
相較於 metrics 與 traces,logs 算是在這些 signals 當中使用最普及的。許多程式語言幾乎都有自己內建的函式庫以支援輸出 log,同時業界中也有許多處理 logs 的 library 可供使用。因此對於 OpenTelemetry 來說,要怎麼讓 logs 能和其他 signals 進行整合,又能支援並整合現有的函式庫,就變成了很大的挑戰。
在 Observability 1.0 的概念中,我們認為原先三大支柱的資料過於分散,導致難以查看問題。在 OpenTelemetry Collector中,可以將收到的 signals 給予相同的attributes,並且在 logs 上面增添對應 trace 的 trace id 和 span id,讓三種 signals 相輔相成,可以互相對照參考。
由於現有用來收集 logs 的函式庫過於龐大,每個程式語言間的實作方法又各有差異,再加上許多函式庫已發展得相當完整,OpenTelemetry 抱持著不重複造輪子的精神,認為不是要創造一個新的工具,而是讓這些現有的 logs 格式能夠符合 OpenTelemetry 的標準格式。
為此,OpenTelemetry 的核心策略是透過 log appender 來串接現有的日誌函式庫與 OpenTelemetry 生態系統。
在實作方面,OpenTelemetry 引入了「log appender(橋樑)」概念,將現有日誌函式庫的日誌橋接到 OpenTelemetry Log SDK 和 LogRecordExporters。
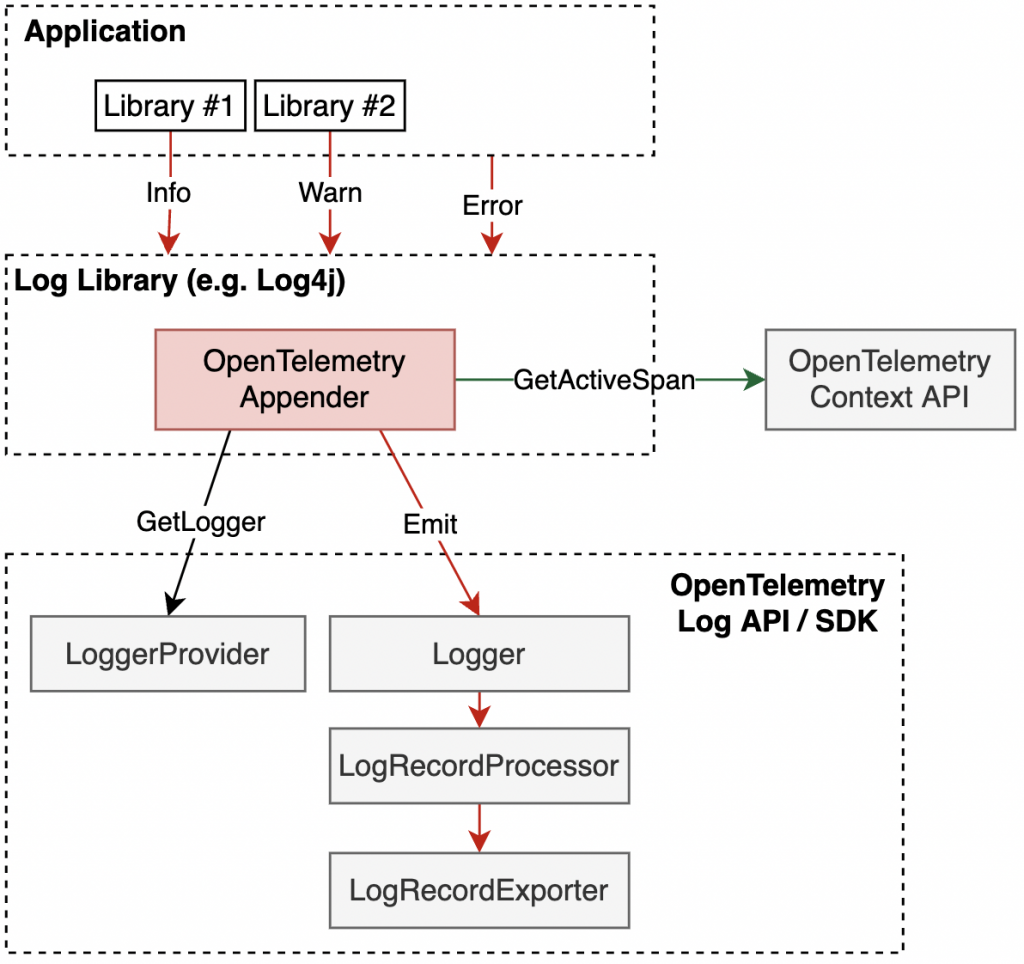
根據上圖,Log appender 的工作流程如下:
由於圖片中是針對 JAVA 的函式庫 Log4j 作為範例。像筆者公司主要使用 Python,它則是在 logging 函式庫中有支援 Appender,但在該函式庫裡則有別的名字稱作 Handler。
以 Python 為例,以下是一個完整的實作範例:
import logging
from opentelemetry import _logs
from opentelemetry.sdk._logs import LoggerProvider, LoggingHandler
from opentelemetry.sdk._logs.export import BatchLogRecordProcessor
from opentelemetry.exporter.otlp.proto.http._log_exporter import OTLPLogExporter
# 設定 OTLP exporter,發送到 OpenTelemetry Collector
exporter = OTLPLogExporter(endpoint="http://localhost:4318/v1/logs")
processor = BatchLogRecordProcessor(exporter)
# 建立 LoggerProvider 並配置 processor
logger_provider = LoggerProvider()
logger_provider.add_log_record_processor(processor)
_logs.set_logger_provider(logger_provider)
# 設定傳統的 Python logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
# 加入 OpenTelemetry LoggingHandler
logger.addHandler(LoggingHandler(logger_provider=logger_provider))
# 正常使用 Python logging,自動發送到 OpenTelemetry Collector
logger.info("Hello from OTLP!", extra={"user_id": "123", "action": "test"})
logger.error("This is an error log", extra={"error_code": "E001"})
print("Log was sent to Collector!")
透過這種方式,原本的 Python logging 程式碼幾乎不需要修改,只需要在初始化時加入 LoggingHandler,之後所有的日誌都會自動轉換成 OpenTelemetry LogRecord 格式並發送到 Collector。同時,extra 參數中的資料會自動對應到 LogRecord 的 Attributes 欄位。
總之,這種方法讓 OpenTelemetry 能夠讀取現有系統和應用程式的日誌,為新開發的應用程式提供發出豐富、結構化、符合 OpenTelemetry 規範的日誌的方式,並確保所有日誌最終都根據統一的日誌資料模型進行表示。
OpenTelemetry 的 Log Data Model 是整個日誌處理架構的核心。它定義了一個標準化的 LogRecord 結構,確保所有日誌資料都能以一致的方式被記錄、傳輸、儲存和解釋。
OpenTelemetry Log Data Model 的設計是為了滿足以下核心需求:
無損轉換能力:現有的日誌格式能夠明確地對應到這個資料模型,從任意日誌格式轉換到此模型,再轉換回去,應該能得到相同的資料
語義保持性:從其他日誌格式映射到此模型時必須保持語義意義,不能丟失原有日誌格式中特定元素的語義
跨格式轉換品質:從日誌格式 A 轉換到此模型,再轉換到日誌格式 B,結果應該與直接從 A 轉換到 B 一樣好
高效率實作:在需要儲存或傳輸的具體實作中能夠高效地表示此模型,主要考慮 CPU 序列化/反序列化使用率和序列化後的空間需求
這個資料模型目標是要成功表示三種不同類型的日誌和事件:
基於這些設計原則,LogRecord 包含了以下主要欄位:
這種設計讓不同來源的日誌都能被統一處理,同時保持足夠的彈性來容納各種日誌格式的特殊需求。為了能做到日誌的關聯性,OpenTelemetry 也做了相對應的設計,就是 log correlation。
正如前面提到的,OpenTelemetry 的一個重要概念是日誌關聯性 (Log Correlation)。透過在 log 記錄中加入 trace ID 和 span ID,可以將日誌與對應的 traces 和 metrics 關聯起來。這樣當系統發生問題時,開發者除了可以透過 logs 來查找問題以外,也能透過 trace ID 找到對應的 trace,了解請求的完整流程,也可以查看相關的 metrics去了解系統當時的整體狀態。
以上的流程正是符合了 observability 2.0 的精神,可以透過不同的 signal、不同的角度去了解系統的狀況。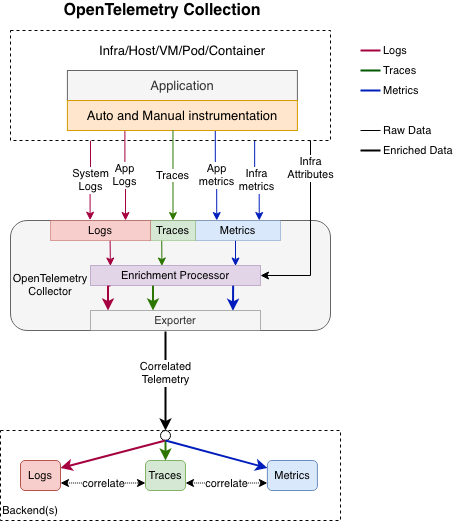
為了實現 log correlation,我們需要將當前的 trace context 注入到 logs 中,這時候,前面提到的 OpenTelemetry Appender 這個元件就又派上用場了!OpenTelemetry 支援兩種方式來注入 trace context 到 logs 當中:
透過這些機制,日誌中就會包含對應的 TraceId 和 SpanId,讓 logs 能夠與 traces 和 metrics 進行關聯。但是,實際機制仍舊取決於每個語言與特定的函式庫,這是因為每種語言處理 context 的方式本就不盡相同。
不過,並不是所有 logs 都應該攜帶 trace id,例如系統層級的 logs 就不需要。因此,在設計哪些 logs 應該攜帶 trace id 時,還是應該以應用程式的 logs 為主。
今天學習了 OpenTelemetry 在設計 logs API 上遇到的挑戰與設計考量,並了解 OpenTelemetry logs API 是如何與現代的日誌函式庫進行串接。
目前 OTel 的 Logs API 並沒有像 Metrics 和 Traces 那麼成熟,多數語言的實作還在演進中(例如 Python 就還在 development 階段)。因此在實務落地時,需要採取階段性的策略。
以短期計劃來看,應用程式可以繼續使用現有的日誌函式庫(如 Log4j、Python logging),再加裝 OpenTelemetry appender/handler 來注入 trace context,實現 log correlation,最後由Collector 負責收集這些已包含 trace 資訊的日誌,並轉換成 OTel Logs Data Model。
需要注意的是,如果單純讓 Collector 收集原生日誌(沒有 appender),這些日誌將無法包含 trace ID,也就無法實現完整的 log correlation。因此,即使在 Collector 為主的階段,應用程式仍需要透過 appender 機制來確保日誌包含必要的 trace 資訊。
OpenTelemetry Docs - Logs Data Model
OpenTelemetry Docs - OpenTelemetry Logging
OpenTelemetry Python SDK - opentelemetry.sdk._logs package
OpenTelemetry Docs - Supplementary Guidelines

 iThome鐵人賽
iThome鐵人賽