
雖然在前幾個章節,有提到 Observability 2.0 期望打破三大支柱的概念,回歸到資料本身來做處理與觀測。但是,為了溝通與定義方便,OpenTelemetry 還是有將遙測資料分為四大類別,分別是 Metrics, Logs, Traces 及 Baggages,並將這四大類型的遙測資料稱之為訊號(signal)。我們可以將不同的 signal 組合在一起,從不同的角度來觀察系統的內部情況。
今天首先來介紹 Metrics。它是在系統運行中所測量到的紀錄。除了拿到測量值以外,還會記錄抓取數值當下的時間,及其他能夠呈現系統狀態的 metadata。讓我們來了解它在 OpenTelemetry 中的規範吧!
OpenTelemetry 使用 API 和 SDK 來收集應用程式的 telemetry,而根據特定的 signal 則有不同的元件使用,以下將一一介紹。
根據這張架構圖,讓我們來一一拆解這些元件的用途: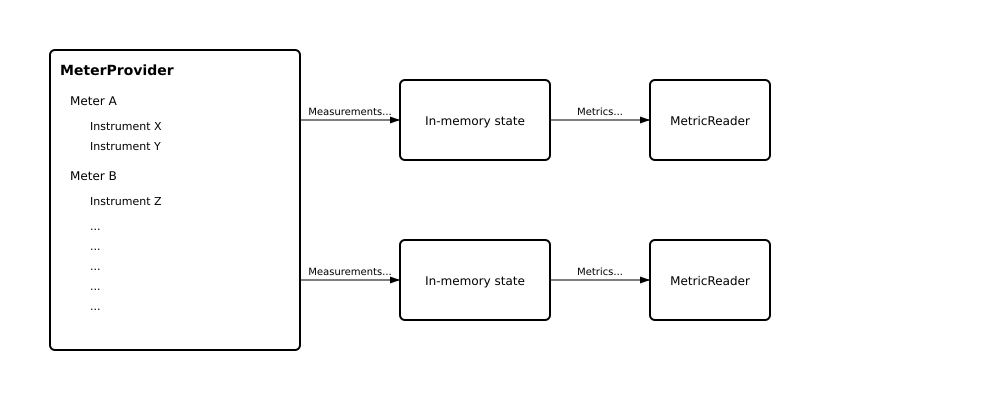
架構圖取自官方文件。可以看到 Meter Provider之下可以有多個 Meter,一個 Meter 可以產生多個 instrument。最後,這些測量值將會一併被送往MeterReader,最後透過 Exporter 送到指定的後端
它扮演著工廠的角色,可以生成許多的 Meter。其命週期會和應用程式相同。我們可以在這個層級去定義 Resource attribute,其定義的值將會被底下的 Meter 所繼承。
同時,它的生命週期也會和應用程式相同,在一個應用程式中只需要初始化一次。當我們初始化 Meter Provider 時,它也會一併初始化 Resource 和 Exporter。
就是 Meter Provider 生成的產物。它代表的層級是「服務」,例如,在同一個 Meter Provider 下,我可以生成兩個 Meter,這兩個 Meter 可以分別代表 GitLab Runner 以及 BlackDuck 兩個服務。接著,在 Meter 之下便可開始收集系統的測量值(instrument)。根據官方文件,測量值可分為四大種類,根據情境所使用的測量值則不同,可分為 Counter、UpDownCounter、Gauge、Histogram,除了 Histogram 之外,又可再依照資料是否聚合而再細分為同步與非同步,詳細的說明將在下個段落中介紹。
在每筆 metrics instrument 中,一定會包含兩個資訊,分別是 Name 以及 Kind,開發者可依據自己的需求增添資料的單位 Unit 以及 Description。
收集完資料後,Exporter 便會協助把資料發送出去,這裡的目的地可以是一個儲存後端,也可以是 OpenTelemetry Collector。而可以匯出的目的地以及資料格式將會因 SDK 的設計而不盡相同。以 Python SDK 為例,目前(2025年9月之前)的 SDK 只支援匯出 protobuf格式,而直接支援的儲存後端則包含 Prometheus, Zipkin 與 Jaeger。
前一個段落說明了資料從產生到匯出的元件架構,而 OpenTelemetry 的 Data Model 則定義了資料在這個過程中如何被轉換。根據官方規範,資料轉換遵循以下模式:
Events → Data Stream → Timeseries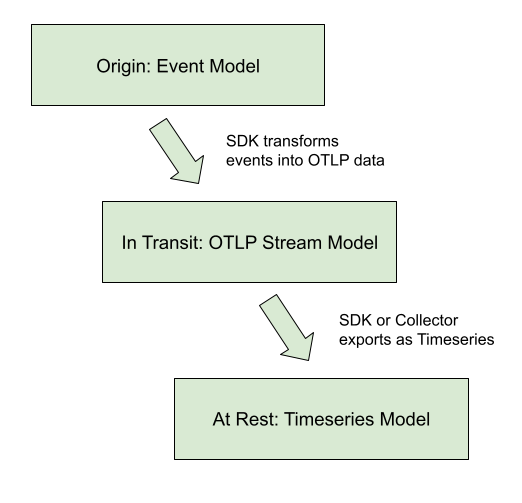
當應用程式呼叫 API 時產生的原始測量事件:
counter.add(1, {"method": "GET", "status": "200"}) # 產生一個事件
SDK 將相同 instrument 和屬性的事件組織成資料流,這是 OTLP 中的核心概念:
# 同一個 counter 的多次呼叫會形成一個 Data Stream
counter.add(1, {"method": "GET", "status": "200"}) # Event 1
counter.add(1, {"method": "GET", "status": "200"}) # Event 2
counter.add(1, {"method": "POST", "status": "201"}) # Event 3 (不同屬性,另一個 Data Stream)
資料流經過聚合處理後(也就是資料從instrument、View 走到 Exporter),轉換為最終的時間序列格式,準備傳輸:
{
"metric": {
"name": "http_requests_total",
"sum": {
"dataPoints": [
{
"timeUnixNano": "1643723400000000000",
"value": 150,
"attributes": [{"key": "method", "value": "GET"}]
}
]
}
}
}
再結合我們剛剛學習過的元件架構,可以得知每個元件是有層級的,而在每個層級我們可以訂定不同的 attribute。根據 OTLP 的結構,完整的 Metrics 資料層級如下:
ResourceMetrics {
├── Resource Attribute (服務名稱、版本等)
└── ScopeMetrics []
├── Scope (Meter 的識別資訊)
└── Metrics []
├── Metric 基本資訊
│ ├── Name
│ ├── Unit
│ └── Description
└── DataPoints []
├── timestamp
├── Attribute (instrument 層級)
└── Value
}
這個結構清楚地反映了:
在 OpenTelemetry 中,SDK 會將一段時間內的多個測量事件聚合成單一的數據點。Temporality 決定了這些聚合後的數據點要如何表示:
範例:假設一個 counter 在不同時間點收到多次 add() 呼叫
時間點 t0: 總共發生了 5 次事件 → 傳送 5
時間點 t10: 總共發生了 10 次事件 → 傳送 10 (累積總數)
時間點 t20: 總共發生了 20 次事件 → 傳送 20 (累積總數)
時間點 t30: 總共發生了 40 次事件 → 傳送 40 (累積總數)
範例:同樣的 counter,但只傳送每個時間段的變化量
時間點 t0: 這段時間發生了 5 次事件 → 傳送 5
時間點 t10: 這段時間新增了 5 次事件 → 傳送 5 (10-5)
時間點 t20: 這段時間新增了 10 次事件 → 傳送 10 (20-10)
時間點 t30: 這段時間新增了 20 次事件 → 傳送 20 (40-20)
實際上,大多數情況下你不需要手動配置 aggregation 的方法,OpenTelemetry SDK 會自動處理掉這一段。但是,SDK 也支援透過 View 來修改預設的聚合行為、過濾屬性,以及控制哪些 metrics 要被收集。
今天介紹完 Metrics 在 OpenTelemetry 中收集的規範,理解 API 和 SDK 中的相關元件,以及將 event 轉換到 time serise data的資料模型定義,更了解了 OpenTelemetry 在處理資料聚合的兩種方法,並可以透過 SDK 進行客製化。明天,讓我們繼續探討 log 在 OpenTelemetry 中的規範,了解該怎麼生成並收集 Log 吧!
Grafana Labs - OpenTelemetry metrics: A guide to Delta vs. Cumulative temporality trade-offs
Last9 - OpenTelemetry Metrics Aggregation: A Detailed Guide
OpenTelemetry Docs - OTel 1.49.0 Metrics Data Model
Rox Williams - OpenTelemetry Metrics Explained: A Guide for Engineers

 iThome鐵人賽
iThome鐵人賽