線,而是一個由智慧代理人(Agent)主導的、可循環的動態過程。它將傳統 RAG 的被動檢索,升級為主動的「研究與分析」。讓我們一步步拆解這個智慧大腦的思考與行動過程。
將人類模糊、充滿變化的自然語言,轉化為機器能夠精準理解和比較的數學物件。
當使用者提出問題,例如「我該如何設定我們公司的 VPN?」,系統的第一步不是去進行關鍵字匹配。因為使用者也可能問「公司 VPN 的配置方法是什麼?」或「連上內部網路的步驟」,這些問題字面上完全不同,但意圖是相同的。
為了捕捉這個「意圖」,系統會使用一個嵌入模型(Embedding Model)。
什麼是 Embedding?
Embedding 是一種將文字(單詞、句子或段落)轉換成一個由數字組成的向量(Vector)的技術。這個向量可以被想像成是該文字在一個巨大的、多維度「語意空間」中的唯一座標。
它長什麼樣子?
一個 Embedding 向量就是一長串浮點數,例如:
[-0.0069, 0.0044, -0.0032, ..., -0.0141]
這個列表的長度(維度)通常是幾百到幾千維。它的神奇之處在於,語意上相近的文字,其向量座標在空間中的距離也更近。例如,「設定 VPN」的向量和「配置 VPN」的向量會是「鄰居」,但它們都會離「餐廳菜單」的向量非常遙遠。
這個過程,就是將「人類的意圖」轉化為「機器可計算的座標」,為下一步的精準檢索奠定了數學基礎。
在數以百萬計的向量中,找到與問題「座標」最接近的幾個知識區塊。
我們的知識庫(如所有公司的技術手冊)已經被預先切塊並轉換成了大量的向量,存放在向量資料庫中。現在,我們手握著問題的查詢向量,需要在這個龐大的向量海洋中找到它的「鄰居」。
直接計算查詢向量與資料庫中每一個向量的距離,在資料量大時會非常耗時。為此,我們需要更聰明的演算法,即近似最近鄰(Approximate Nearest Neighbor, ANN)演算法。
什麼是 ANN?
ANN 的核心思想是犧牲一點點的絕對精確性,來換取巨大的速度提升。它不會地毯式地搜索每一個點,而是透過建立一個類似「高速公路網」的索引結構,來快速定位到最可能包含答案的區域。
常見的演算法:
透過這些演算法,系統可以在瞬間返回最相關的幾個知識區塊,例如三份不同的文件,分別是《新員工 VPN 設定指南.pdf》、《VPN 常見問題排查.docx》和《遠端辦公安全守則.pdf》中的相關段落。這些就是 Agent 的第一批「研究材料」。
將收集到的、經過驗證的精華資訊,與原始問題組合成一個完美的「增強提示詞」。
當我們得到 RAG 查詢到的結果後,通常會使用一個預設的 Prompt Template,並將收集到的資訊填入其中,例如:
你是一位專業且嚴謹的客服專家。請根據以下提供的【上下文資訊】,清晰地回答【使用者問題】。
你的回答必須完全基於提供的上下文,不要使用任何外部知識。如果上下文不足以回答,請直接告知「根據目前資訊,我無法回答您的問題」。
【上下文資訊】:
{context}
【使用者問題】:
{question}
將上一步收集到的精華資訊填入 {context} 變數中:
最終,一個完整、豐富、且包含所有必要線索的提示詞就誕生了。
這是 Agentic RAG 與傳統 RAG 最根本的區別,也是「智慧」的體現。
在整個流程中,Agent 可能會進行多輪的 Reasoning 以及 Action,也就是 Agent 將會透過自身的判斷去調度工具,並且依照得到的結果來評估是否需要額外資訊。
Agent 的內心活動可能是這樣的:
這個循環會一直持續,直到 Agent 認為它已經掌握了回答問題所需的所有高品質資訊為止。
由 LLM 作為最終的總結者,將 Agent 準備好的所有材料,轉化為流暢、清晰、人性化的最終答案。
此刻,這個精心打造的提示詞被送到 LLM。重要的是,LLM 的角色已經從「研究員+作者」變成了純粹的「作者」**。**它被明確指示必須立足於 Agent 提供的上下文來生成答案。
由於 Agent 已經完成了所有複雜的資訊檢索、驗證和推理工作,LLM 可以心無旁騖地專注於它最擅長的事情:語言組織和生成。
它會根據提示詞中的上下文,生成如下的最終回應:
「關於您使用『SUMMER2024』折扣碼購買的筆電的退貨政策,根據我們的條款,雖然我們的一般政策允許在 30 天內退貨,但使用該特定折扣碼購買的商品屬於最終銷售,因此不適用於標準的退貨政策。」
這個答案不僅準確、有事實依據,還清晰地解釋了看似矛盾的資訊,完美地解決了使用者的複雜問題。這就是 Agentic RAG 完整運作流程的強大之處。
通用知識(例如「法國首都是哪裡?」)LLM 早已瞭若指掌。然而,企業真正的價值在於那些模型從未學習過的、存於防火牆之內的獨特知識寶藏。這正是 Agentic RAG 大放異彩的核心舞台。
簡單來說,RAG 系統之所以成為企業知識管理的必然選擇,主要基於三大核心原因:
Agentic RAG 將上述優勢提升到了一個新高度,它不再只是被動的「問答機器」,而是主動的「問題解決夥伴」。
企業級知識助理:
員工可以下達複雜指令,如:「幫我總結上季度『飛鷹計畫』的進度,並找出其中關於預算超支的風險分析。」Agent 會自動拆解任務,先後查詢專案管理系統和文件庫,最終將兩部分資訊整合後提供給員工。
次世代客服中心:
客戶問:「我去年黑五買的 XR-500 吸塵器發出怪聲,還在保固期嗎?」Agent 能同時調用產品手冊(非結構化 PDF)來判斷故障原因,並查詢客戶資料庫(結構化數據)確認保固狀態,提供一站式的解決方案。
自動化研究與分析師:
財務總監可以指令:「對比我們和競爭對手 A 公司最新的財報,找出毛利率的主要差異。」Agent 會啟動網路搜尋找到對手財報,調用內部資料庫取得公司數據,甚至執行程式碼進行計算和比較,最終生成一份初步的分析報告。
在這些場景中,Agentic RAG 透過任務分解、工具調用和自我修正的能力,解決了傳統 RAG 無法應對的複雜、多步驟問題,真正開始釋放企業內部沉睡知識的巨大潛力。
在寫這篇文章的過程中,我有一個有趣的發現。起初,我直觀地認為 Agentic RAG 就是「LLM Agent + RAG」的簡單相加。但隨著深入研究,我意識到它們的關係更為精妙。RAG 本身,其實可以被視為 Agent 工具箱中的一件強大工具。
我們傳統上認為的 Agent,是懂得使用工具(Tools)來與外部世界互動的智慧體。而向「向量資料庫進行檢索」這個動作,本質上就是在使用一個名為「RAG」的工具。
因此,一個能夠查詢 API、瀏覽網頁、執行程式碼的 Agent,在其解決問題的某個環節需要內部知識時,它自然而然地就會去「使用 RAG」。從這個角度看,幾乎所有先進的 Agent 應用,在其需要處理私有或即時知識時,都在執行著 Agentic RAG 的核心思想。
這個發現讓我更加清晰地釐清了它們之間細微而關鍵的差別:RAG 提供了「知識的深度」,而 Agent 賦予了「行動的廣度」。Agentic RAG 則是這兩者的完美融合,它創造出了一個既能引經據典、又能靈活應變的智慧體。
References:

