
天下分久必合,合久必分。軟體世界從不缺乏閃亮的新名詞,尤其在微服務與雲原生逐漸成為主流的這些年,可觀測性(Observability) 和 分佈式追蹤(Distributed Tracing) 等概念也隨之崛起。可觀測性三本柱 Metrics、Logs、Traces 更像是一句試圖將複雜理念簡化包裝的口號,背後則是各種開源社群與供應商角力的戰場。
然而,沒能第一時間搭上這股浪潮的人,就此被拋在後頭了嗎?當然不是。市場中總不乏後來居上的劇本。
「可觀測性 2.0」的出現,正是這場競爭演化的結果。它不再侷限於三本柱的框架,而是試圖從先前提到的系統整合、資料關聯、用戶體驗等角度,提出更全面的觀察方式來解決現有的痛點。這場從定義到實踐的重新出發,不只是技術進展,更展現了開源社群中不斷自我挑戰的精神。
接下來,就讓我們來深入了解可觀測性 2.0 背後的故事與核心理念。

在可觀測性的主流語境中,「三大支柱」Metrics、Logs 與 Traces,經常被視為構成系統可觀測性的基礎架構。有時候人們還會加入「Events」,湊成一個聽起來頗為巧妙的縮寫:MELT(Metrics, Events, Logs, Traces)。然而,這些命名終究只是為了便於理解與行銷的分類方式,真正的問題並不是支柱的數量,而是這些支柱在高基數與高維度資料的世界中,是否仍然具有實際效能。
高基數意指資料中存在大量唯一值組合,使壓縮與儲存成本顯著上升,也讓查詢時需付出更高的計算成本。傳統平台多採取刪除、降維或資料分層方式來處理,甚至引入 AI 工具來篩選所謂的「有價值」訊號,但這樣的策略本質上仍然在放棄可觀測性承諾的完整性。若平台在分析前就已丟棄原始資料,任何後續洞察都建立在不完整的基礎上。
這讓我們回到了問題的原點:可觀測性其實一直都是關於系統輸出的處理問題。而最通用的輸出形式,就是廣義的結構化日誌事件(structured logs)。指標與追蹤,其實都可以從這些結構化資料中推導出來。這也是為什麼 OpenTelemetry 日益受到重視:它提供了一種語意一致的資料標準,可以讓事件資料具備足夠的上下文來生成指標、還原追蹤,並支持橫跨系統的查詢與關聯。
為了確保在高維度資料下實現高效能的分析,解決方案應該利用列式存儲(column-based),這是分析型資料庫(OLAP DB)的典型特徵,同時採用靈活的索引格式以支援具有不同維度的欄位。許多OLAP 功能非常適合日誌資料。例如,「寫一次,讀多次」的不可變方法可以確保日誌保持為一個安全且不可更改的真相來源,同時還能提高分析效能。
這樣的轉變,意味著我們不再僅僅將日誌視為維運專用的低階資訊來源。帶有語意與結構化上下文的事件資料,在統一儲存架構中,能為整個組織提供橫跨功能部門的價值:行銷可分析使用者行為、風控能偵測異常交易、安全團隊得以進行威脅追蹤,資料科學與 AI 團隊也能基於長期累積的真實資料訓練模型。
如果仍然執著於以三本柱為中心的資料孤島式設計,企業將持續面對成本上升與可見性斷裂的雙重壓力。而真正的解法,則是一個以語意日誌為核心、支援高基數與高維度的分析型可觀測性平台,它能即時處理大量事件資料,保留原始真實性,同時支援橫向橫切查詢與跨部門共享。這將不只是可觀測性 2.0,更是資料驅動組織架構的底層基礎建設。

這幾年在社群不斷推動下,OpenTelemetry 已逐漸成為可觀測性領域的共同語言。它透過統一的傳輸協議與資料結構定義,並結合社群提供的完整工具鏈,嘗試解決過去遙測資料規劃分散、難以整合的問題。這確實讓業界首次看見「跨平台、跨工具」的可能性,也為後續的分析與標準化奠定了基礎。
OpenTelemetry的資料模型中,幾乎每種遙測訊號都包含了半結構化的鍵值對欄位。這些是設計的關鍵:
以下是 JSON 格式的 OTLP Log 的簡潔範例,展示了分層資料模型:
{
"resourceLogs": [{
"resource": {
"attributes": [{
"key": "event.type",
"value": { "stringValue": "test" }
},{
"key": "service.name",
"value": { "stringValue": "example-service" }
},{
"key": "service.country",
"value": { "stringValue": "test-resource" }
}]
},
"scopeLogs": [{
"scope": {},
"logRecords": [{
"timeUnixNano": "'$(date +%s)000000000'",
"severityText": "INFO",
"body": {
"stringValue": "This is a test log message generated at '"$(date -u "+%Y-%m-%d %H:%M:%S UTC")"'"
},
"attributes": [{
"key": "service.environment",
"value": { "stringValue": "development" }
},{
"key": "service.country",
"value": { "stringValue": "test" }
},{
"key": "kind",
"value": { "stringValue": "test" }
},{
"key": "event.type",
"value": { "stringValue": "test" }
}]
}]
}]
}]
}
這種設計的哲學是:提供一個標準化的骨架,但允許使用者填充任意豐富的、高基數的上下文資訊。 這對於現代雲原生應用至關重要,因為你無法預先知道所有需要查詢的維度。
直接將一個 JSON blob 或 Map 存入資料庫的單一欄位是低效的,因為它違背了行式儲存的初衷。然而,現代的 OLAP 資料庫和數據管線已經發展出專門的技術來高效地處理這種半結構化資料,而 OTel 的設計正好能發揮這些技術的最大優勢。
這是最核心的優勢,OLAP 資料庫(如 ClickHouse, Druid, Honeycomb 等)擅長處理寬表,OTel 的屬性設計與此完美契合。
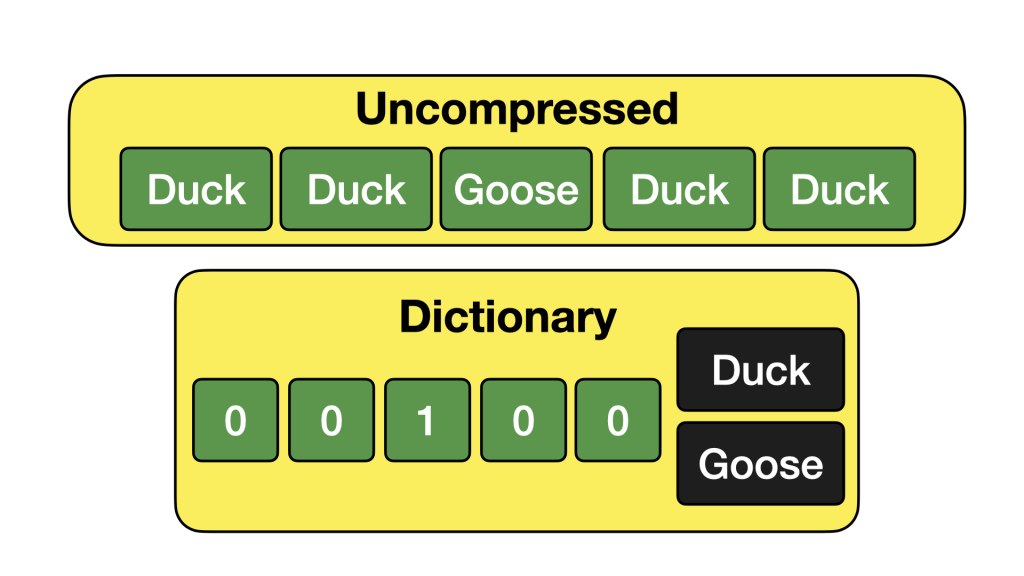
Column-based 資料庫的壓縮能力依賴於單一欄位內資料的重複性和同質性,這裡我們以 DuckDB 的 Dictionary Encoding 設計就能一目了然,。OTel 的屬性設計極大地增強了這一點。
現代系統的故障排查通常需要下鑽到非常具體的維度,例如 user_id, trace_id, request_id。這些都是高基數欄位。

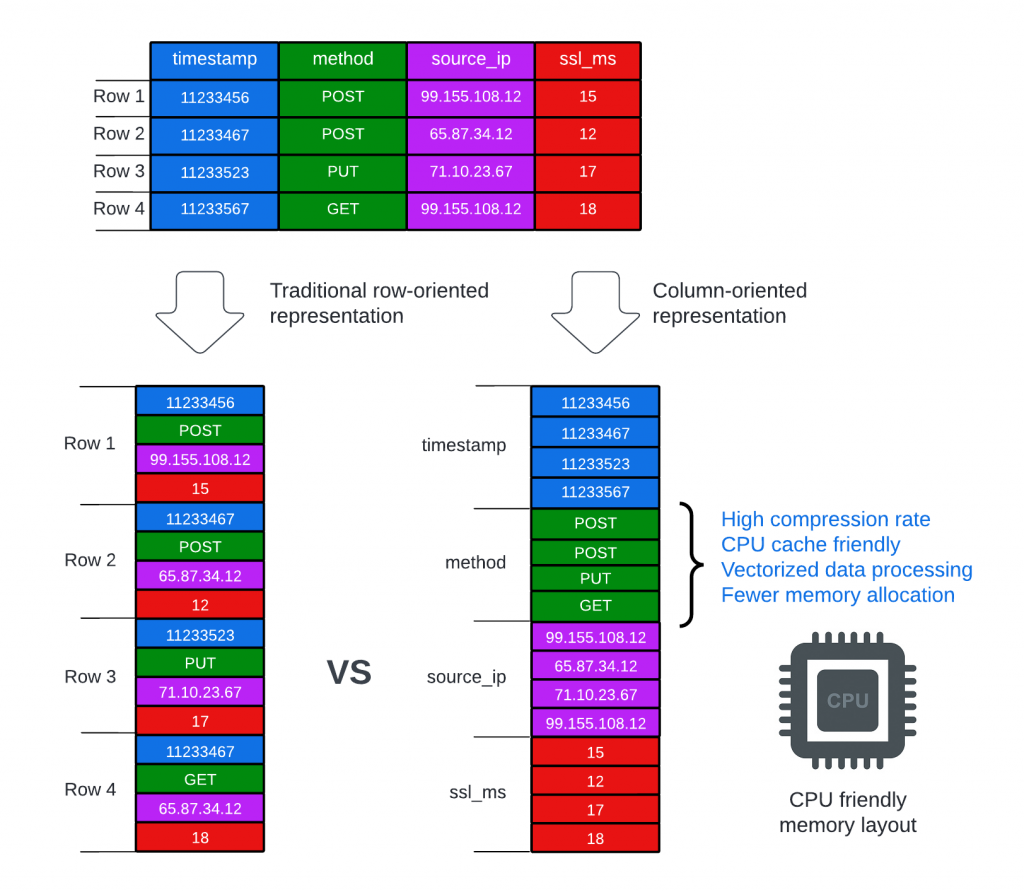
OpenTelemetry 的資料格式設計,特別是向 OTel Arrow Protocol 的演進,深刻地反映了對現代資料分析基礎設施的理解。透過採用行式(columnar)的資料模型,OTel Arrow 不僅解決了傳統列式(row-oriented)格式在傳輸和處理大規模遙測資料時的效能瓶頸,更透過 Apache Arrow 的技術優勢,實現了在 傳輸、壓縮 到 處理 整個管線上的效能躍升。這種設計大幅降低了網路頻寬需求、CPU 解析與記憶體消耗,並且能充分利用現代 CPU 的向量化運算能力,為建構高效能、低成本的現代觀測性平台奠定了堅實的技術基礎。
OTLP 使用 Protobuf 將每筆遙測資料(如一個 span、一筆 log、一個 metric data point)序列化為獨立紀錄。這種 row-oriented 格式雖適合小批量資料,但在大規模遙測場景下會遇到:
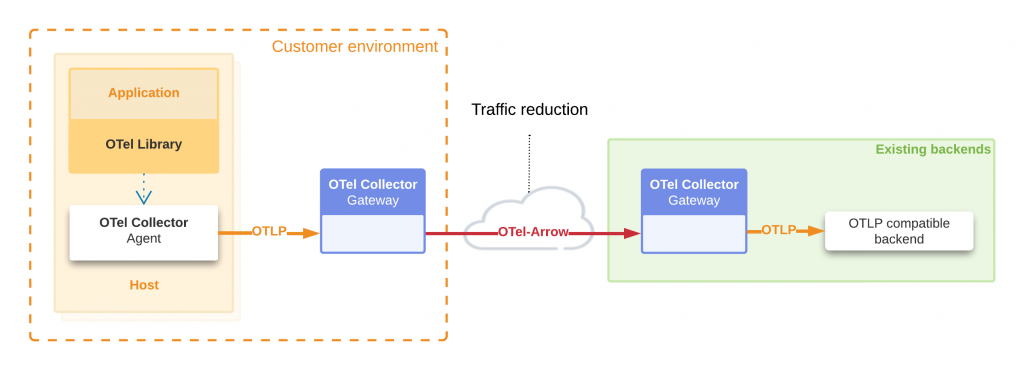
若最終流入 columnar OLAP 資料庫(如 ClickHouse、Druid、BigQuery),還能進一步受益:
- 批量寫入更快:Arrow 本身就是 columnar 批次,可減少 row → column 轉換開銷。
- 壓縮優化延續:Collector 階段的 dictionary/delta 編碼可與 OLAP 壓縮互補。
- 管線一致性:從 Collector → Arrow 批次 → OLAP,保持 columnar 流程,整體效能與穩定性更佳。
講了這麼多,其實核心就一句話:可觀測性不只是三本柱。
在高基數、高維度的世界裡,如果還把 Metrics、Logs、Traces 拆開來看,最後只會被資料成本跟維運壓得喘不過氣。
真正的方向,是把所有東西都回歸到 結構化事件,讓它們在一個統一的平台裡發揮價值。OpenTelemetry 幫我們定義了語言,OLAP 資料庫給了我們高速引擎,而 Arrow 協議則是那個把傳輸、壓縮、處理串起來的快車道。
所以你會發現,當這些元素湊在一起時,觀測性不再只是工程師的專利,而是能被行銷、安全、風控、AI 團隊一起用的資料基礎建設。這就是我眼中的 可觀測性 2.0 ,不只是通靈工具,而是一個讓組織運作更透明有信心的利器。
References:

