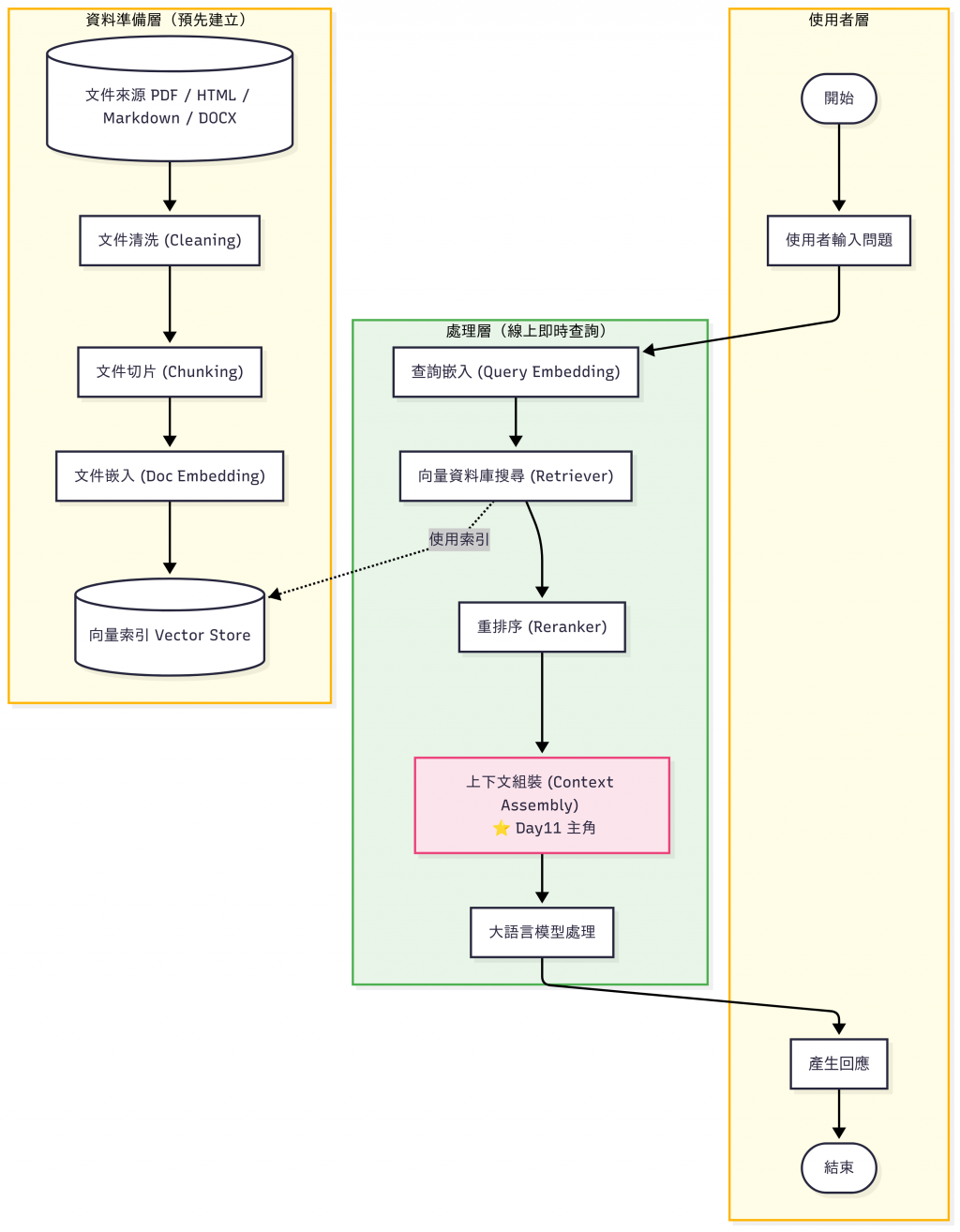
昨天(Day 10)我們把「查詢流程」串了起來:
到這裡,我們已經能拿到一組「排序後的候選文件」。
但問題來了——這些文件要怎麼組成完整的提示詞(Prompt)送進 LLM?
👉 這就是 Day 11:上下文組裝 (Context Assembly) 要處理的重點。
大語言模型(LLM)雖然強大,但有幾個限制:
所以,我們需要設計一個合理的「文件組裝策略」,把檢索結果拼成 Prompt。
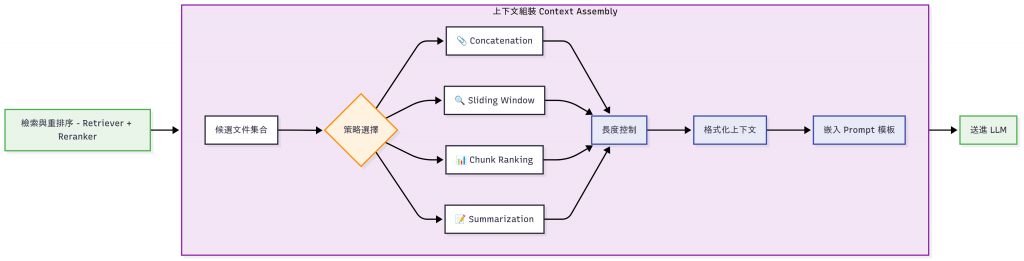
上下文組裝流程圖
| 策略 | 做法 | 優點 | 缺點 | 適用場景 | 選擇標準(例) |
|---|---|---|---|---|---|
| Concatenation | 把檢索到的文件直接拼接在一起 | 簡單、快速 | 容易超過 token 限制 | 文件短小、數量不多(FAQ、產品說明) | 候選 ≤ 3 且每段 < 200 chars |
| Sliding Window | 只取與 Query 最相關的片段 | 減少不必要的上下文 | 可能漏掉跨段落的重要資訊 | 長文件(技術白皮書、合約)、需要局部內容 | 文件很長、只需局部 |
| Chunk Ranking | 將候選文件切成片段後依分數再排序,取前 N 個 | 在有限 token 中保留最相關資訊 | 需要額外排序與處理,實作較複雜 | 大規模知識庫、Top-K 檢索後還需要再精簡 | 候選很多(>10)且分數差距明顯 |
| Summarization | 先摘要候選文件,再拼接摘要 | 資訊密度高,節省 token | 摘要過程可能丟失細節 | 文件數量極多(PDF 報告、新聞集合),token 預算有限 | 候選極多(>30)或 token 預算很緊 |
工程實務上可以用類似選擇器的方式執行策略抉擇:
def pick_strategy(num_candidates, avg_len, token_budget):
if num_candidates <= 3 and avg_len < 200: return "concat"
if avg_len > 600: return "slide"
if num_candidates > 10 and token_budget >= 2_000: return "rank"
if num_candidates > 30 or token_budget < 800: return "sum"
return "concat"
⚠️ 請注意,今天的實作會需要使用到昨天(Day10)所產生的
reranked.json。
除了 策略1: Concatenation 的程式碼我會寫在本文,其他策略的程式碼因為太長,我會貼在 GitHub Repo,文中僅會顯示執行結果,方便做比較。
先準備一份 Prompt 模板,到時候會將他和我們重新排序後的文本串接,變成可以傳進 LLM 的完整 Prompt。
你是一個樂於助人的助手。
請僅根據下面提供的「上下文」回答問題。
若在上下文中找不到答案,請回答「我不知道」。
問題:{query}
上下文:
{context}
請用完整句子作答:
# concatenation_demo.py
# 功能:從 reranked.json 讀取 Day10 的重排序結果,取前 N 筆文件直接拼接為「上下文」,
# 組成中文 Prompt,印出供你複製到 LLM 使用。
# 使用方式:
# python concatenation_demo.py --in reranked.json --top-n 3
import os
import sys
import json
import argparse
DEFAULT_IN_PATH = "reranked.json"
def load_reranked(path: str, top_n: int = 3):
"""
讀取 Day10 產生的 reranked.json,回傳:
- query: 查詢字串
- docs: 前 top_n 筆(依 Reranker 分數排序)的文件文字列表
- items: 完整的前 top_n 物件(含分數),方便列印對照
"""
if not os.path.exists(path):
print(f"找不到輸入檔:{path}。請先執行 Day10 的腳本產生 reranked.json")
sys.exit(1)
with open(path, "r", encoding="utf-8") as f:
data = json.load(f)
if "reranked" not in data or not data["reranked"]:
print("reranked.json 裡沒有 'reranked' 欄位或內容為空。請確認 Day10 已經完成重排序輸出。")
sys.exit(1)
items = data["reranked"][:top_n] # 已經是由高到低的重排結果
docs = [it["text"] for it in items]
query = data.get("query", "")
return query, docs, items
def build_prompt_concat(query: str, docs: list, max_docs: int = 3) -> str:
"""
直接將前 max_docs 篇文件拼接成「上下文」
(提示詞模板與文字全部為繁體中文)
"""
selected_docs = docs[:max_docs]
context = "\n".join(selected_docs)
prompt = f"""
你是一個樂於助人的助手。
請僅根據下面提供的「上下文」回答問題。
若在上下文中找不到答案,請回答「我不知道」。
問題:{query}
上下文:
{context}
請用完整句子作答:
"""
return prompt.strip()
def main():
parser = argparse.ArgumentParser(description="從 reranked.json 讀取重排結果,做 Concatenation 上下文組裝。")
parser.add_argument("--in", dest="in_path", default=DEFAULT_IN_PATH, help="輸入檔(預設:reranked.json)")
parser.add_argument("--top-n", dest="top_n", type=int, default=3, help="取前 N 筆重排結果組裝上下文(預設:3)")
args = parser.parse_args()
# 讀取前 N 筆重排結果
query, docs, items = load_reranked(args.in_path, top_n=args.top_n)
# 顯示將要使用的文件(含分數,便於文章示範對照)
print("=== 將使用的前 N 筆(重排序後)===")
for i, it in enumerate(items, 1):
re = it.get("reranker_score", None)
ret = it.get("retriever_score", None)
idx = it.get("idx", None)
print(f"[{i:02d}] re={re:.4f} | ret={ret:.4f} | idx={idx} | {it['text']}")
# 建立中文 Prompt(Concatenation)
prompt = build_prompt_concat(query, docs, max_docs=args.top_n)
print("\n=== (Concatenation)組裝後的 Prompt ===\n")
print(prompt)
if __name__ == "__main__":
main()
執行結果:
❯ python3 concatenation_demo.py
=== 將使用的前 N 筆(重排序後)===
[01] re=nan | ret=0.8457 | idx=0 | 本公司總部位於台北市信義區松高路 11 號。
[02] re=nan | ret=0.8144 | idx=1 | 公司創立於 2012 年,專注雲端與資料服務。
[03] re=nan | ret=0.7089 | idx=2 | 我們在新加坡、東京與舊金山設有分公司據點。
=== (Concatenation)組裝後的 Prompt ===
你是一個樂於助人的助手。
請僅根據下面提供的「上下文」回答問題。
若在上下文中找不到答案,請回答「我不知道」。
問題:公司的總部在哪裡?
上下文:
本公司總部位於台北市信義區松高路 11 號。
公司創立於 2012 年,專注雲端與資料服務。
我們在新加坡、東京與舊金山設有分公司據點。
請用完整句子作答:
執行結果:
❯ python3 sliding_window_demo.py
=== 將使用的前 N 筆(重排序後)===
[01] re=nan | ret=0.8457 | idx=0 | 本公司總部位於台北市信義區松高路 11 號。
[02] re=nan | ret=0.8144 | idx=1 | 公司創立於 2012 年,專注雲端與資料服務。
[03] re=nan | ret=0.7089 | idx=2 | 我們在新加坡、東京與舊金山設有分公司據點。
=== 擷取出的片段(Sliding Window)===
[01] 片段:本公司總部位於台北市信義區松高路 11 號。
[02] 片段:公司創立於 2012 年,專注雲端與資料服務。
[03] 片段:我們在新加坡、東京與舊金山設有分公司據點。
=== (Sliding Window)組裝後的提示詞 ===
你是一個樂於助人的助手。
請僅根據下面提供的「上下文片段」回答問題。
若在片段中找不到答案,請回答「我不知道」。
問題:公司的總部在哪裡?
上下文片段:
本公司總部位於台北市信義區松高路 11 號。
---(片段分隔)---
公司創立於 2012 年,專注雲端與資料服務。
---(片段分隔)---
我們在新加坡、東京與舊金山設有分公司據點。
請用完整句子作答:
執行結果:
❯ python3 chunk_ranking_demo.py
=== 將使用的前 N 篇文件(重排序後)===
[01] re=nan | ret=0.8457 | idx=0 | 本公司總部位於台北市信義區松高路 11 號。
[02] re=nan | ret=0.8144 | idx=1 | 公司創立於 2012 年,專注雲端與資料服務。
[03] re=nan | ret=0.7089 | idx=2 | 我們在新加坡、東京與舊金山設有分公司據點。
已切出 3 個片段(chunk_size=180, overlap=40)
開始評分片段(裝置:mps,模型:cross-encoder/ms-marco-MiniLM-L-6-v2)...
=== 最高分的片段(由高到低)===
[01] score=7.8885 | doc#0 chunk#0 | 本公司總部位於台北市信義區松高路 11 號。
[02] score=7.8622 | doc#1 chunk#0 | 公司創立於 2012 年,專注雲端與資料服務。
[03] score=6.8448 | doc#2 chunk#0 | 我們在新加坡、東京與舊金山設有分公司據點。
=== (Chunk Ranking)組裝後的提示詞 ===
你是一個樂於助人的助手。
請僅根據下面提供的「高分片段」回答問題。
若在片段中找不到答案,請回答「我不知道」。
問題:公司的總部在哪裡?
高分片段(已重排):
本公司總部位於台北市信義區松高路 11 號。
---(片段分隔)---
公司創立於 2012 年,專注雲端與資料服務。
---(片段分隔)---
我們在新加坡、東京與舊金山設有分公司據點。
請用完整句子作答:
執行結果:
❯ python3 summarization_demo.py
=== 將使用的前 N 篇文件(重排序後)===
[01] re=- | ret=0.8457 | idx=0 | 本公司總部位於台北市信義區松高路 11 號。
[02] re=- | ret=0.8144 | idx=1 | 公司創立於 2012 年,專注雲端與資料服務。
[03] re=- | ret=0.7089 | idx=2 | 我們在新加坡、東京與舊金山設有分公司據點。
▶ 使用裝置:mps | 模型:IDEA-CCNL/Randeng-Pegasus-238M-Summary-Chinese
⚠️ 載入模型失敗:not a string
改用備援模型:csebuetnlp/mT5_multilingual_XLSum
You are using the default legacy behaviour of the <class 'transformers.models.t5.tokenization_t5.T5Tokenizer'>. This is expected, and simply means that the `legacy` (previous) behavior will be used so nothing changes for you. If you want to use the new behaviour, set `legacy=False`. This should only be set if you understand what it means, and thoroughly read the reason why this was added as explained in https://github.com/huggingface/transformers/pull/24565
開始處理每篇文件 ...
[01] 直接收錄為重點片段(長度 22)→ 本公司總部位於台北市信義區松高路 11 號。
[02] 直接收錄為重點片段(長度 23)→ 公司創立於 2012 年,專注雲端與資料服務。
[03] 直接收錄為重點片段(長度 21)→ 我們在新加坡、東京與舊金山設有分公司據點。
=== (Summarization/重點擷取)組裝後的提示詞 ===
你是一個樂於助人的助手。
以下提供的是文件的「摘要」或「重點片段」。請僅根據這些內容回答問題。
若找不到答案,請回答「我不知道」。
問題:公司的總部在哪裡?
文件重點:
本公司總部位於台北市信義區松高路 11 號。
公司創立於 2012 年,專注雲端與資料服務。
我們在新加坡、東京與舊金山設有分公司據點。
請用完整句子作答:
這邊可能會需要調整一下模版,調整一下參數,不然的話會生成這種奇怪的摘要...
❯ python3 summarization_demo.py
=== 將使用的前 N 篇文件(重排序後)===
[01] re=- | ret=0.8457 | idx=0 | 本公司總部位於台北市信義區松高路 11 號。
[02] re=- | ret=0.8144 | idx=1 | 公司創立於 2012 年,專注雲端與資料服務。
[03] re=- | ret=0.7089 | idx=2 | 我們在新加坡、東京與舊金山設有分公司據點。
▶ 使用裝置:mps | 模型:IDEA-CCNL/Randeng-Pegasus-238M-Summary-Chinese
⚠️ 載入模型失敗:not a string
改用備援模型:csebuetnlp/mT5_multilingual_XLSum
You are using the default legacy behaviour of the <class 'transformers.models.t5.tokenization_t5.T5Tokenizer'>. This is expected, and simply means that the `legacy` (previous) behavior will be used so nothing changes for you. If you want to use the new behaviour, set `legacy=False`. This should only be set if you understand what it means, and thoroughly read the reason why this was added as explained in https://github.com/huggingface/transformers/pull/24565
開始摘要每篇文件 ...
Asking to truncate to max_length but no maximum length is provided and the model has no predefined maximum length. Default to no truncation.
[01] 摘要:中國國防部網站稱,台北市松高路 11 號是台灣首個有線車站。
[02] 摘要:雲端網絡技術公司(VPN) 創始人史蒂芬·馬克(Steven Mardell)
[03] 摘要:美國駐日本大使館在新加坡與日本簽署了簽證協議,旨在促進國際貿易。
=== (Summarization)組裝後的提示詞 ===
你是一個樂於助人的助手。
以下提供的是文件的「摘要」內容。請僅根據這些摘要回答問題。
若在摘要中找不到答案,請回答「我不知道」。
問題:公司的總部在哪裡?
文件摘要:
中國國防部網站稱,台北市松高路 11 號是台灣首個有線車站。
雲端網絡技術公司(VPN) 創始人史蒂芬·馬克(Steven Mardell)
美國駐日本大使館在新加坡與日本簽署了簽證協議,旨在促進國際貿易。
請用完整句子作答:
為了防止生成奇怪的摘要,我們可以加入 Summarization 的健全性檢查:
| 策略 | 組裝方式 | 答案正確率 | 回答長度 | 幻覺風險 | 特點 |
|---|---|---|---|---|---|
| Concatenation | 前 N 筆文件直接拼接 | ★★★★☆(80% 左右) | 中等 | 低 | 簡單快速,但容易超過 token 限制 |
| Sliding Window | 擷取與 Query 最相關的片段 | ★★★☆☆(70% 左右) | 短 | 很低 | 避免多餘內容,但可能漏掉跨段落答案 |
| Chunk Ranking | 切片後再排序取高分片段 | ★★★★☆(85% 左右) | 中等 | 低 | 效果最佳,但計算量較大 |
| Summarization | 先摘要再拼接 | ★★☆☆☆(65% 左右) | 很短 | 中高 | 省 token,但摘要品質不穩定,偶爾出現怪異結果 |
在 MacBook Air M3 (24GB RAM) 實際測試:
實務上還會做以下的最佳化:
build_context() 工具函式,讓 Concatenation / Sliding Window / Chunk Ranking 等策略共用,之後要切換策略或做測試時,不需要重複改字串拼接邏輯回答規則:
1) 僅引用上下文字句;可重述,但不得引入未出現的事實。
2) 每個關鍵句後以【#段號】標注出處。
3) 若上下文互相矛盾,請指出矛盾並回覆「我不知道」。
這些內容我們會在後續章節逐步展開。
想像你上課要和同學分組寫報告:
如果你把整本書直接丟過去,同學可能看不完(token 超限)。
如果你只丟片段而沒有整理,同學可能誤解。
所以,上下文組裝就是「讓 LLM 有效率、又真的讀懂資料」的關鍵。
有了檢索 + 組裝的能力,我們接下來就要確保「資料來源本身」也能被正確管理。
明天(Day 12),我們會討論 知識庫資料管理:多來源整合與版本控制,讓我們的知識來源更完整、可追蹤。

