昨天我們做了一個最小可行的 QA Bot,但知識庫的單位是「整句 FAQ」,格式非常乾淨。
然而真實情況下,文件來源可能包含:
如果不處理,用戶查詢得到的答案品質會非常差。
原始文件:
公司制度:
加班申請需事先提出,加班工時可折換補休。
出差申請需填寫出差單,並附上行程與預算。
報銷規則需要提供發票,金額超過 1000 需經理簽核。
所以在 RAG pipeline 裡,我們還需要再加入兩個步驟:文件清洗 (Cleaning) 和 文件切片 (Chunking)。
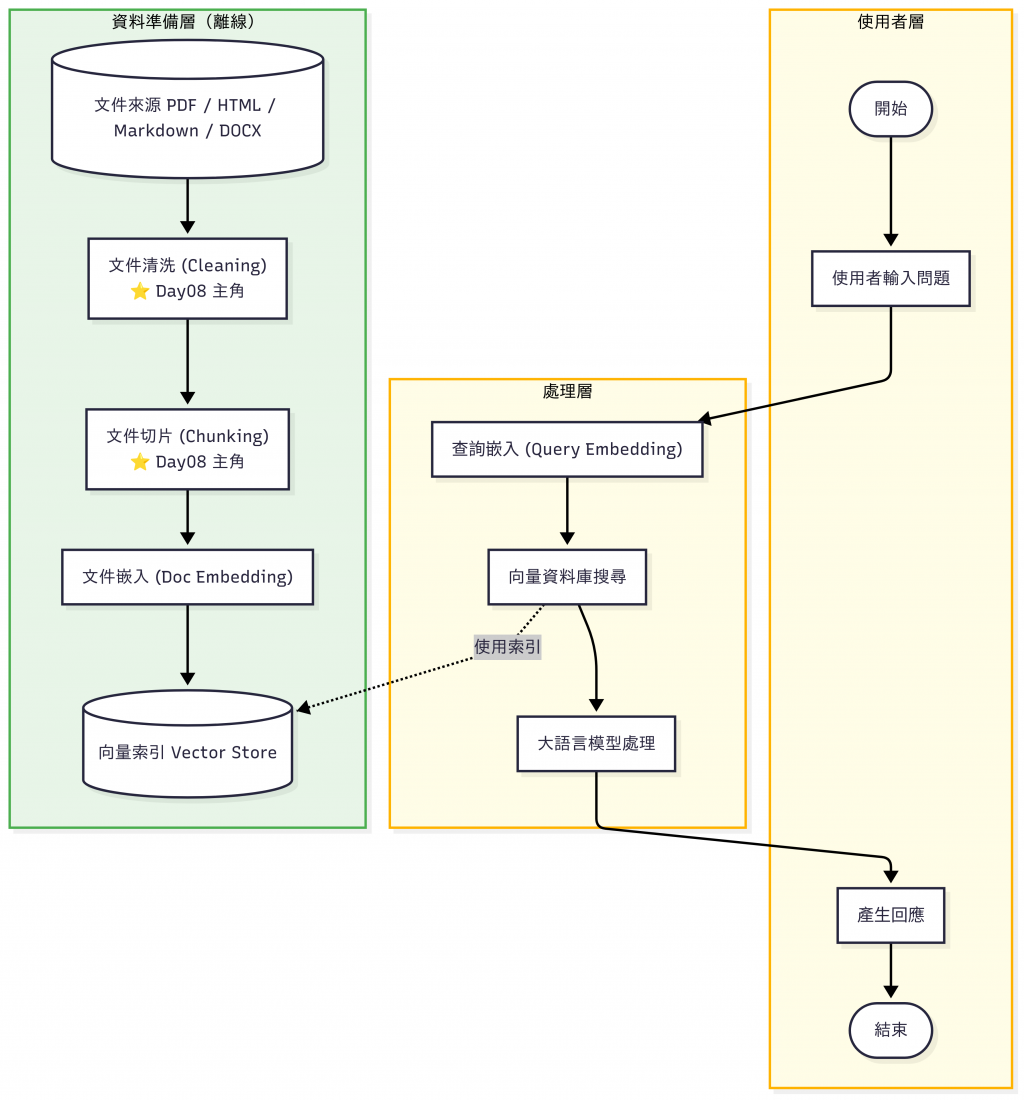
1. 查詢嵌入 (Query Embedding):線上進行,把使用者的提問轉成向量,用來跟資料庫比對。(Day10 會聊到這塊)
2. 文件嵌入 (Doc Embedding):離線處理,把知識文件轉成向量並建立索引,讓線上查詢可以快速檢索。(Day09 會聊到這塊)
文件清洗的目標是把「可讀但雜訊太多」的原文,變成「乾淨、結構保留、容易切片」的文字。建議用下面這個安全順序處理:
目錄 / Table of Contents / 返回首頁 / 下一頁 / 版權 / Copyright / 廣告
<nav>、<aside>、script、style>。NFKC(全形→半形、符號統一)。\t、\r、\u00A0、\u3000 → 單一空白;連續空行壓成最多兩行。!!!→!),保留句讀(。?!;)以利後續切句。10K→10,000、5k→5,000;貨幣符號統一(例:NT$→NTD)。#)、清單(-/1.)、程式碼塊(…)。文件多語時,偵測語言後只保留指定語言(如 zh/en)。
⚠️ 短句子易誤判,可對段落而非單句做語言濾除。
這邊需要對照 GitHub Repo 的 cleaning_demo.py 參考,文中僅擷取片段。
主程式如下,我們會用幾個函式執行上述五步驟 (去雜訊、正規化、保留結構、語言過濾、以及去重):
if __name__ == "__main__":
raw_html = """
<html>
<head><title>公司規章</title></head>
<body>
<nav>返回首頁|目錄|下一頁</nav>
<aside>廣告:買一送一!</aside>
<h1>公司制度</h1>
<p>加班申請:需事先提出,加班工時可折換補休!!!</p>
<p>出差申請:需填寫出差單,並附上行程與預算。 請參考「Table of Contents」。</p>
<p>獎金上限為 10K 或 NT$5000,以較低者為準。</p>
<script>alert('ads')</script>
<footer>Copyright 2025</footer>
<h2>清單範例</h2>
<ul>
<li> A 條款</li>
<li> B 條款</li>
</ul>
<pre>
Some code block
should keep spaces
</pre>
<p>English note: Budget cap is 5k only?!</p>
<p>重複段落示例。</p>
<p>重複段落示例。</p>
<p>短</p>
<p>
{code}
</p>
<p>結束</p>
</body>
</html>
""".replace("{code}", "```\\nprint('hi')\\n```")
cleaned = clean_document(raw_html, is_html=True, lang_keep=("zh", "en"))
print("=== 清洗後段落 ===")
for i, p in enumerate(cleaned, 1):
print(f"[{i}] {p}")
執行結果:
❯ python cleaning_demo.py
=== 清洗後段落 ===
[1] 加班申請:需事先提出,加班工時可折換補休!
[2] 出差申請:需填寫出差單,並附上行程與預算。 請參考「」。
[3] 獎金上限為 10,000 或 NTD 5000,以較低者為準。
[4] Some code block should keep spaces
[5] English note: Budget cap is 5,000 only?!
這一步的目的是把文件變得更乾淨,避免在檢索時被無用內容干擾。
但是光是乾淨還不夠,因為 文件往往太長,需要再進行「合理切片 (Chunking)」。
在清洗完文件後,接下來就是「如何切片」,文件切片的目的是讓文件單位更適合檢索與語意匹配。
在 RAG 中,最核心的流程是:查詢 → 檢索 (Retriever) → 回答。
那檢索到底是針對什麼單位做的?這就是 Chunking 的意義。
如果不進行 Chunking,會遇到幾個問題:
所以我們需要把文件切成「合理大小」的片段:
N 個字元 / tokens 切一次。def chunk_fixed(text, size=20, overlap=5):
words = list(text) # 以「字元」為單位
chunks = []
for i in range(0, len(words), size - overlap):
chunks.append("".join(words[i:i+size]))
return chunks
sample = """加班申請需事先提出,加班工時可折換補休。
出差申請需填寫出差單,並附上行程與預算。
報銷規則需要提供發票,金額超過 1000 需經理簽核。
員工請假需提前一天申請,緊急情況可事後補辦。
遲到超過三次需與主管面談,嚴重者列入考核。"""
print(chunk_fixed(sample, size=20, overlap=5))
在 Chunking 時,我們常常會加上 Overlap(重疊區)。
意思是:在切片的時候,每個 Chunk 之間保留一小段重疊文字,避免語意被硬生生切斷。
📌 舉例
假設一段文字有 50 個詞,我們設定 size=20, overlap=5:
這樣可以確保:
✅ 一般建議 overlap 大小:chunk size 的 10%~20%。
例如:chunk size=200 tokens,overlap=20 tokens。
import re
def chunk_sentence(text):
sentences = re.split(r"。|!|?|\n", text)
return [s.strip() for s in sentences if s.strip()]
sample = """加班申請需事先提出,加班工時可折換補休。
出差申請需填寫出差單,並附上行程與預算。
報銷規則需要提供發票,金額超過 1000 需經理簽核。
員工請假需提前一天申請,緊急情況可事後補辦。
遲到超過三次需與主管面談,嚴重者列入考核。
"""
print(chunk_sentence(sample))
import re
def chunk_semantic(text):
# 先斷句(技術步驟,不特別當作一種方法)
sentences = re.split(r"[。!?]", text)
sentences = [s.strip()+"。" for s in sentences if s.strip()]
chunks, cur, cur_lab = [], [], None
for s in sentences:
lab = "attend" if any(k in s for k in ATTEND) else "admin"
if cur_lab is None or lab == cur_lab:
cur.append(s); cur_lab = lab
else:
chunks.append("".join(cur)); cur = [s]; cur_lab = lab
if cur:
chunks.append("".join(cur))
return chunks
sample = """加班申請需事先提出,加班工時可折換補休。
出差申請需填寫出差單,並附上行程與預算。
報銷規則需要提供發票,金額超過 1000 需經理簽核。
員工請假需提前一天申請,緊急情況可事後補辦。
遲到超過三次需與主管面談,嚴重者列入考核。"""
ADMIN = {"加班","出差","報銷","發票","簽核","預算"}
ATTEND = {"請假","遲到","面談","考核","緊急"}
print(chunk_semantic(sample))
假設原始文本:
加班申請需事先提出,加班工時可折換補休。
出差申請需填寫出差單,並附上行程與預算。
報銷規則需要提供發票,金額超過 1000 需經理簽核。
員工請假需提前一天申請,緊急情況可事後補辦。
遲到超過三次需與主管面談,嚴重者列入考核。
不同策略的結果:
| 策略 | 範例執行結果 |
|---|---|
| 固定長度切片 | ['加班申請需事先提出,加班工時可折換補休。出差申請需填寫出差單,並附上行程與預算。報銷規則需要提供發票,金額超過 1000 需經理簽核。與預算。'] |
| 句子切片 | ['加班申請需事先提出,加班工時可折換補休', '出差申請需填寫出差單,並附上行程與預算', '報銷規則需要提供發票,金額超過 1000 需經理簽核', '員工請假需提前一天申請,緊急情況可事後補辦', '遲到超過三次需與主管面談,嚴重者列入考核'] |
| 語意切片 | ['加班申請需事先提出,加班工時可折換補休。出差申請需填寫出差單,並附上行程與預算。報銷規則需要提供發票,金額超過 1000 需經理簽核。', '員工請假需提前一天申請,緊急情況可事後補辦。遲到超過三次需與主管面談,嚴重者列入考核。'] |
| 策略 | 優點 | 缺點 | 適用場景 |
|---|---|---|---|
| 固定長度切片 | 實作簡單、速度快 | 可能切壞語意,片段不自然 | Demo、小規模測試 |
| 句子切片 | 保留語意自然、易懂 | 句子長度不一,可能過長 | FAQ、政策文件、說明文件 |
| 語意切片 | 能保持語意連貫,把同一主題的多句話聚在一起 | 需要額外計算(Embedding/關鍵詞比對),成本較高 | 複雜文件、大型知識庫 |
📌 以下數字僅為示意範例,實際數值會依文件內容、切片策略與語料而有所不同。
| 指標 | 說明 | 清洗前 | 清洗後 |
|---|---|---|---|
| 平均 Chunk 長度 | 每個 chunk 的平均 Token 數 | 1200 tokens | 180 tokens |
| 長尾分佈 | 是否有超長段落 | 有(最大 5000 tokens) | 無(控制在 300 以下) |
| 重複率 | 相同段落是否多次出現 | 15% | <1% |
| Top-k 命中率 | 檢索時,正確答案是否出現在前 k 筆 | 60% | 85% |
前言有提過 Token 成本可以透過 Chunking 來節省,這裡用數字量化來看對 token 成本的影響:
👉 清洗與合理 Chunking,能讓檢索更精準、上下文更聚焦。
| 工具 / 框架 | 特點 | 適用情境 | 缺點 |
|---|---|---|---|
| Unstructured | 支援 PDF / Office / HTML / Email / 圖片 OCR,多格式解析 | 異質文件多的情境 | 安裝依賴較多 |
| trafilatura | 專精網頁正文擷取,效果好 | 網頁知識庫清洗 | 僅限 HTML |
| LangChain Splitter | 提供 Recursive / Token-based / Markdown-aware 分割器 | 一般 RAG 開發 | 須依賴 LangChain 生態 |
| Haystack PreProcessor | 支援切片 + 過濾 + metadata pipeline | 需要整合 DocumentStore 的場景 | 需學習 Haystack 架構 |
現成工具很好用,不過它們的核心其實就是在做:
如果對這些原理有點概念,會比較容易:
今天我們學到:
在實務上,最常見的做法是先依照 句子切片 再透過適度 overlap。既保留語意完整,即使句子被切在邊界,依舊可以保有上下文,也能控制 Token 成本。有了乾淨、合理切片的文件,我們就能進入下一步:
👉 向量化與索引建立 (Vectorization & Indexing),把資料存進 Vector Database!

