目前已經有許多發展成熟的 Data Lakehouse 解決方案,例如 Apache Hudi、Apache Iceberg、Delta Lake 等。它們都是一種開放資料表格式(Open Table Format)。也就是說,Data Lakehouse 並不是重新發明輪子,而是在現有的 Data Lake 上建立類似 Data Warehouse 的資料表,讓原本只有儲存功能的 Data Lake 具備了管理資料的能力。
在眾多的解決方案中,本文選擇以 Apache Iceberg 為例進行深入探討。Iceberg 憑藉著最大的工具生態系統脫穎而出,無論是讀取、寫入,還是管理 Iceberg 資料表都有豐富的工具支援。以下讓我們來看看 Apache Iceberg 主要的架構設計。
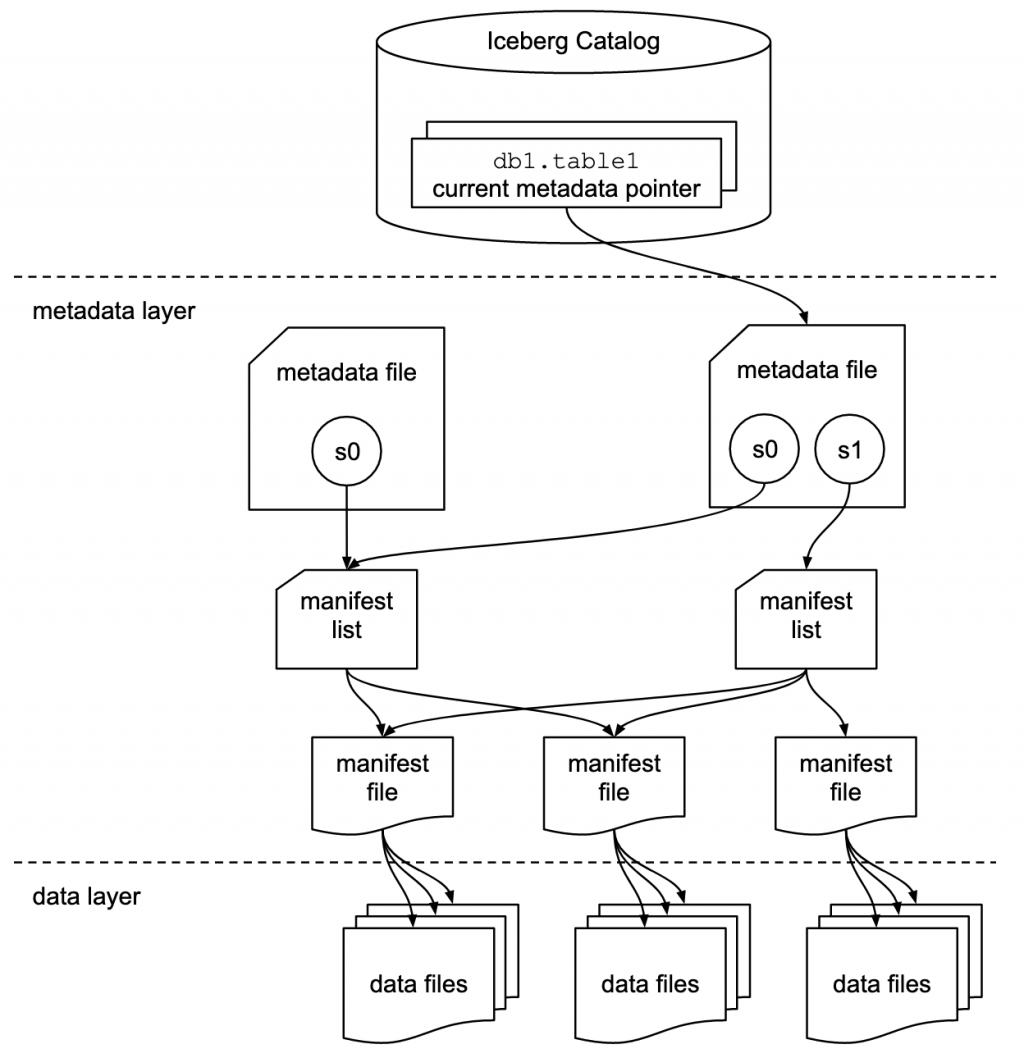
Iceberg 採用三層設計:Catalog、Metadata layer、Data layer。當我們在查詢資料時,這三層分工合作,把 Data Lake 抽象成一張可查詢的表格。
Catalog layer
管理 database 和 table 的定義,但 table 儲存的是指向 metadata 的指標,而非實際資料。
Metadata layer
儲存資料表的結構資訊、分區資訊,以及指向實際資料檔案的路徑。Iceberg 追蹤的是「個別檔案」而非目錄,這讓寫入操作可以直接生成檔案,並透過 atomic swap 進行原子性的 metadata 更新。
Data layer
裡面儲存實際的資料檔案,通常以 Parquet 格式儲存在物件儲存(如 S3)中
在 Iceberg 中,Metadata 層負責記錄 table 的狀態、檔案的資訊與分區資料,共有三個元件,分別記錄不同種的狀態資訊:
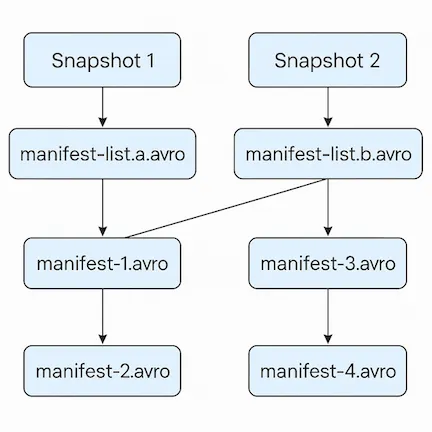
理解完 Iceberg 的核心架構後,可以看出它如何透過分層設計來提升讀取效能。除此之外,Iceberg 還有以下的效能優化設計:
Iceberg 的分區機制不同於傳統 Hive-style 目錄分區,它支援彈性的轉換函數:
-- 時間分區:按年、月、日、小時分區
PARTITIONED BY (year(timestamp), month(timestamp))
-- 截斷分區:將字串截斷到指定長度
PARTITIONED BY (truncate(user_id, 4))
-- 雜湊分區:將資料均勻分散
PARTITIONED BY (bucket(16, service_name))
查詢時不需要顯式指定分區欄位,Iceberg 會自動:
-- 查詢條件
WHERE timestamp > '2024-01-20 10:00:00'
AND service_name = 'user-api'
-- Iceberg 自動計算:
-- year(timestamp) = 2024, month(timestamp) = 1
-- bucket(16, 'user-api') = 8
-- 只讀取對應分區的檔案
透過上個章節提到的分層統計資訊,查詢引擎能在不讀取資料檔案的情況下完成大部分過濾:
假設我們想撈取特定的 metrics 資料:
SELECT service_name, avg(duration)
FROM metrics
WHERE timestamp > '2024-01-20 10:00:00'
AND status_code = 500
其查詢過程為:
Manifest files 可以在不同 snapshot 間重複使用:
Iceberg 透過在 data lake 上實作資料表,解決了 data lake 在資料管理上的困難。
根據 Apache Iceberg 規範,Schema 可以透過型別提升(type promotion)或新增、刪除、重新命名、重新排序欄位來進行 schema evolution。每次都會產生具有唯一 Schema ID 的新版本。
而在欄位層級,Iceberg 使用 Field ID 來追蹤欄位。每個欄位都有唯一的 Field ID,這個 ID 在 schema 演化過程中保持不變,讓系統能夠正確識別同一個欄位。
當讀取資料時,Iceberg 透過 Field ID 而非欄位名稱來選擇欄位。即使表格的欄位名稱和順序在資料檔案寫入後發生變化,系統也能正確讀取資料。
這種設計讓可觀測性資料的 schema 變更變得安全且向前/向後相容。
根據分層架構,Iceberg 也可以處理高併發寫入的情境:
同時,每個更新都會生成一個 snapshot,因此可以支援在上一篇文章提到的 time travel:
在支援 SQL time travel 的引擎裡(例如 Spark 3.3+),可以寫:
SELECT *
FROM prod.db.table
TIMESTAMP AS OF '1986-10-26 01:21:00';
Iceberg 會透過 snapshot-log 找到對應時間點的 snapshot,並使用該 snapshot 的 metadata 來讀取資料。若指定時間早於最早的 snapshot,系統會回報錯誤。
除了時序資料庫(如 Prometheus)和日誌儲存系統(如 Elastic Stack),Apache Iceberg 為可觀測性資料提供了另一種理想的儲存解決方案。透過它的開放架構、豐富的生態支援,以及 Hidden Partitioning、Schema Evolution 等功能,我們能夠建構既高效又靈活的可觀測性資料平台。
下一篇文章,我們將深入探討 Iceberg 底層使用的 Parquet 格式,了解欄式儲存如何實現高效的分析查詢。
2025 Guide to Architecting an Iceberg Lakehouse
Apache Iceberg - Iceberg Table Spec
Apache Iceberg - Schema Evolution
BennyXu - 《動不動就要 ETL? 以Trino為例-淺談從資料倉儲到湖倉》
R. Ganesh - Apache Hudi vs Delta Lake vs Apache Iceberg!

