
在過去幾年,大型語言模型 (LLM) 的浪潮席捲全球,「提示工程 (Prompt Engineering)」迅速成為 AI 開發者與愛好者人人都需掌握的顯學。我們致力於鑽研如何撰寫精煉、巧妙的提示詞,期望在一次的互動中,就能引導模型產出最精準、最驚豔的結果。這門技藝無疑是重要的,它教會了我們如何與 AI 進行有效的「對話」。
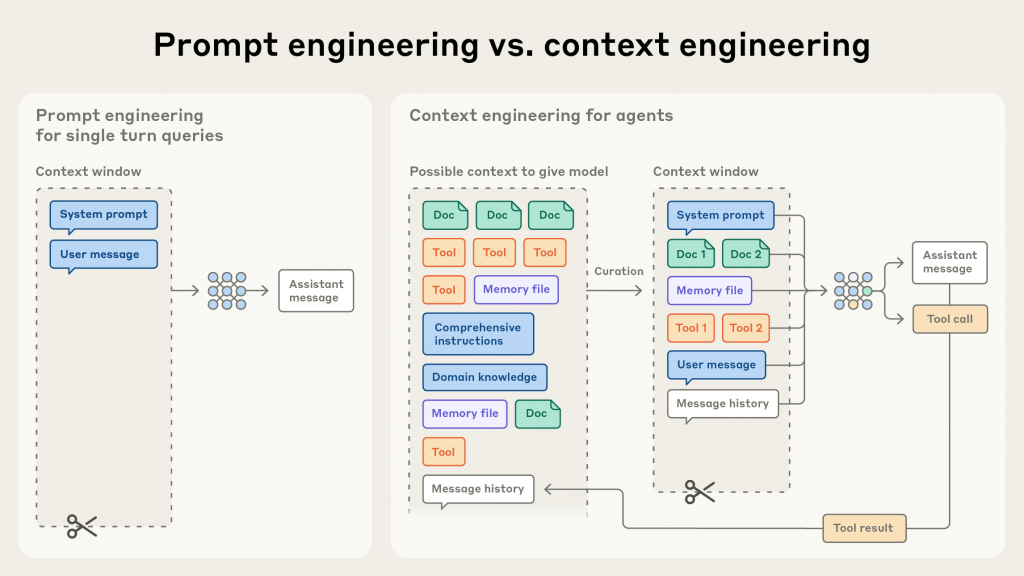
然而,從單純的「問答機器」或「內容產生器」,邁向能夠自主規劃、執行多步驟複雜任務的「AI 代理 (AI Agents)」,一個更深層、更根本的挑戰浮現出來:單次的完美提示已遠遠不足。真正的挑戰不再是如何問出一個好問題,而是如何為 AI 在漫長的任務執行過程中,持續提供一個乾淨、相關且高效的資訊環境。
這就是典範轉移的開端:我們的焦點,正從「Prompt Engineering」轉向「Context Engineering (上下文工程)」。這是一場從「對話」到「資訊流管理」的必然演進。
https://www.projectpro.io/article/context-engineering-in-ai/1152
如果說 Prompt Engineering 是在為一位聰明的演員寫下一句完美的台詞;那麼 Context Engineering 則是作為一名導演,需要管理整個舞台上的一切:包含劇本的主線、演員的記憶、手邊的道具、以及舞台燈光的變化。
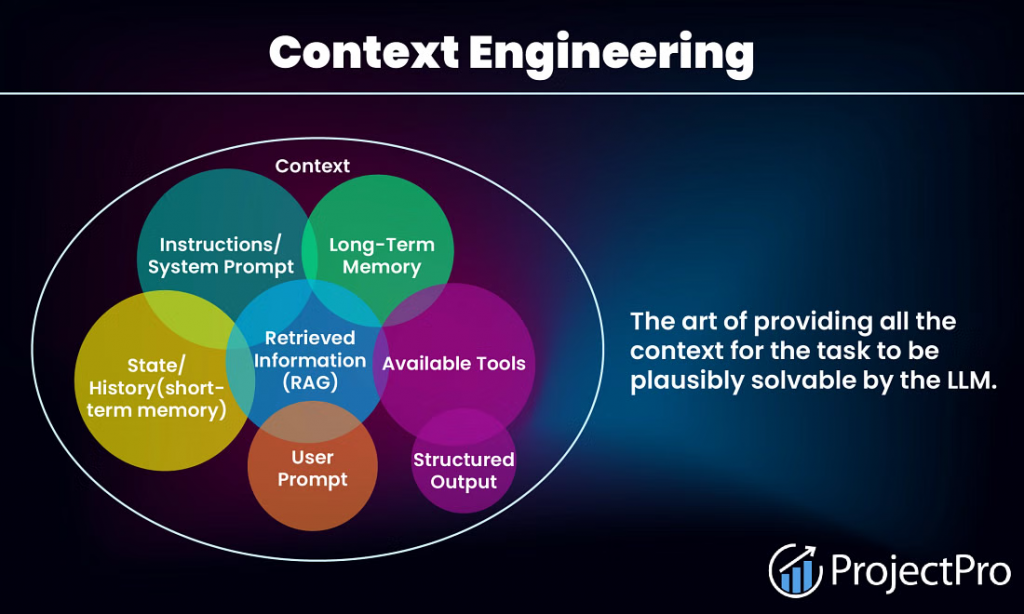
更精確地說,Context Engineering 是一門系統性地策劃、組裝與維護 LLM 在每一次推理時所需完整資訊集合的工程學科。這個「資訊集合」或稱「上下文 (Context)」,其範疇遠遠超越了使用者輸入的那一行指令。它是一個動態的、多層次的資訊體,可能包括:
Context Engineering 的核心目標,並非盲目地將所有資訊塞滿模型的上下文視窗 (Context Window),而是要在每一個決策點,為模型提供「能引導出期望結果的、最小但訊號最強的 token 集合」。
https://www.anthropic.com/engineering/effective-context-engineering-for-ai-agents
我們正處於一個以 AI Agents 為核心的應用爆發時代。無論是能自主修復程式碼的開發助理、能規劃並執行完整行銷活動的策略夥伴,還是能長期管理個人專案的智慧秘書,這些應用的共同點是它們都需要處理長期、多步驟且充滿不確定性的任務。
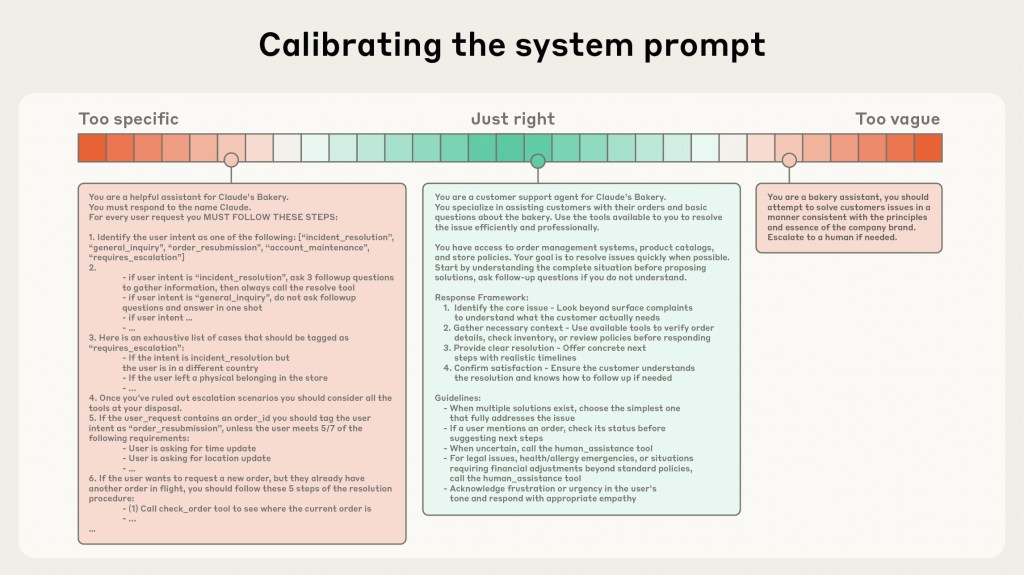
在這樣的場景下,上下文管理變得極為棘手:
因此,Context Engineering 不再是一個可有可無的「優化選項」,而是決定一個複雜 AI Agent 應用程式能否可靠、高效、且經濟地運作的核心基礎設施。
https://www.anthropic.com/engineering/effective-context-engineering-for-ai-agents
在理想的世界裡,我們可以將所有相關資訊像數百頁的技術文件、長達數月的對話紀錄、整個程式碼庫全部提供給 AI,然後期待它能像全知的神一樣,瞬間給出完美的答案。然而,現實是,大型語言模型的運作原理使其與這個夢想之間存在一道鴻溝。強行將所有資訊塞入上下文,不僅效率低下,甚至會適得其反。
如果 Context Window 太小,直接加大不就好了?
首先,我們必須將 Context 視為一種「有限的注意力預算 (Attention Budget)」。儘管我們看到模型廠商不斷推出擁有百萬、甚至千萬級 Token 的上下文視窗,但這帶來了一個巨大的誤解:「更大」並不總是等於「更好」。
Transformer 架構的核心是「注意力機制」,模型在產生下一個字詞時,會回顧整個上下文並為每個部分分配注意力權重。當上下文充滿了大量低相關性的「噪聲」時,真正關鍵的「訊號」就很容易被稀釋。這就像在一個極度嘈雜的房間裡試圖聽清一個人的耳語一樣困難。卓越的 Context Engineering 追求的不是最大的上下文,而是「能引導出期望結果的、最小但訊號最強的 Token 集合」。
https://research.trychroma.com/context-rot
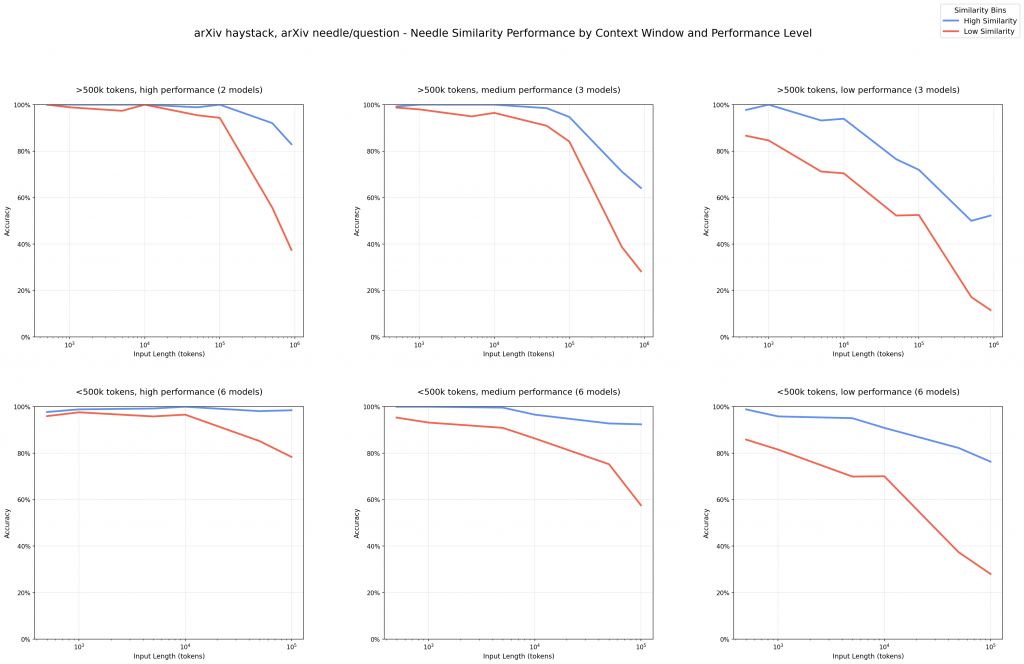
更令人警惕的是一種被稱為「Context Rot (上下文腐爛)」的現象。研究顯示,隨著輸入上下文長度的增加,即使答案明確地存在於文本中,頂尖模型找到並正確使用該答案的能力也會顯著下降。
我們可以將其想像成一個「大海撈針 (Needle-in-a-Haystack)」的測試。當「大海 (Haystack)」即上下文變得越來越龐大時,模型找到那根「針 (Needle)」即關鍵資訊的成功率會急劇下降。資訊不僅僅是被忽略,有時甚至會被模型錯誤地解讀,導致其產生幻覺。這意味著,一個龐大但未經管理的上下文,反而會讓你的 AI 應用變得極不可靠。
管理不善的上下文會在實際應用中引發一連串的具體問題:
https://blog.langchain.com/context-engineering-for-agents/
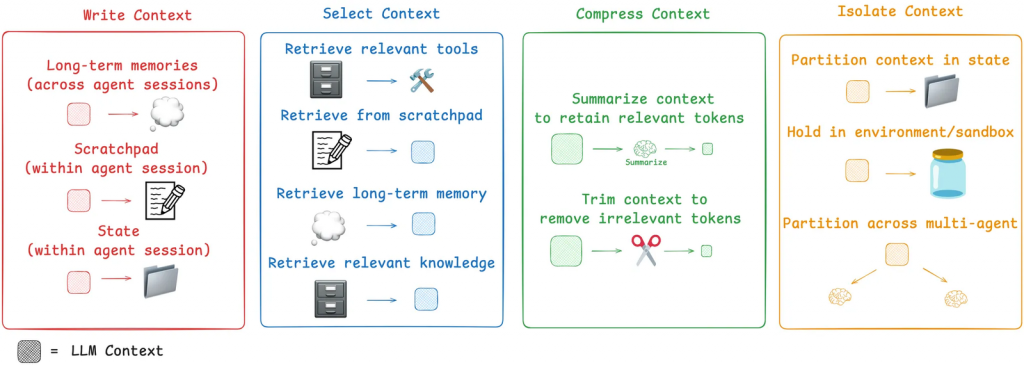
LanChain 團隊以自身對於 Agent 的經驗與了解,提出了以下四種策略來實踐 Context Engineering
理解了「上下文失控」的種種弊病後,我們需要一個系統性的框架來駕馭它。與其將 Context Engineering 視為一門單一的技術,不如將其看作一個工具箱,裡面包含了四種相輔相成的核心策略:寫入 (Write)、選取 (Select)、壓縮 (Compress) 和 隔離 (Isolate)。 一個高效的 AI Agent,正是在任務的每個階段,靈活地運用這些策略來動態建構其「思維空間」。
https://blog.langchain.com/context-engineering-for-agents/
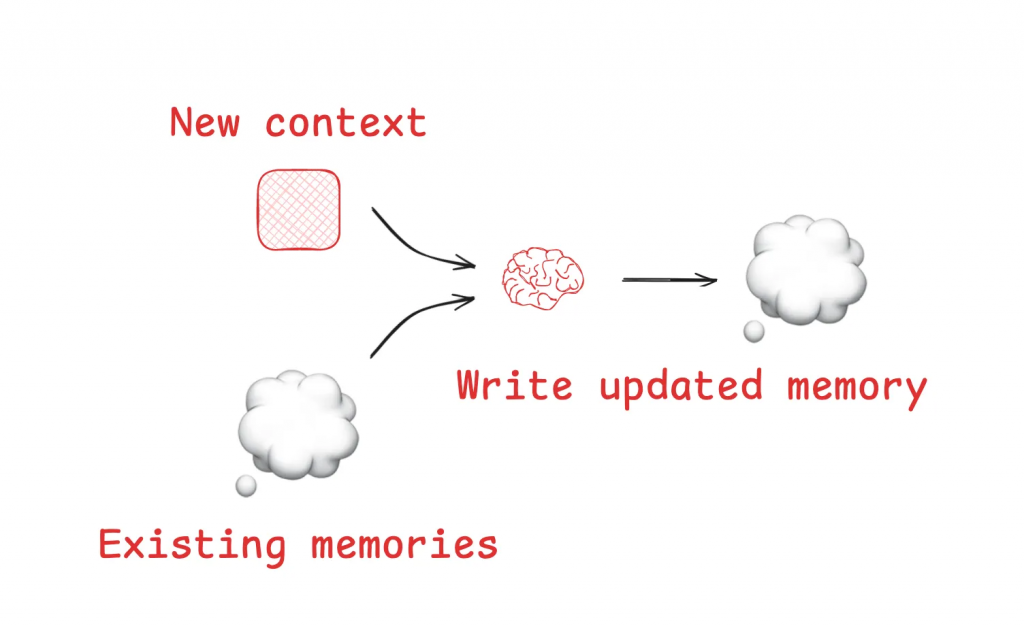
最直接的上下文管理策略,就是將非必要的資訊移出上下文視窗,將其「寫入」到一個外部的、更持久的儲存空間。這就像我們人類會做筆記或建立檔案一樣,目的是為了清空大腦的「工作記憶」,同時確保資訊不會丟失。
Memory Tool 正是此策略的典型實現,它允許 Agent 讀寫外部檔案,建立自己的知識庫。如果說「寫入」是將資訊移出上下文,那麼「選取」則是在最需要的時候,將最關鍵的資訊精準地注入上下文。這是一個「Just-in-Time」的動態過程,確保模型在做決策的當下,擁有最相關的資訊,同時又不會被無關的細節所淹沒。選取的來源可以是多樣的,主要包括以下四種類型:
從短期記憶 (Scratchpad) 中選取:
Agent 在執行多步驟任務時,會將中間的思考或觀察記錄在「草稿本」中。當後續步驟需要參考這些中間結論時,便可以透過工具呼叫或由開發者以程式化方式,將草稿本的特定內容「選取」並放入當前的上下文中。
從長期記憶 (Memories) 中選取:
為了讓 Agent 展現連貫性與個人化,它需要從儲存的長期記憶中選取相關資訊。這包括選取過去的成功案例作為「少樣本範例」、選取儲存的特定指令來指導行為,或是選取事實知識來完成任務。通常會使用嵌入向量 (Embeddings) 或知識圖譜來輔助檢索,但這也充滿挑戰,錯誤的記憶選取可能會導致非預期的結果。
從工具集 (Tools) 中選取:
當 Agent 擁有過多工具時,直接提供所有工具描述會導致模型混淆。更高效的策略是對工具描述本身應用 RAG,根據當前任務,動態地「選取」一小部分最相關的工具,並只將它們的描述放入上下文,這能顯著提高工具選擇的準確性。
從外部知識 (Knowledge) 中選取:
這是「選取」策略最核心的應用場景,而 RAG (Retrieval-Augmented Generation) 正是為此而生的黃金標準。當 Agent 需要基於大量外部文件(如技術手冊、內部 wiki)來完成任務時,RAG 能夠從中高效地檢索出最相關的文件片段,並將其「選取」出來以增強提示詞。
https://blog.langchain.com/context-engineering-for-agents/
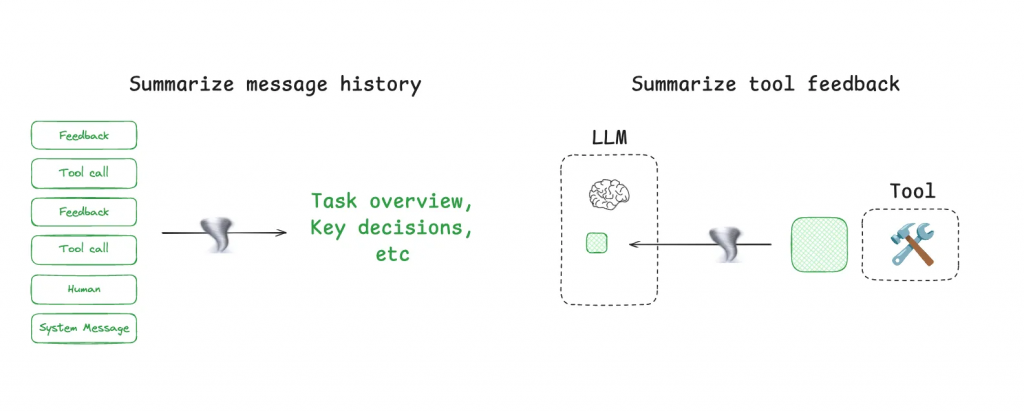
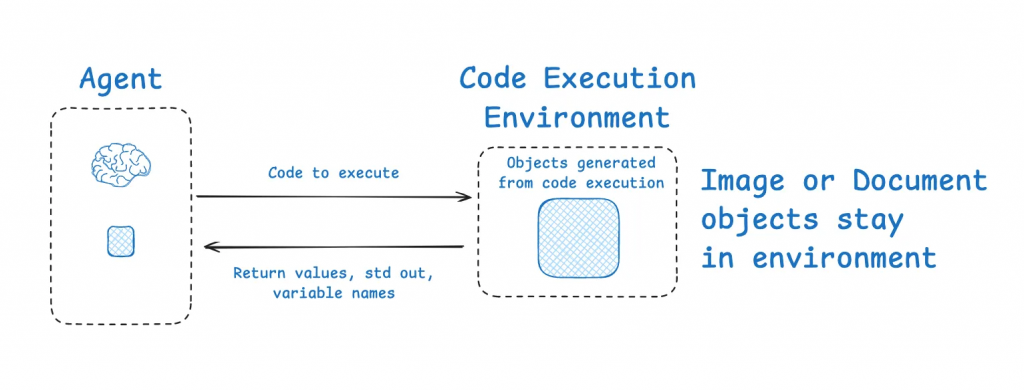
既然上下文視窗的大小有限,我們的目標就是最大化這個容器內資訊的「密度」。「壓縮」策略正是為此而生。
https://blog.langchain.com/context-engineering-for-agents/
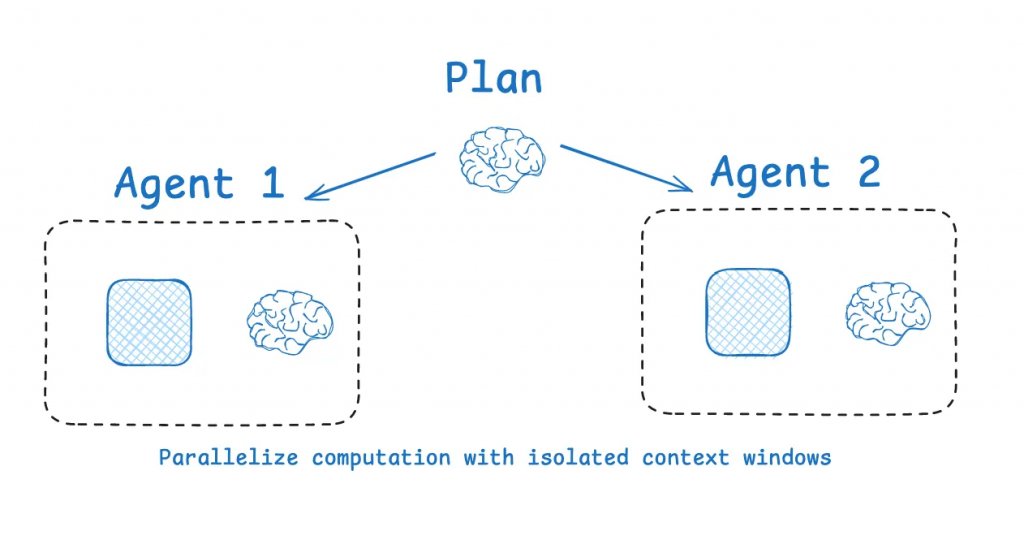
當面對極其複雜的任務時,更智慧的方法是採用「分治法 (Divide and Conquer)」,將問題分解,並在隔離的環境中處理。
https://blog.langchain.com/context-engineering-for-agents/
我們已經探討了 Context Engineering 的核心困境與四大技術策略。現在,讓我們將這些理論轉化為在日常開發中可以遵循的最佳實踐。這些準則將幫助你打造出更穩定、更高效、也更具成本效益的 AI 應用:
在我們探討的四大策略中,一個核心模式反覆出現:RAG (Retrieval-Augmented Generation) 正是實踐高效 Context Engineering 的關鍵引擎。
我們所討論的許多場景,例如從海量文件中提取知識、從眾多工具中挑選合適的選項,本質上都是 RAG 技術最擅長發揮的舞台。大型語言模型 (LLM) 的核心使用場景是處理自然語言,而 RAG 的核心優勢,正是利用自然語言的語意理解能力,從龐大的資料庫中進行精準檢索。這兩者形成了完美的互補。
RAG 的價值不僅在於提升準確性,更在於大幅優化成本與效率。與其將成千上萬個 tokens 組成的龐大文件或對話歷史,直接拋給模型進行昂貴的推理,不如先透過 RAG 進行一次低成本、高效率的檢索。RAG 就像一個智慧的前處理層,它將「大海撈針」的繁重工作從昂貴的 LLM 身上卸下,只將最關鍵的幾根「針」遞交給它。這不僅能幫助我們顯著減少向 LLM 發出的昂貴請求,更能確保模型收到的上下文是乾淨、相關且高信噪比的。
可以說,Context Engineering 提出了「問題」,而 RAG 提供了核心、系統化的「答案」。
我們從 Prompt Engineering 的戰術性技巧出發,逐步意識到,建構下一代 AI 應用的真正戰場,在於對 Context 的戰略性管理。一個管理不善的上下文,會讓最頂尖的模型也陷入混亂、遺忘和幻覺的泥潭;而一個經過精心設計的上下文,則能讓模型發揮出其全部潛力。
我們學習了四大核心策略——寫入、選取、壓縮、隔離——它們共同構成了一個完整的上下文管理工具箱。更重要的是,我們反覆看到,這些策略都以不同的方式指向同一個強大的解決方案。
至此,我們面臨一個清晰的困境:我們擁有海量的潛在有用資訊,但我們無法透過「暴力破解」的方式將其全部塞給模型。這樣做只會引發上下文腐爛、混淆、干擾與高昂的成本。
這個困境,恰恰凸顯了 RAG (Retrieval-Augmented Generation) 技術的核心價值。
RAG 的出現,正是為了解決這個「如何從龐大知識庫中,精準、即時地提供小而美的上下文」的問題。它代表了一種根本性的思維轉變:從試圖建立一個「更大」的上下文,轉向建立一個「更智慧」的上下文供給機制。
與其說 RAG 是一種特定的技術,不如說它是一種哲學:不要把整個圖書館都搬給模型,而是派一位專業的圖書管理員,在模型需要的時候,精準地找到並遞上最相關的那一頁。
References:

