
很快地第二週的學習即將告一段落!到今天為止,我們學習到 OpenTelemetry 解決了哪些可觀測性的痛點,了解了它的元件是如何各司其職,專門來生成、收集、匯出我們的遙測資料。最後,我們透過 OpenTelemetry spectification 來了解四大 signal 的 data model,去了解這些資料是如何被生成、運用在哪裡,以及各自所包含的資訊有哪些。
之前說過,OpenTelemetry 不負責資料的儲存,因此要如何選擇適合團隊需求的資料儲存後端,也是我們需要思考的問題。遵循 Observability 2.0 的精神,本篇文章會著重在要如何做到資料的 singal source of truth,因此常見的資料儲存後端如 Prometheus, Jaeger, ELK 等專精於某項 signal 儲存的工具,將不會在此系列文中介紹。
透過 OpenTelemetry,我們做到在同一個地方進行資料的收集,在生成與匯出的部分,也遵循一套統一的規範;而為了讓資料能在同一地方儲存、使用單一個查詢引擎做資料查詢,Data Lakehouse 的概念就進入到我們的視野。筆者先前並沒有聽過這個名詞,倒是聽過 Data Warehouse 與 Data Lake,所以今天,讓我們來看看 data lakehouse 可以協助我們解決什麼樣的問題。
Data Lakehouse 從名字便可拆解它結合了 Data Warehouse 以及 Data Lake 的特性。在 Data Lakehouse 的概念還沒出現以前,Data Lake 用來存放大型的原始資料,而 Data WareHouse 則用來存放有條理的結構化資料集。
但是,這樣的做法讓我們必須維護兩套獨立的架構,並且團隊必須維護從 Data Lake 到 Data Warehouse 之間複雜的 ETL Pipeline,兩邊存取重複資料的設計也導致成本提高,同時也附帶了資料一致性以及何時要更新同步資料等議題。
Data Lakehouse 除了能讓我們維護一套系統、一份資料即可外,同時它也旨在打破資料孤島,確保資料的彈性與靈活性——講到這裡,大家會發現這同時也是 Observability 2.0 所要傳達的精神之一。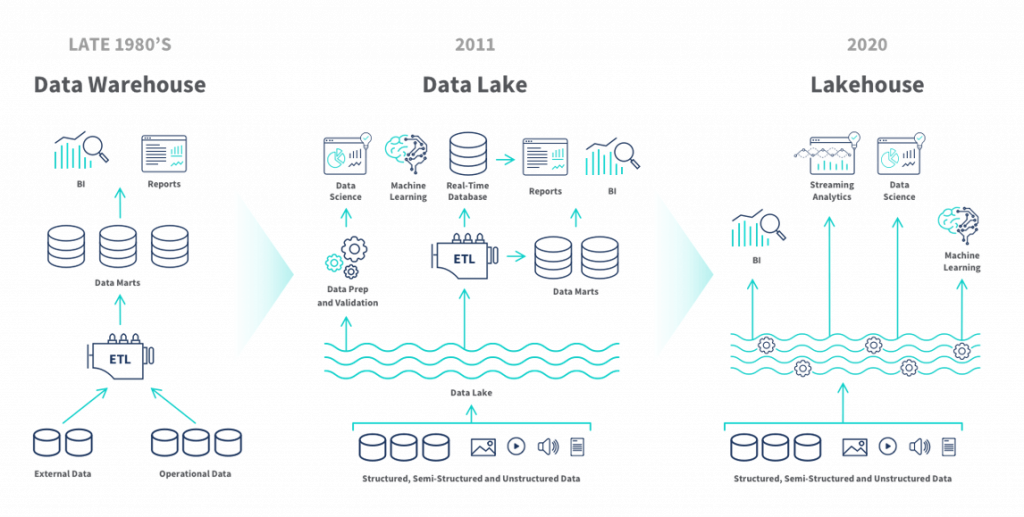
Data Warehouse 到 Lakehouse 的演變。Lakehouse讓我們不必維護兩套獨立架構,可以直接從中取得具有商業價值的資料
Data Lakehouse 的概念最早由 Databricks 在其論文「Delta Lake: High-Performance ACID Table Storage over Cloud Object Stores」中正式提出。Delta Lake 是 Databricks 開源的一個儲存層(storage layer),專門為 Data Lakehouse 架構而設計,它在物件儲存(如 S3)之上提供了類似資料庫的 ACID 事務保證。
目前市面上有多個 Data Lakehouse 的實作方案,包括 Delta Lake、Apache Iceberg、Apache Hudi 等。
以 Delta Lake,也就是這篇論文為例,它透過以下技術特性來解決傳統 Data Lake 的問題:
傳統 Data Lake 最大的問題是缺乏事務性保證,容易出現資料不一致的情況。想像一個情境:當 OpenTelemetry Collector 正在批次寫入大量 traces 資料到 Data Lake 時,突然發生網路中斷或系統故障,可能會導致:
Data Lakehouse 則能夠解決:
原子性(Atomicity):整批 traces 要嘛全部寫入成功,要嘛全部回滾。不會出現「半吊子」的資料狀態,確保每個完整的 trace 都能被正確儲存。
一致性(Consistency):即使在高併發寫入的情況下,資料庫的結構約束(schema)依然會被遵守。比如 trace_id 必須是唯一的,timestamp 必須是有效的時間格式。
隔離性(Isolation):多個 OpenTelemetry Collector 實例同時寫入資料時,彼此不會互相干擾。
持久性(Durability):一旦寫入操作確認完成,即使發生硬體故障,資料也不會丟失,這對於用來排查故障的可觀測性來說尤其重要。
在維護可觀測性系統時,我們經常會遇到這樣的情況:應用程式更新了,開始記錄新的 attributes;或者團隊決定調整 metrics 的 labels 命名。在傳統的 Data Lake 中,這些變更往往會造成麻煩。
假設你的應用程式原本記錄的 HTTP requests traces 只有 method、status_code 這兩個 attributes,後來產品團隊希望加入 user_type 來分析不同用戶群體的行為。在傳統系統中,你可能需要:
Data Lakehouse 的 Schema Evolution 讓這個過程變得簡單許多。它可以自動處理新增欄位的情況,舊的查詢依然可以正常執行,新的查詢則可以使用新增的欄位。更重要的是,即使欄位名稱發生變更(比如把 user_type 改成 user_category),系統也能透過欄位 ID 而非名稱來識別,避免查詢中斷。
Time Travel 功能乍看之下好像只是時間範圍查詢,Prometheus 也能做到類似的事情。但 Data Lakehouse 的 Time Travel 有個關鍵差異:它記錄的是資料表的歷史快照,包含當時的 schema 結構,而不只是時間點的資料值。
假設團隊在週五調整了 OpenTelemetry 的設定,修改了某些 metrics 的計算邏輯(比如把 response time 從毫秒改成秒),但忘了同步更新 dashboard 的顯示單位。週一你發現所有圖表都顯示錯誤。
若我們今天使用的是 Prometheus,那我們只能知道週五以前的資料在正常範圍,而週一記錄的資料都比之前觀察的資料高了一千倍。
但若我們使用的是 Data Lakehouse,就可以直接 time travel 到週五的資料表快照,檢查當時的 schema 定義和資料狀態,進一步確認 response time 的欄位和週一有何不同。
這樣我們能理解數據錯誤的真正原因是 schema 變更,而不是應用程式本身的效能問題。
另一個實用功能是資料回滾。如果你發現最近的資料處理邏輯有 bug,在 Prometheus 中你可能需要:
但在 Data Lakehouse 中,你可以利用其記錄的歷史狀態,直接將資料表恢復到正確的時間點:
-- 將資料表恢復到特定版本(實際改變資料表狀態)
RESTORE TABLE metrics TO VERSION AS OF 123;
-- 或恢復到特定時間點
RESTORE TABLE metrics TO TIMESTAMP AS OF '2024-01-20 14:00:00';
這種能力在處理複雜的多 signal 關聯分析時特別有用,因為你需要確保所有不同類型的資料(metrics, logs, traces)都使用相同的邏輯版本。
除了上述提到的schema evolution、time travel 與 ACID 等已可運用到可觀測性的場景,Data Lakehouse 還有一些特性正好可以解決 Observability 2.0 面臨的挑戰:
可觀測性資料往往具有大量的標籤和屬性(高維度),且每個屬性可能有很多不同的值(高基數)。傳統時間序列資料庫在面對這種資料特性時,查詢效能會急劇下降。
Data Lakehouse 透過欄式儲存和先進的索引技術(如 Z-ordering),可以高效處理這類資料:
-- 即使有大量維度的查詢也能保持高效能
SELECT service_name, avg(duration)
FROM traces
WHERE timestamp > now() - interval '1 hour'
AND http_status_code = 500
AND user_region IN ('us-east', 'us-west')
AND environment = 'production'
GROUP BY service_name
透過統一的表格格式(如 Delta Table),我們可以將 Metrics、Logs、Traces、Profiling 資料存放在同一個系統中,使用相同的 SQL 查詢語言進行關聯分析:
-- 關聯不同 signal 的資料進行根因分析
WITH error_traces AS (
SELECT trace_id, service_name, timestamp
FROM traces
WHERE status = 'ERROR'
AND timestamp > now() - interval '5 minutes'
),
related_logs AS (
SELECT trace_id, message, level
FROM logs
WHERE trace_id IN (SELECT trace_id FROM error_traces)
)
SELECT et.service_name, rl.message, count(*)
FROM error_traces et
JOIN related_logs rl ON et.trace_id = rl.trace_id
GROUP BY et.service_name, rl.message
回到最初的問題:OpenTelemetry 幫我們收集了四大 signal 的遙測資料,但這些資料要存在哪裡?
傳統做法是為每種 signal 選擇專門的儲存系統,但這會造成資料孤島,當故障發生時,我們得在不同工具間跳來跳去,拼湊出完整的問題全貌。此外,這些工具往往各有不同的查詢語言和操作介面,大幅增加了團隊在問題排查的複雜度。
當下次系統出現異常時,我們就不再需要到各個操作界面拼湊出散落在各個儲存後端的遙測資料,而是可以在同一個查詢中,直接關聯這些資料,快速定位問題根因。這正是 Observability 2.0 所追求的 single source of truth 的具體實現。
下一篇文章,我們將以 Apache Iceberg 為例,深入探討 Data Lakehouse 的實際技術實現,包含如何在可觀測性場景中應用這些技術。
METAAGE - MinIO 與 Data Lakehouse:現代資料架構的關鍵角色
Qlik - What is a Data Lakehouse?
