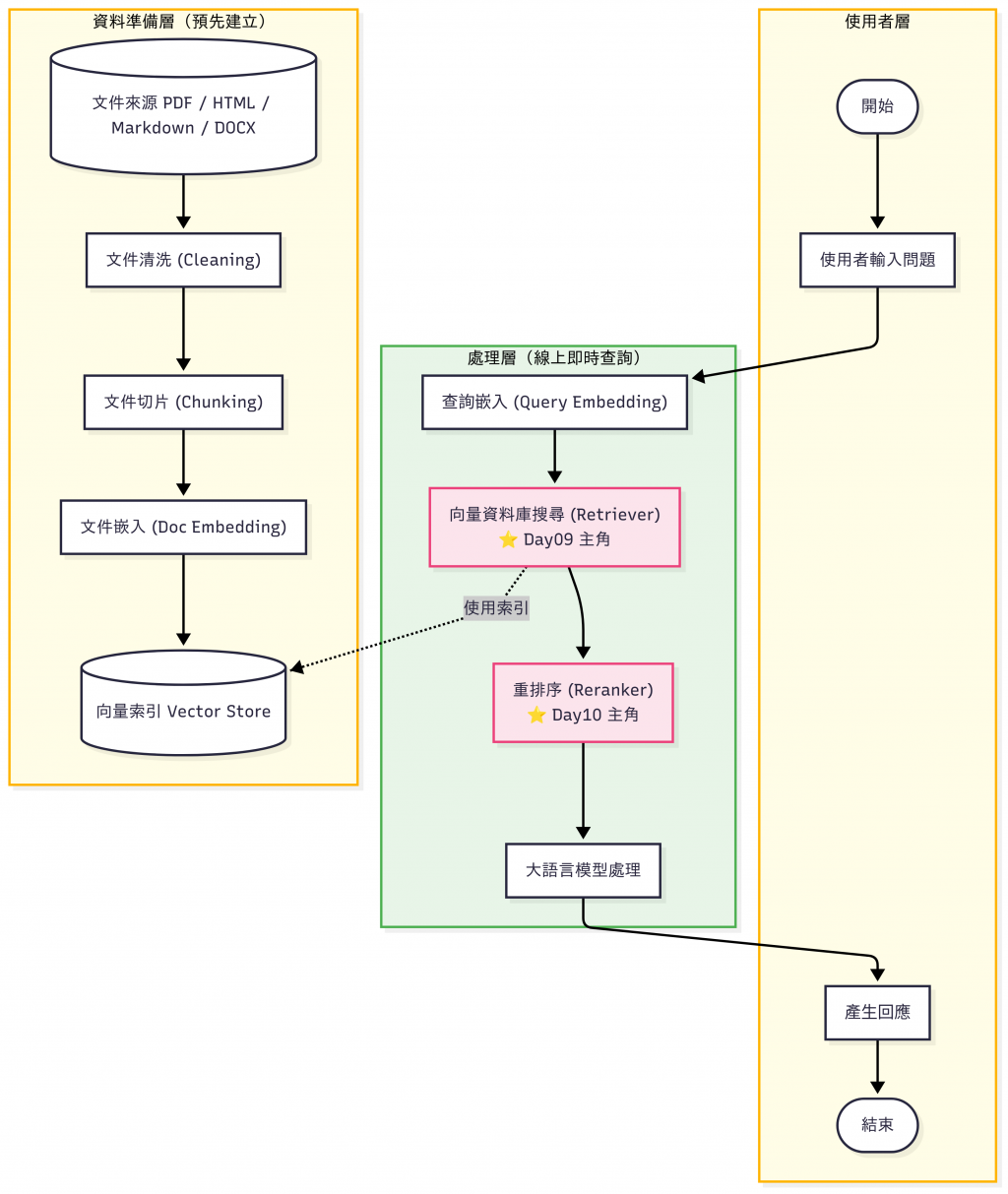
昨天(Day 9)我們已經完成了 文件向量化 和 索引建立,現在我們擁有一個能快速查詢的向量資料庫。 但光靠索引檢索出來的結果,往往只是一個「初步的候選清單」。
舉例來說:
如果直接把這些結果丟給 LLM,答案可能會不精準。
因此,我們需要在 檢索器 (Retriever) 之後,加上一層 重排序器(Reranker),對候選文件進行更精準的排序。
ms-marco 系列)、LLM-based Reranker。
完整可執行專案 已經放在 GitHub。
目的:快速、粗略地找到「可能相關」的文件。
candidates.json,方便後續使用。# retriever_faiss_demo.py
import json
import numpy as np
import faiss
from sentence_transformers import SentenceTransformer
from huggingface_hub import snapshot_download
from tqdm import tqdm
import os
# ----- 測試資料集 -----
DOCS = [
# 正確答案
"本公司總部位於台北市信義區松高路 11 號。",
# 背景資訊
"公司創立於 2012 年,專注雲端與資料服務。",
"我們在新加坡、東京與舊金山設有分公司據點。",
# 混淆干擾
"總部附近交通:捷運市政府站步行 5 分鐘可達。",
"總部附近有一間 Starbucks 咖啡廳,常有員工聚會。",
"公司每年會在台北 101 舉辦年會。",
# 無關雜訊
"請假制度:員工需提前一天申請,緊急情況可事後補辦。",
"客戶成功部門負責售後導入與教育訓練。",
"年度目標:拓展東南亞市場並優化資料平台。",
]
QUERY = "公司的總部在哪裡?"
TOP_K = 5
EMB_MODEL_NAME = "sentence-transformers/all-MiniLM-L6-v2"
OUT_PATH = "candidates.json"
# -------------------
def download_with_progress(model_name: str) -> str:
"""
下載 HuggingFace 模型(帶 tqdm 進度條)。
第一次會下載,之後會直接使用本地快取。
"""
local_dir = os.path.join("models", model_name.replace("/", "_"))
if not os.path.exists(local_dir):
print(f"🔽 正在下載模型: {model_name}")
snapshot_download(
repo_id=model_name,
local_dir=local_dir,
resume_download=True,
tqdm_class=tqdm
)
else:
print(f"✅ 已找到本地模型: {local_dir}")
return local_dir
if __name__ == "__main__":
print("使用模型進行嵌入 (embedding):", EMB_MODEL_NAME)
# 確保模型存在(會下載或直接讀本地)
local_model_path = download_with_progress(EMB_MODEL_NAME)
embed_model = SentenceTransformer(local_model_path)
# ----- 文件與查詢向量化 -----
doc_embeds = embed_model.encode(DOCS, convert_to_numpy=True, normalize_embeddings=True)
q_embed = embed_model.encode([QUERY], convert_to_numpy=True, normalize_embeddings=True)
# 使用內積(normalize 後等同於 cosine 相似度)
dim = doc_embeds.shape[1]
index = faiss.IndexFlatIP(dim)
index.add(doc_embeds.astype("float32"))
D, I = index.search(q_embed.astype("float32"), TOP_K)
idxs = I[0].tolist()
scores = D[0].tolist()
candidates = [
{"rank": r + 1, "idx": i, "text": DOCS[i], "retriever_score": float(s)}
for r, (i, s) in enumerate(zip(idxs, scores))
]
print(f"\n查詢 (Query): {QUERY}\n")
print("=== 檢索器 (Retriever) Top-K 結果(未重排)===")
for c in candidates:
print(f"[R{c['rank']:02d}] 分數={c['retriever_score']:.4f} | idx={c['idx']} | {c['text']}")
payload = {"query": QUERY, "candidates": candidates}
with open(OUT_PATH, "w", encoding="utf-8") as f:
json.dump(payload, f, ensure_ascii=False, indent=2)
print(f"\n已輸出候選結果到 {OUT_PATH}(包含 query 與 Top-{TOP_K} 候選)")
執行結果:
❯ python retriever_faiss_demo.py
使用模型進行嵌入 (embedding): sentence-transformers/all-MiniLM-L6-v2
✅ 已找到本地模型: models/sentence-transformers_all-MiniLM-L6-v2
查詢 (Query): 公司的總部在哪裡?
=== 檢索器 (Retriever) Top-K 結果(未重排)===
[R01] 分數=0.8457 | idx=0 | 本公司總部位於台北市信義區松高路 11 號。
[R02] 分數=0.8172 | idx=5 | 公司每年會在台北 101 舉辦年會。
[R03] 分數=0.8144 | idx=1 | 公司創立於 2012 年,專注雲端與資料服務。
[R04] 分數=0.7089 | idx=2 | 我們在新加坡、東京與舊金山設有分公司據點。
[R05] 分數=0.6201 | idx=3 | 總部附近交通:捷運市政府站步行 5 分鐘可達。
已輸出候選結果到 candidates.json(包含 query 與 Top-5 候選)
這支程式會生成 candidates.json :
{
"query": "公司的總部在哪裡?",
"candidates": [
{
"rank": 1,
"idx": 0,
"text": "本公司總部位於台北市信義區松高路 11 號。",
"retriever_score": 0.8457049131393433
},
{
"rank": 2,
"idx": 5,
"text": "公司每年會在台北 101 舉辦年會。",
"retriever_score": 0.817213773727417
},
...
...
]
}
可以看到粗排的結果,雖然正確答案在第一位,但後續排名靠前的回答並不一定和總部的位置相關。
本文範例資料集為筆者自建的虛構內容,僅用於說明 Retriever 與 Reranker 的差異,並非真實公司資料。
目的:把 Retriever 找到的候選,再進一步「精挑細選」。
步驟:
candidates.json 裡的候選清單。輸出:
# reranker_cross_encoder_demo.py
import json
import torch
from transformers import AutoTokenizer, AutoModelForSequenceClassification
IN_PATH = "candidates.json"
OUT_PATH = "reranked.json"
CE_MODEL_NAME = "BAAI/bge-reranker-v2-m3"
def load_candidates(path):
with open(path, "r", encoding="utf-8") as f:
data = json.load(f)
return data["query"], data["candidates"]
def rerank(query, texts, model_name=CE_MODEL_NAME, batch_size=8, max_len=256):
tok = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForSequenceClassification.from_pretrained(model_name)
model.eval()
scores = []
with torch.no_grad():
for start in range(0, len(texts), batch_size):
batch_docs = texts[start:start + batch_size]
inputs = tok(
[query] * len(batch_docs),
batch_docs,
padding=True,
truncation=True,
max_length=max_len,
return_tensors="pt",
)
logits = model(**inputs).logits.squeeze(-1) # (batch_size,)
scores.extend(logits.cpu().tolist())
return scores
def main():
query, candidates = load_candidates(IN_PATH)
print(f"查詢 (Query): {query}\n")
print("=== 檢索器 (Retriever) Top-K(原始順序)===")
for c in candidates:
print(f"[R{c['rank']:02d}] ret={c['retriever_score']:.4f} | idx={c['idx']} | {c['text']}")
texts = [c["text"] for c in candidates]
re_scores = rerank(query, texts)
merged = []
for c, re_s in zip(candidates, re_scores):
merged.append({
**c,
"reranker_score": float(re_s),
})
# 依 Reranker 分數排序
reranked = sorted(merged, key=lambda x: x["reranker_score"], reverse=True)
print("\n=== 重排序器 (Reranker) Top-3 ===")
for i, c in enumerate(reranked[:3], 1):
print(f"[R*{i:02d}] re={c['reranker_score']:.4f} | ret={c['retriever_score']:.4f} | idx={c['idx']} | {c['text']}")
print("\n=== 完整對照:retriever vs reranker ===")
for i, c in enumerate(reranked, 1):
print(f"[{i:02d}] re={c['reranker_score']:.4f} | ret={c['retriever_score']:.4f} | idx={c['idx']} | {c['text']}")
# 輸出結果到 reranked.json,day11 會用到
out_payload = {
"query": query,
"model": CE_MODEL_NAME,
"retriever": candidates, # 原始候選(保留原 rank 與 retriever_score)
"reranked": reranked, # 重排後(含 reranker_score 與新 rerank_rank)
}
with open(OUT_PATH, "w", encoding="utf-8") as f:
json.dump(out_payload, f, ensure_ascii=False, indent=2)
print(f"\n已輸出重排結果到 {OUT_PATH}")
if __name__ == "__main__":
main()
執行結果:
❯ python reranker_cross_encoder_demo.py
查詢 (Query): 公司的總部在哪裡?
=== 檢索器 (Retriever) Top-K(原始順序)===
[R01] ret=0.8457 | idx=0 | 本公司總部位於台北市信義區松高路 11 號。
[R02] ret=0.8172 | idx=5 | 公司每年會在台北 101 舉辦年會。
[R03] ret=0.8144 | idx=1 | 公司創立於 2012 年,專注雲端與資料服務。
[R04] ret=0.7089 | idx=2 | 我們在新加坡、東京與舊金山設有分公司據點。
[R05] ret=0.6201 | idx=3 | 總部附近交通:捷運市政府站步行 5 分鐘可達。
=== 重排序器 (Reranker) Top-3 ===
[R*01] re=3.5744 | ret=0.8457 | idx=0 | 本公司總部位於台北市信義區松高路 11 號。
[R*02] re=-5.0353 | ret=0.8172 | idx=5 | 公司每年會在台北 101 舉辦年會。
[R*03] re=-5.4934 | ret=0.7089 | idx=2 | 我們在新加坡、東京與舊金山設有分公司據點。
=== 完整對照:retriever vs reranker ===
[01] re=3.5744 | ret=0.8457 | idx=0 | 本公司總部位於台北市信義區松高路 11 號。
[02] re=-5.0353 | ret=0.8172 | idx=5 | 公司每年會在台北 101 舉辦年會。
[03] re=-5.4934 | ret=0.7089 | idx=2 | 我們在新加坡、東京與舊金山設有分公司據點。
[04] re=-7.4305 | ret=0.6201 | idx=3 | 總部附近交通:捷運市政府站步行 5 分鐘可達。
[05] re=-8.1101 | ret=0.8144 | idx=1 | 公司創立於 2012 年,專注雲端與資料服務。
已輸出重排結果到 reranked.json
這隻程式會生成 reranked.json,是排序後的結果,這份結果會在 day11 的程式裡用到 :
{
"query": "公司的總部在哪裡?",
"model": "BAAI/bge-reranker-v2-m3",
"retriever": [
{
"rank": 1,
"idx": 0,
"text": "本公司總部位於台北市信義區松高路 11 號。",
"retriever_score": 0.8457049131393433
},
{
"rank": 2,
"idx": 5,
"text": "公司每年會在台北 101 舉辦年會。",
"retriever_score": 0.817213773727417
},
...
...
],
"reranked": [
{
"rank": 1,
"idx": 0,
"text": "本公司總部位於台北市信義區松高路 11 號。",
"retriever_score": 0.8457049131393433,
"reranker_score": 3.5743699073791504
},
{
"rank": 2,
"idx": 5,
"text": "公司每年會在台北 101 舉辦年會。",
"retriever_score": 0.817213773727417,
"reranker_score": -5.035323143005371
},
...
...
],
}
可以看到排序後的結果順序是有變的,但是 101 那個結果因為太不相關變成負的 XD。
我選擇 BAAI/bge-reranker-v2-m3,是因為它在中文的檢索任務中效果穩定,尤其在繁中環境比起許多英文模型優勢明顯。不過這樣做也伴隨一些風險:模型可能受到中國法律規範的約束,存在跨境資料流、內容審查或資料要求等潛在疑慮。因此在實際應用中(尤其是涉及敏感資料或政府/企業機密時),建議:
在真實企業環境中,建議結合 規則過濾 + 模型安全檢測 + 法規遵循,才能安全落地。
我後來另外寫了支程式(compare_rerankers.py)比較以下 Reranker 模型:
執行結果:
❯ python compare_rerankers.py
查詢: 公司的總部在哪裡?
=== BAAI/bge-reranker-v2-m3 ===
Top1: 本公司總部位於台北市信義區松高路 11 號。 (score=0.9727)
Top2: 總部附近有一間 Starbucks 咖啡廳,常有員工聚會。 (score=0.0096)
Top3: 公司每年會在台北 101 舉辦年會。 (score=0.0065)
耗時: 1.94 秒
=== cross-encoder/ms-marco-MiniLM-L-12-v2 ===
Top1: 本公司總部位於台北市信義區松高路 11 號。 (score=0.9996)
Top2: 公司創立於 2012 年,專注雲端與資料服務。 (score=0.9993)
Top3: 我們在新加坡、東京與舊金山設有分公司據點。 (score=0.9993)
耗時: 0.18 秒
=== OpenAI GPT-4o-mini ===
Top1: 本公司總部位於台北市信義區松高路 11 號。 (score=5.00)
Top2: 公司每年會在台北 101 舉辦年會。 (score=3.00)
Top3: 我們在新加坡、東京與舊金山設有分公司據點。 (score=2.00)
耗時: 13.42 秒
查詢:「公司的總部在哪裡?」
正確答案:「本公司總部位於台北市信義區松高路 11 號。」
| 模型 | 語言適用性 | 準確度 | 延遲 (秒) | Top1 | Top2 | Top3 | 備註 |
|---|---|---|---|---|---|---|---|
| BGE v2-m3 | 多語言(含繁中) | ✅ 高 | ⚡ 1.9 | ✅ 總部松高路 11 號 | Starbucks 咖啡廳 | 台北 101 年會 | 免費、效果佳 |
| MiniLM-L-12-v2 | 英文限定 | ⚠️ 繁中偏弱 | ⚡ 0.18 | ✅ 總部松高路 11 號 | 公司創立於 2012 | 新加坡 / 東京 / 舊金山據點 | 需翻譯 pipeline 才能用 |
| GPT-4o-mini | 全語言 | ✅ 高 | 🐢 13.4 | ✅ 總部松高路 11 號 | ❌ 台北 101 年會 | 新加坡 / 東京 / 舊金山據點 | 收費,最穩定 |
可以看到以繁中而言還是 BGE 的支援度較好,但他和 GPT 一樣都會被 101 年會干擾,另外由於GPT 是雲端模型,所以會有較長的延遲和相對較高的成本。如果要做大規模的 Rerank,還是推薦本地模型比較好,如果不限語言的話 MiniLM 的速度會是最快的。
想像你走進圖書館問館員:「我要找資料庫設計的書」。
這樣你就不會被一堆雜訊干擾,而是直接拿到最相關的答案。

| 特性 | Retriever(檢索器) | Reranker(重排序器) |
|---|---|---|
| 主要目的 | 快速縮小搜尋範圍,抓出候選文件 | 精準排序候選文件,挑最相關的 |
| 運作方式 | 向量相似度(Cosine / L2)、HNSW、IVF | Cross-Encoder / LLM 判斷查詢與文件的相關性 |
| 速度 | ⚡ 很快(毫秒級) | 🐢 較慢(需要深度計算) |
| 準確度 | 中等(可能帶雜訊) | 高(能理解細微語意差異) |
| 成本 | 低(一次 embedding + 相似度計算) | 高(每個候選都要跑模型) |
| 適合場景 | 大規模的知識庫、第一層篩選 | 高精度問答、需要避免幻覺(hallucination)的場合 |
| 查詢類型 | 範例問題 | 範例行為 | Retriever 適用度 | Reranker 必要性 | 建議策略 |
|---|---|---|---|---|---|
| 事實查詢(地點、人名、數字) | 「公司總部在哪裡?」 | Retriever 就能很快找到「總部地址」相關句子,Reranker 再把真正的地址排到最前。 | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | Top-k=20 + Rerank=Top-5 |
| 定義/概念解釋 | 「什麼是零信任架構?」 | Retriever 會找出所有提到「零信任」的段落,Reranker 再把真正解釋概念的那段往前排。 | ⭐⭐⭐ | ⭐⭐⭐⭐ | 先 Top-k,再 Rerank=Top-3 |
| 多跳(Multi-hop Reasoning)推理等需要多份文件的相關資訊 | 「新人在台北總部週末報到,要怎麼領筆電?」 | 需要兩跳動作:① 找到「台北總部報到流程」② 找到「筆電領用規則(僅限工作日)」,組合後才得到完整答案。 | ⭐⭐ | ⭐⭐⭐⭐⭐ | 提高 Top-k + Rerank 並且做上下文組裝(Context Assembly) |
Day 10 的重點:
明天(Day 11),我們將進一步探討 上下文組裝 (Context Assembly):
如何把這些檢索結果「組裝」成 Prompt,餵給 LLM,確保輸出更精準。

