在前面幾天的學習中,我們已經用 Keras 實作過基本的分類模型,
像是使用全連接層(Dense layer)來處理圖片資料。
然而,這種方式往往效果有限。原因在於圖片本身的特性:
它是一個二維結構,每個像素與周圍像素之間有著緊密的關聯。
如果直接把圖片「攤平成一維向量」,這些結構資訊就會被破壞,
模型就無法充分掌握圖像中的空間關係。
因此,我們就要使用別的工具來處理這種情形,也就是我們今天要介紹的 -
卷積神經網路(Convolutional Neural Network, CNN),就是專門為了處理這個問題而誕生的。
在今天的學習中,我們就要來介紹「CNN」這個工具,
他不是電視台,更不是公司,而是可以讓我們處理訊息的好東西。
卷積神經網路是一種特化的神經網路架構,
最適合處理具有「空間結構」的資料,例如像是圖片。
不同於傳統的全連接層將所有像素「一視同仁」,
CNN 強調 局部區域 的重要性,
並且利用「卷積濾鏡」(filters)去學習圖片中的特徵。
當你看一張照片時,你的眼睛不會同時處理每一個像素,
而是先注意到一些明顯的邊界或形狀,再慢慢拼湊成完整的物體。
而 CNN 的運作邏輯就跟這個過程非常類似。
「卷積」其實就是兩個步驟組成的運算 : 「滑動 + 內積」,
利用 filter 在輸入圖片上滑動並且持續進行矩陣內積,
卷積後得到的圖片我們稱之為 「feature map」。
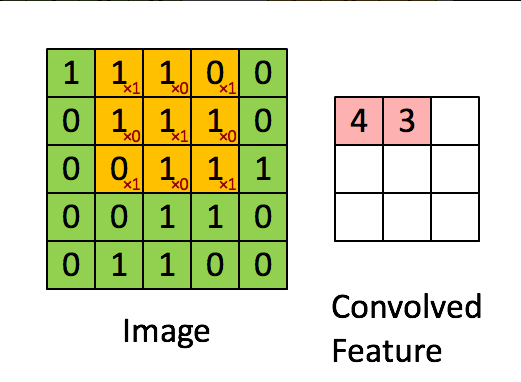
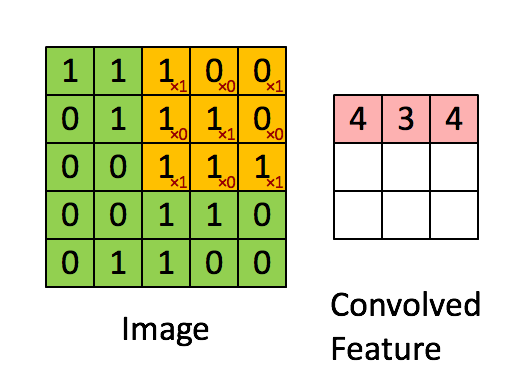
如上圖,你大概就可以知道他是怎麼運行的了,
就是將3X3的矩陣(右)在圖片上的像素一步一步移動,
在每個位置的時候,我們就會計算兩個矩陣相對元素的乘積並相加,
輸出一個值並放在一個矩陣(右邊粉色的矩陣),這就是基本的卷積運算。
在卷積中,我們一般會將概念分成三個部份來解,分別為:
-卷積層(Convolution Layer)
-池化層(Pooling / Subsampling)
-全連接層(Fully Connected, FC)
以下我們也以這三個為重心去探討:
在卷積神經網路裡,最重要的其實就是「卷積層」。
我們可以把卷積層想像成一個小小的觀察窗,也就是所謂的濾鏡或 kernel,
它會在圖片上不斷地滑動,對每個小區域做數學運算,
比如像是內積,在最後得到一張新的特徵圖。
而這張特徵圖的意義就是:模型在這裡「看到了什麼」。
例如,如果濾鏡設計得像一個邊緣偵測器,
那麼它就會在圖片中把邊緣的部分凸顯出來。
而在實務上,我們不只會用一個濾鏡,而是同時用許多不同的濾鏡,
每一個濾鏡都能抓住不同的特徵,於是輸出就會是多張特徵圖。
這也是為什麼在經過一層卷積後,圖片雖然平面大小縮小或保持,
但「深度」會變厚,因為多了許多不同的特徵層。
對彩色圖片來說,事情會再複雜一些。因為彩色圖片有紅、綠、藍三個通道,
所以濾鏡本身也必須有三個對應的深度。
當濾鏡在圖片上滑動時,它會同時對三個通道做運算,再把結果加總,最後輸出一個數值。
這樣的設計確保了 CNN 不會只看到單一顏色,
而是能學習顏色之間的組合與關係。
不過,卷積還有一些細節需要注意。
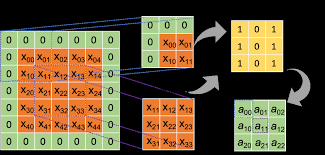
比如說,當濾鏡在圖片邊緣滑動時,常常會因為沒有足夠的像素而少掉一部分。
這時候我們就會在圖片邊界補上一圈零,這叫做 padding。(如下圖)
(圖片來源:
https://www.geeksforgeeks.org/machine-learning/cnn-introduction-to-padding/)
它的好處是能讓輸入與輸出的大小保持一致,避免圖片一路被縮小到消失。
另一個要素是 「stride」,也就是濾鏡每次滑動的步幅。
就像我們在前面介紹的一樣,他會在像素一步一步移動
如果步幅設為 1,那麼濾鏡會一格一格地移動;
但如果設為 2,就會每次跨兩格,這樣產生的特徵圖就會更小,等於進行了一次壓縮,
最後會輸出一個值並放在一個矩陣,完成我們所需的要求。
在卷積層之後,常見的設計就是接上一個池化層。
池化的作用很像是幫圖片「總結」資訊。
舉例來說,最大池化就是從一個小區塊裡挑出數值最大的那個,保留最突出的特徵;
而平均池化則是算出區塊的平均值。
無論是哪一種方法,目的都是在縮小圖片的同時保留重要的資訊。
這樣做除了能減少運算量,還有一個隱藏的優點:讓模型對於輸入的變化更有彈性。
比方說,如果圖片裡的物體稍微平移了一點點,
經過池化後特徵圖的變化不會太大,模型就能更穩定地辨認它。
而當經過多層卷積與池化後,圖片中的細節已經被轉換成一組抽象的特徵表示。
這時候,網路就會接上一個全連接層,負責把這些特徵整合起來,並輸出最後的分類結果。
跟我們前面有做過的手寫Mnist有點類似,可以把他想成一種「分類帽」
全連接層就像是做「總結」的角色,把前面不同濾鏡所看到的線條、顏色、形狀等資訊,
整合成「這張圖片到底是貓還是狗」的最終答案。
卷積神經網路(CNN)最早在影像處理領域展現出強大的能力,
它能自動從圖片中學習特徵,這讓電腦能夠「看懂」畫面,而不需要人工手動設計特徵。
最常見的應用就是影像分類,例如輸入一張照片,
模型可以判斷這是一隻貓還是一隻狗,這也是我們在深度學習時最常被拿來當作範例解釋的例題。
而隨著技術成熟,CNN 也被廣泛應用在更複雜的影像任務中,例如物件偵測,
它不只是回答「這是什麼」,還能指出物體在圖片裡的位置;
抑或是語意分割,把圖片切割成像素等級的區塊,讓電腦清楚分辨出天空、道路、行人等細節。
在下面我也舉幾個目前常見的生活化例子,說不定也是你生活中常使用的操作:
在你上傳照片到 Facebook 的時候,它常常會自動幫你框出照片中的人臉,
甚至提示你可能是誰。這背後就是 CNN 在發揮作用。
模型先學會辨認人臉的特徵,例如眼睛、鼻子和嘴巴的位置,
進而建立每個人的獨特「臉部特徵向量」。當你上傳照片時,系統會比對這些向量,
就能快速找出相似的臉,達到自動標記的效果。
Google 相簿(Google Photos)能自動幫你把照片分類,
例如「海灘」、「狗」、「食物」等。CNN 在這裡的角色就是影像分類器。
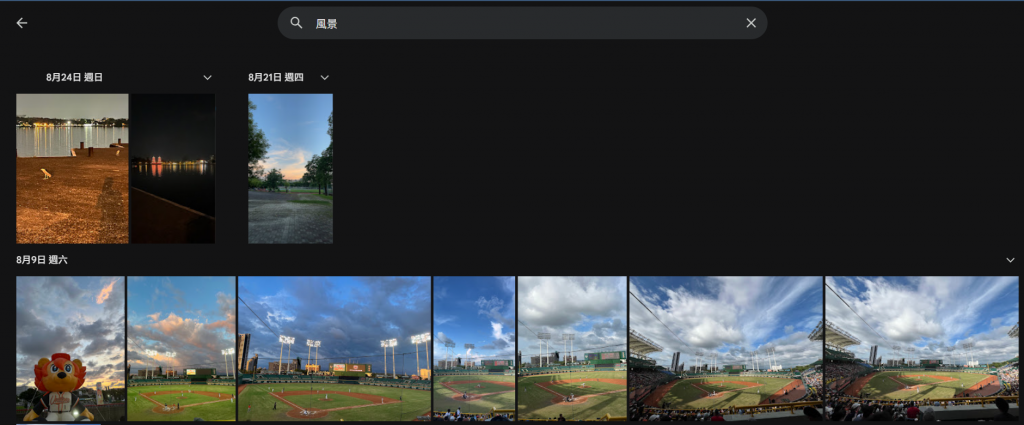
例如我在我手機的 google 相簿中搜尋「風景」,
他就會辨識出哪些符合我的搜索條件,並展示出那些圖片,
如此就可以大大提升我找照片的效率,
當哪天我突然想發照片假裝我在出去玩而不是在這邊打文章,
我就可以很快地抓出我想要圖片了。
特斯拉和 Google 的自駕車技術裡,CNN 是感知系統的核心。
它需要從攝影機捕捉的即時影像裡,辨識出車道線、行人、紅綠燈和其他車輛。
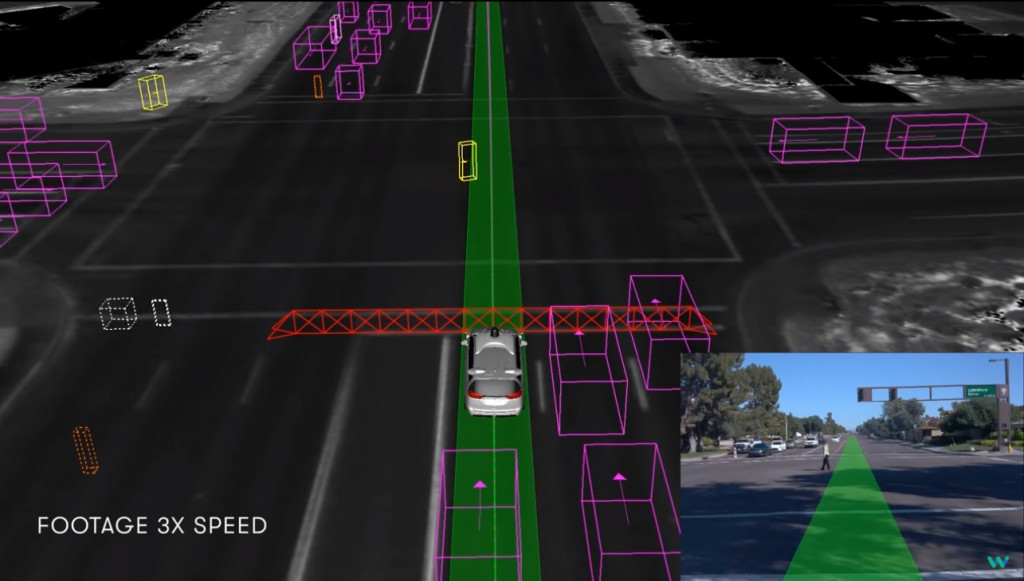
(圖片來源:https://technews.tw/2019/03/06/waymo-self-driving-car-navigates-a-police-controlled-intersection/)
CNN 的卷積層會學習到不同層次的特徵,像是邊緣(用來辨識車道線)、
形狀(用來辨識交通號誌)、甚至物件類別(判斷前方是不是一台車)。
以上就是今天的學習內容了,接下來也會帶到CNN的簡易實作,
大家敬請期待!
https://hackmd.io/@allen108108/rkn-oVGA4

