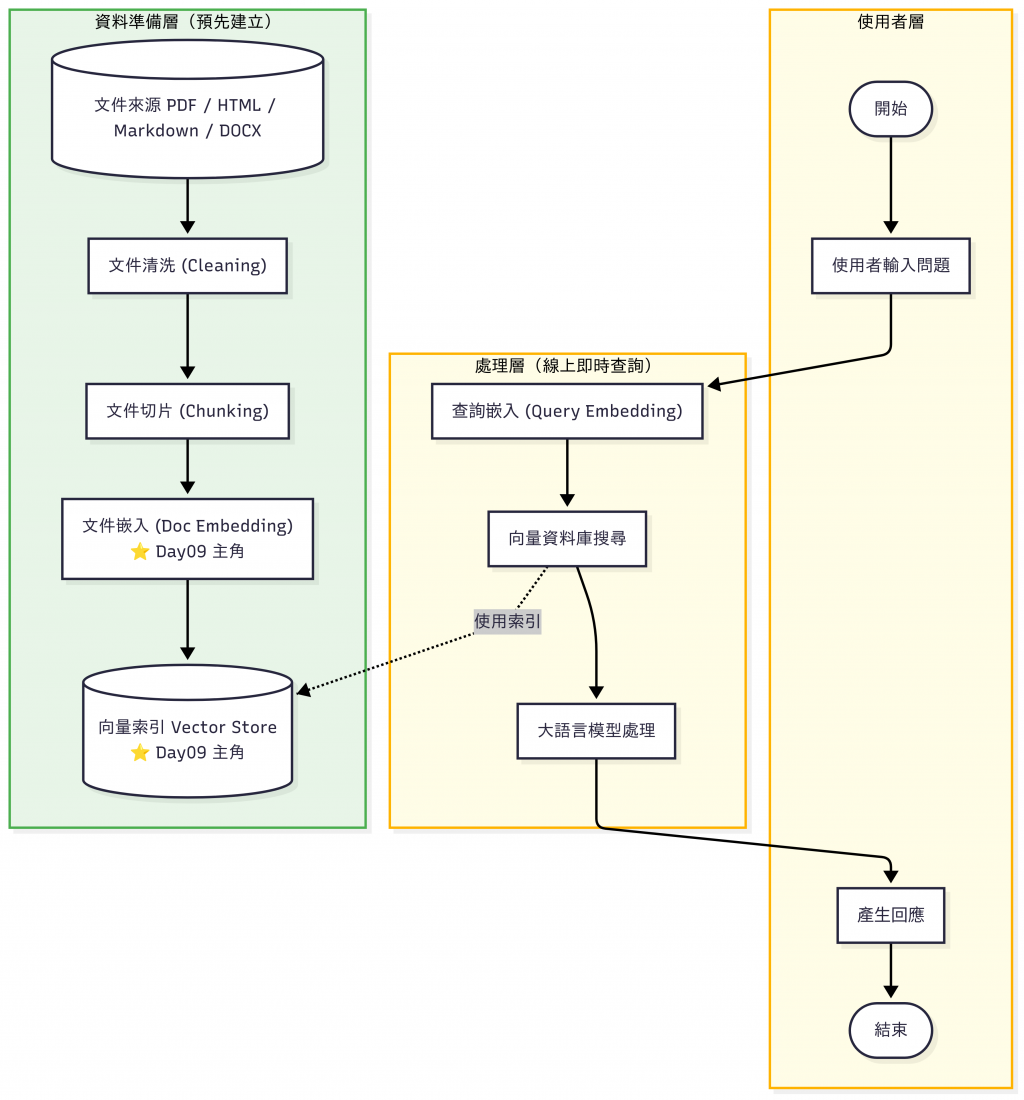
昨天(Day 8)我們完成了兩件重要的事:
到這裡,我們已經把「原始文件」轉換成一堆乾淨、可用的小片段。
但是這些片段依然只是「文字」,電腦並不理解它們的語意。
今天(Day 9)我們要邁向下一步:
把文字轉換成向量(Vectorize),並建立索引(Index),讓檢索能夠快速、語意準確地進行。
在 RAG 系統中,檢索的關鍵在於「查詢」和「知識」之間的語意對齊。
舉個例子:
關鍵字幾乎不同,但在向量空間裡會非常接近,代表能檢索到同一段知識。

選擇 Embedding 模型
text-embedding-3-small / large (簡單好用,支援多國語言)sentence-transformers/all-MiniLM-L6-v2 (開源,可離線部署)用 OpenAI API 把文字向量化
def main():
load_dotenv()
api_key = os.getenv("OPENAI_API_KEY")
if not api_key:
raise ValueError("沒有找到 OPENAI_API_KEY,請在 .env 設定!")
# 使用環境變數建立 Client(建議統一風格:隱式讀取即可)
client = OpenAI()
text = "RAG pipeline 需要清洗與切片"
resp = client.embeddings.create(model="text-embedding-3-small", input=text)
vec = resp.data[0].embedding
print(f"✅ 取得 embedding 成功,維度長度:{len(vec)}")
執行結果:
❯ python 01_embed_quickcheck.py
✅ 取得 embedding 成功,維度長度:1536
在 Day04 - 向量資料庫選型 (Weaviate, Pinecone, FAISS, Milvus) - 以維運成本做決策 我們比較了 Weaviate, Pinecone, FAISS, Milvus 等向量資料庫,今天就直接把向量化後的文字存進去。
💡 如果你只是要跑小型測試,用 FAISS 就夠;但在生產環境,通常會選擇雲端向量 DB 來處理擴展性、備份與監控問題。
當資料量越來越大,檢索速度就會成為瓶頸。
向量索引(Indexing) 能在高維空間建立「捷徑」,讓查詢能在毫秒級完成。在 Day04 - 向量資料庫選型 (Weaviate, Pinecone, FAISS, Milvus) - 以維運成本做決策 我們比較過「資料庫選型」;今天則進一步深入「索引演算法」。兩者加在一起,才能構成完整的檢索方案。
常見技術:
| 方法 | 原理 | 適合場景 | 優點 | 缺點 | 常見搭配 | 實務案例 |
|---|---|---|---|---|---|---|
| Flat | 暴力搜尋,精準但慢 | 小型 demo / baseline | 準確 | 資料量大時慢 | - FAISS IndexFlatL2- 真實標準 / 標準答案的基準線測試 |
高精度需求:醫療研究文件、法律文件比對 |
| HNSW (Hierarchical Navigable Small World Graph) | 基於圖的高效率近似最近鄰檢索 | 百萬級、低延遲需求 | 查詢快速 | 記憶體佔用高,建立時間較長 | - Weaviate、Milvus 預設索引 - Qdrant 預設演算法 | 聊天機器人、即時問答 |
| IVF (Inverted File Index) | 分桶 + 掃桶加速搜尋 | 上億級,折衷速度/精度 | 速度快 | 需訓練、調整參數(精準度取決於分桶策略) | - FAISS IndexIVF - Milvus 支援 IVF+PQ |
大規模文件檢索、雲端服務 |
| PQ (Product Quantization) | 壓縮向量以降低記憶體需求 | 超大資料,節省成本 | 節省記憶體 | 精準度下降 | - 雲端商用方案(如 Pinecone、Qdrant)底層演算法多半用 HNSW+ IVF/PQ 混合- FAISS IndexIVFPQ |
搜尋引擎、電商推薦系統 |
這邊的程式碼有先簡化過,我特別把「我要報銷」拿來跟每個文件片段逐一比較,這樣更能直觀理解所謂「語意相似的距離」是什麼。
然而實務上在檢索的時候並不會這麼做,而是會自動比較 Query 向量 和 所有文件向量 計算距離以及相似度,再依相似度排序(Top-K)。我把貼近實務的程式碼貼在 GitHub Repo 裡的 03_search_compare_l2_cosine.py ,有興趣深入了解的話可以再去研究看看。
# 02_faiss_minimal_flat.py
TOP_K = 5
EMBED_MODEL = "text-embedding-3-small"
DOCS = [
"加班申請需事先提出,加班工時可折換補休",
"出差申請需填寫出差單,並附上行程與預算",
"報銷規則需要提供發票,金額超過 1000 需經理簽核",
"員工請假需提前一天提出,病假需附上診斷證明",
"差旅住宿費上限為每晚 3000 元",
"年度績效考核結果將影響年終獎金比例",
"離職需提前一個月提出申請",
"會議室使用需事先預約,不可長期佔用",
"公司總部位於台北市信義區",
"飲料與零食可由團隊經費報支",
"伺服器維護時間為每週日凌晨 2 點到 4 點",
"資料庫備份需至少保存 90 天",
]
def pretty_print_results(query: str, docs: list[str], indices: np.ndarray, dists: np.ndarray, k: int = TOP_K) -> None:
print("\n" + "═" * 60)
print(f"【查詢】{query}")
print(f"【Top {k} 結果|距離越小越相關】")
print("─" * 60)
for rank, (i, d) in enumerate(zip(indices[:k], dists[:k]), start=1):
print(f"{rank:>2}. 距離={d:.4f} | #{i:02d} | {docs[i]}")
print("═" * 60)
def main() -> None:
# 讓 FAISS 在 macOS/Arm 上更穩定(非必要,但建議保留)
faiss.omp_set_num_threads(1)
# 讀取 API Key
load_dotenv()
api_key = os.getenv("OPENAI_API_KEY")
if not api_key:
raise ValueError("沒有找到 OPENAI_API_KEY,請在 .env 設定!")
client = OpenAI(api_key=api_key)
# 顯示文件清單
print("【文件清單】")
for i, d in enumerate(DOCS):
print(f"{i:02d}: {d}")
# 向量化(示範簡單逐筆;若大量文件,建議改成 batch 版本)
print("\n正在產生文件向量(embedding)...")
embs = []
for d in DOCS:
emb = client.embeddings.create(model=EMBED_MODEL, input=d).data[0].embedding
embs.append(emb)
embs = np.array(embs, dtype="float32")
# 顯示向量維度
dim = embs.shape[1]
print(f"Embedding 維度:{dim}(模型:{EMBED_MODEL})")
print("第一個文件向量前 8 維:", np.round(embs[0][:8], 4))
# 建立 FAISS Flat (L2) 索引
index = faiss.IndexFlatL2(dim)
index.add(embs)
# 讀取查詢字串(可由命令列帶入)
query = sys.argv[1] if len(sys.argv) > 1 else "我要報銷 2000 元"
# 產生查詢向量並檢索
q = client.embeddings.create(model=EMBED_MODEL, input=query).data[0].embedding
q = np.array([q], dtype="float32")
D, I = index.search(q, k=min(TOP_K, len(DOCS)))
dists, idxs = D[0], I[0]
# 顯示結果
pretty_print_results(query, DOCS, idxs, dists, k=min(TOP_K, len(DOCS)))
# 參考:與「Naive 全量比較」對照(驗證正確性)
# (Flat 索引與全量 L2 計算理論上結果應一致)
naive = np.array([norm(q[0] - v) for v in embs], dtype="float32")
naive_order = naive.argsort()[: min(TOP_K, len(DOCS))]
if not np.array_equal(naive_order, idxs[: len(naive_order)]):
print("\n⚠️ 提示:FAISS 與 Naive 排序不同,請檢查向量或索引設定。")
else:
print("\n✅ 驗證:FAISS 與 Naive(L2) 排序一致。")
執行結果:
❯ python 02_faiss_minimal_flat.py
【文件清單】
00: 加班申請需事先提出,加班工時可折換補休
01: 出差申請需填寫出差單,並附上行程與預算
02: 報銷規則需要提供發票,金額超過 1000 需經理簽核
03: 員工請假需提前一天提出,病假需附上診斷證明
04: 差旅住宿費上限為每晚 3000 元
05: 年度績效考核結果將影響年終獎金比例
06: 離職需提前一個月提出申請
07: 會議室使用需事先預約,不可長期佔用
08: 公司總部位於台北市信義區
09: 飲料與零食可由團隊經費報支
10: 伺服器維護時間為每週日凌晨 2 點到 4 點
11: 資料庫備份需至少保存 90 天
正在產生文件向量(embedding)...
Embedding 維度:1536(模型:text-embedding-3-small)
第一個文件向量前 8 維: [-0.0004 0.0519 0.0299 0.0002 -0.029 -0.001 0.004 0.0532]
════════════════════════════════════════════════════════════
【查詢】我要報銷 2000 元
【Top 5 結果|距離越小越相關】
────────────────────────────────────────────────────────────
1. 距離=0.9170 | #02 | 報銷規則需要提供發票,金額超過 1000 需經理簽核
2. 距離=1.2500 | #09 | 飲料與零食可由團隊經費報支
3. 距離=1.2730 | #06 | 離職需提前一個月提出申請
4. 距離=1.3131 | #04 | 差旅住宿費上限為每晚 3000 元
5. 距離=1.3954 | #11 | 資料庫備份需至少保存 90 天
════════════════════════════════════════════════════════════
✅ 驗證:FAISS 與 Naive(L2) 排序一致。
實務上的文件量通常動輒上千上萬條,所以並不會一筆一筆慢慢處理,而是會批次處理(Batch Processing)進行以節省 API 呼叫次數、時間以及 Token 用量:
def batch_embedding(client: OpenAI, texts: list[str], batch_size: int = BATCH_SIZE) -> np.ndarray:
"""批次 embedding,避免 API 頻繁呼叫"""
all_embeddings: list[np.ndarray] = []
for i in range(0, len(texts), batch_size):
batch = texts[i:i+batch_size]
resp = client.embeddings.create(model=EMBED_MODEL, input=batch)
embs = [d.embedding for d in resp.data]
all_embeddings.extend(embs)
return np.array(all_embeddings, dtype="float32")
可以用「圖書館」來比喻:

除了基本的「向量化 + 索引」之外,在真實系統中還會遇到:
📌 這些議題我會在 Day19(可觀測性)、Day21(快取機制)、Day22(版本治理)、Day27(FAQ Bot 驗收) 再深入討論。
在 Day 4 我們比較過不同的 向量資料庫(FAISS、Pinecone、Milvus、Weaviate)。今天則是實際動手,從「乾淨的文件片段」更進一步,完成了 向量化 與 索引建立:
有了向量與索引,我們的知識庫正式成為「語意可檢索的資料庫」。不過,光是檢索到候選文件還不夠,排序策略會直接影響答案品質。
明天(Day 10),我們會進一步探討 檢索策略設計 (Retriever Design),看看如何把「問 → 找 → 回答」 這個流程設計得更聰明,並串成完整的 RAG Pipeline。


 iThome鐵人賽
iThome鐵人賽