接續昨天程式碼解說,話不多說,即刻開始。
(還沒閱讀過昨日文章者,可以先前往上一篇觀看)
train_datagen = ImageDataGenerator(
rotation_range=20,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest'
)
# 驗證集不使用資料增強
val_datagen = ImageDataGenerator()
train_datagen.fit(x_train)
在這段程式碼中,我們建立了「資料增強系統」,就像為訓練資料創造各種變化版本。
ImageDataGenerator 是 Keras 提供的資料增強工具,
我們設定了多種變換參數,以下就分開解釋一下他們的功用:
rotation_range=20 讓圖片隨機旋轉正負 20 度,模擬物體傾斜的情況;
width_shift_range 和 height_shift_range 設為 0.2,
讓圖片隨機水平和垂直移動 20%,模擬物體不在中央的場景;
shear_range=0.2 進行剪切變換,像把正方形拉成平行四邊形,模擬不同視角;
zoom_range=0.2 隨機縮放,讓模型適應大小不同的物體;
horizontal_flip=True 隨機水平翻轉,但要注意有些物體翻轉後意義會改變。
fill_mode='nearest' 決定變換後空白區域用最近的像素填充。
還有一個東西非常重要:
我們只對「訓練集」做資料增強,驗證集保持原樣以確保評估的客觀性。
最後用 fit() 讓資料產生器學習訓練資料的統計特性。
參考資料:
https://www.wpgdadatong.com/blog/detail/71762
在看程式碼前,我們當然要先知道什麼是「callbacks」:
在 Keras 裡,callbacks(回呼函式/回呼物件)是一種「在模型訓練過程中可以被自動呼叫的功能」。
它們就像「監聽器」一樣,會在特定時機點
(例如訓練開始、每個 epoch 結束、每個 batch 結束、訓練結束)自動執行指定的程式碼。
用我的理解我會這樣形容:
他就是一個紀錄的工具,每次都會更新最優的紀錄,
然後把它儲存起來。
而在了解完callbacks後,我們就可以來看程式碼了:
def create_callbacks():
return [
tf.keras.callbacks.ModelCheckpoint(
'best_cifar10_model.h5',
monitor='val_accuracy',
save_best_only=True,
save_weights_only=False,
verbose=1
),
tf.keras.callbacks.ReduceLROnPlateau(
monitor='val_loss',
factor=0.3,
patience=5,
min_lr=1e-7,
verbose=1
),
tf.keras.callbacks.EarlyStopping(
monitor='val_loss',
patience=15,
restore_best_weights=True,
verbose=1
),
tf.keras.callbacks.CSVLogger('training_log.csv')
]
callbacks = create_callbacks()
這段程式碼設定了四個智慧助手來監控訓練過程:
ModelCheckpoint 像「自動存檔功能」,監控 val_accuracy(驗證準確率),
每當發現更好的模型就自動儲存到 'best_cifar10_model.h5',確保我們永遠保留最佳版本。
ReduceLROnPlateau 是「學習率調節器」,當 val_loss(驗證損失)
連續 5 個 epoch(patience=5)沒改善時,就將學習率降為原來的 30%(factor=0.3),
最低不超過 1e-7,就像爬山接近山頂時自動放慢腳步。
EarlyStopping 防止過度訓練,當驗證損失連續 15 個 epoch 沒改善就自動停止訓練,
並恢復到最佳權重,避免過擬合。
CSVLogger 則像「訓練日記」,把每個 epoch 的所有指標記錄到 CSV 文件中,方便後續分析。
batch_size = 128
epochs = 100
history = model.fit(
datagen.flow(x_train, y_train, batch_size=batch_size),
steps_per_epoch = x_train.shape[0] // batch_size,
epochs = epochs,
validation_data = (x_test, y_test),
callbacks = callbacks,
verbose = 2
)
這段程式碼就是啟動實際訓練了,這邊就會整合前面準備的所有組件並開始讓它動起來啦!!!
之前提過很多次的函數我這邊就先省略,主要介紹一些之前沒有學習過的:
model.fit() : 核心訓練函數
datagen.flow() : 會源源不絕地提供經過資料增強的圖片批次
steps_per_epoch : 計算每個 epoch 需要多少批次(50000÷128≈390批次)
verbose=2 : 顯示每個 epoch 的訓練進度。
在訓練過程中,模型會重複進行「前向傳播(預測)計算損失→反向傳播(計算梯度)→更新權重」的循環,
並且會不斷記錄並更新,逐漸變得更聰明。
def evaluate_model(model, x_test, y_test):
print("\n=== 模型評估 ===")
results = model.evaluate(x_test, y_test, verbose=0)
# 處理不同數量的指標
if isinstance(results, list):
test_loss = results[0]
test_acc = results[1]
if len(results) > 2:
test_top5 = results[2]
print(f"測試集損失值: {test_loss:.4f}")
print(f"測試集正確率: {test_acc:.4f} ({test_acc*100:.2f}%)")
print(f"Top-5 正確率: {test_top5:.4f} ({test_top5*100:.2f}%)")
else:
print(f"測試集損失值: {test_loss:.4f}")
print(f"測試集正確率: {test_acc:.4f} ({test_acc*100:.2f}%)")
else:
# 只有一個值的情況
test_loss = results
test_acc = 0.0
print(f"測試集損失值: {test_loss:.4f}")
# 預測並計算混淆矩陣
y_pred = model.predict(x_test, verbose=0)
y_pred_classes = np.argmax(y_pred, axis=1)
return test_acc, y_pred_classes
test_acc, y_pred_classes = evaluate_model(model, x_test, y_test)
接著在模型評估部分,我們建立了彈性的模型評估系統,能適應不同的指標配置。
函數首先用 model.evaluate() 在測試集上評估模型表現,處理並返回結果:
如果是列表就依序提取損失值、準確率和可能的 Top-5 準確率;
如果只有單一數值就當作損失值處理。
損失值反映預測與真實答案的整體差距,準確率是最直觀的「答對百分比」,
Top-5 準確率則寬鬆一些,只要正確答案在前 5 個猜測中就算對。
接著用 model.predict() 獲得所有測試圖片的預測機率分布,
再用 np.argmax() 找出每張圖片機率最高的類別作為最終預測結果,
方便後續分析混淆矩陣或錯誤案例。
參考資料:
https://www.tensorflow.org/api_docs/python/tf/math/argmax
def plot_training_history(history):
fig, axes = plt.subplots(2, 2, figsize=(15, 10))
# Loss 曲線
axes[0,0].plot(history.history['loss'], label='訓練 Loss', linewidth=2)
axes[0,0].plot(history.history['val_loss'], label='驗證 Loss', linewidth=2)
axes[0,0].set_title('Loss 曲線', fontsize=14)
axes[0,0].set_xlabel('Epoch')
axes[0,0].set_ylabel('Loss')
axes[0,0].legend()
axes[0,0].grid(True, alpha=0.3)
# Accuracy 曲線
axes[0,1].plot(history.history['accuracy'], label='訓練 Accuracy', linewidth=2)
axes[0,1].plot(history.history['val_accuracy'], label='驗證 Accuracy', linewidth=2)
axes[0,1].set_title('Accuracy 曲線', fontsize=14)
axes[0,1].set_xlabel('Epoch')
axes[0,1].set_ylabel('Accuracy')
axes[0,1].legend()
axes[0,1].grid(True, alpha=0.3)
# Learning Rate 曲線 (如果有記錄)
if 'lr' in history.history:
axes[1,0].plot(history.history['lr'], linewidth=2, color='orange')
axes[1,0].set_title('Learning Rate', fontsize=14)
axes[1,0].set_xlabel('Epoch')
axes[1,0].set_ylabel('Learning Rate')
axes[1,0].set_yscale('log')
axes[1,0].grid(True, alpha=0.3)
# Top-5 Accuracy
if 'top_5_accuracy' in history.history:
axes[1,1].plot(history.history['top_5_accuracy'], label='訓練 Top-5', linewidth=2)
axes[1,1].plot(history.history['val_top_5_accuracy'], label='驗證 Top-5', linewidth=2)
axes[1,1].set_title('Top-5 Accuracy 曲線', fontsize=14)
axes[1,1].set_xlabel('Epoch')
axes[1,1].set_ylabel('Top-5 Accuracy')
axes[1,1].legend()
axes[1,1].grid(True, alpha=0.3)
plt.tight_layout()
plt.savefig('training_curves.png', dpi=300, bbox_inches='tight')
plt.show()
plot_training_history(history)
在視覺化部分的程式碼,我們創建了一個多面向的訓練過程視覺化。
首先,使用 2×2 的子圖布局,展示四個關鍵面向:
Loss 曲線顯示訓練和驗證的錯誤程度變化,理想情況下兩條線都應該平穩下降且保持相近;
Accuracy 曲線更直觀地顯示正確率提升軌跡,幫助識別過擬合(訓練準確率遠高於驗證準確率);
Learning Rate 曲線追蹤學習率的動態變化,使用對數刻度顯示 ReduceLROnPlateau 的調整效果;
Top-5 Accuracy 曲線提供更寬鬆的評估視角。
每個圖表都加上網格線、圖例和適當的標籤,最終以高解析度儲存為 PNG 檔案。
這些視覺化工具是診斷訓練問題的重要依據,好的曲線應該顯示平滑收斂、
無劇烈震盪、訓練與驗證表現相近的特徵。
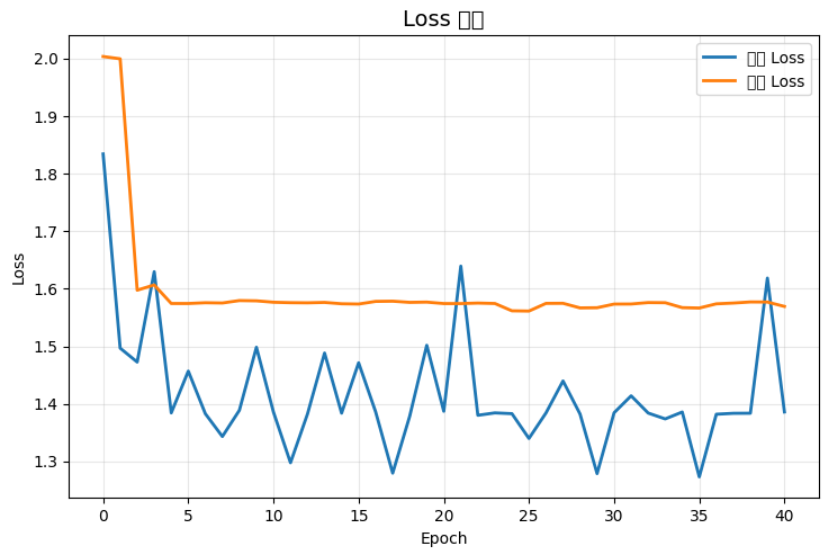
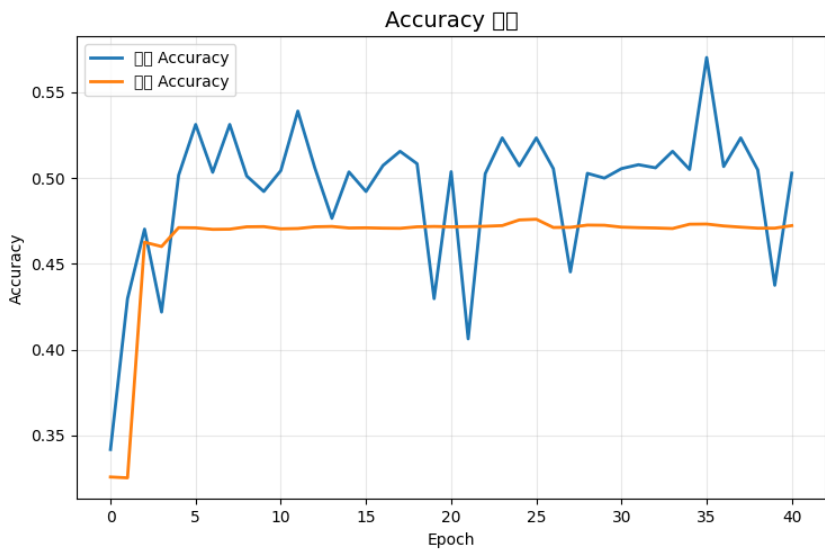
上面兩張圖片就是執行出來的結果,這邊先看形式為主,
後面會再解釋。
def show_predictions(model, x_test, y_test, num_samples=8):
"""展示預測結果和真實標籤"""
fig, axes = plt.subplots(2, 4, figsize=(16, 8))
axes = axes.ravel()
# 隨機選擇樣本
indices = np.random.choice(len(x_test), num_samples, replace=False)
for i, idx in enumerate(indices):
img = x_test[idx]
pred = model.predict(img[np.newaxis, ...], verbose=0)
pred_class = np.argmax(pred[0])
pred_prob = np.max(pred[0])
true_class = y_test[idx]
axes[i].imshow(img)
axes[i].axis('off')
# 設定顏色:正確=綠色,錯誤=紅色
color = 'green' if pred_class == true_class else 'red'
axes[i].set_title(
f'True: {class_names[true_class]}\n'
f'Pred: {class_names[pred_class]}\n'
f'Conf: {pred_prob:.3f}',
color=color, fontsize=10
)
plt.tight_layout()
plt.savefig('predictions_sample.png', dpi=300, bbox_inches='tight')
plt.show()
show_predictions(model, x_test, y_test)
這邊就是很直觀的預測結果展示系統,讓我們能親眼看到模型的「思考過程」。
函數會隨機選擇 8 張測試圖片進行展示,使用 2×4 的網格布局。
對每張圖片,先用 img[np.newaxis, ...] 添加批次維度(因為 predict 需要批次輸入),
然後獲得模型的預測機率分布。
np.argmax() 找出機率最高的類別作為預測結果,np.max() 獲得對應的信心度分數。
接著顯示原始圖像並關閉座標軸,用顏色編碼預測結果:
綠色表示預測正確,紅色表示錯誤。
標題顯示真實類別名稱、預測類別名稱和信心度(範圍 0-1)。
這種視覺化比純數字統計更有價值,我們可以分析模型容易搞混哪些類別、
是否受圖片品質影響、高信心度預測是否更準確等問題,對於建立對模型能力的直觀理解非常重要。


print("\n儲存最終模型...")
model.save('cifar10_improved_cnn.h5')
print("模型已儲存為 'cifar10_improved_cnn.h5'")
# 儲存訓練歷史
import pickle
with open('training_history.pkl', 'wb') as f:
pickle.dump(history.history, f)
print("訓練歷史已儲存為 'training_history.pkl'")
# 輸出最終結果摘要
print(f"\n=== 訓練完成 ===")
print(f"最佳驗證準確率: {max(history.history['val_accuracy']):.4f}")
print(f"最終測試準確率: {test_acc:.4f}")
print(f"訓練總輪數: {len(history.history['loss'])}")
這邊就是最後的程式碼,完成了訓練成果的完整保存工作。
model.save() 將完整模型儲存為 H5 格式,包含模型架構、訓練好的權重和編譯配置,
這樣就能在任何時候重新載入完整功能的模型。
接著用 pickle 模組將 history.history(包含每個 epoch 的所有指標記錄)序列化儲存,
這些詳細的訓練歷史對未來分析、比較實驗或撰寫報告都很有價值。
最後輸出關鍵的訓練總結:最佳驗證準確率反映模型的最高潛能,
最終測試準確率代表在未見過資料上的真實表現,
實際訓練輪數顯示是否因 EarlyStopping 提前結束。
最後當然就是成果展示啦!
因為一開始的結果不盡人意,準確率只有可憐的47%,
所以我有對程式碼做以下些為更改:
我將初始學習率從一開始的 1e-3 調整成 5e-3 ,
因為有可能是因為初始學習率 1e-3 太小,導致模型學習太慢。
initial_learning_rate = 5e-3 # 從 1e-3 改為 5e-3
我將資料增強的幅度調低了一些,
因為當增強太激進時,模型可能會難以學習一致的特徵。
train_datagen = ImageDataGenerator(
rotation_range=10, # 從 20 減為 10
width_shift_range=0.1, # 從 0.2 減為 0.1
height_shift_range=0.1, # 從 0.2 減為 0.1
在更改完過後,我們就來比較一下差異吧:
版本一(初版):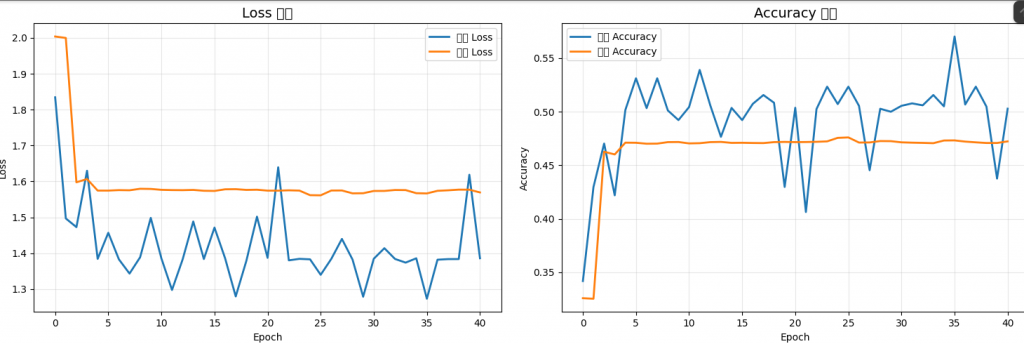
可以看到,藍線(訓練 Loss)波動很大,橘線(驗證 Loss)則幾乎是一條平線,
這顯示模型無法有效學習,驗證損失完全沒有下降趨勢。
而在Accuracy曲線中也是一樣,Accuracy值幾乎沒有因訓練次數上升而有提高,
也代表說他根本沒有學習到任何東西,他把老師的話都當耳邊風。
版本二(修改版):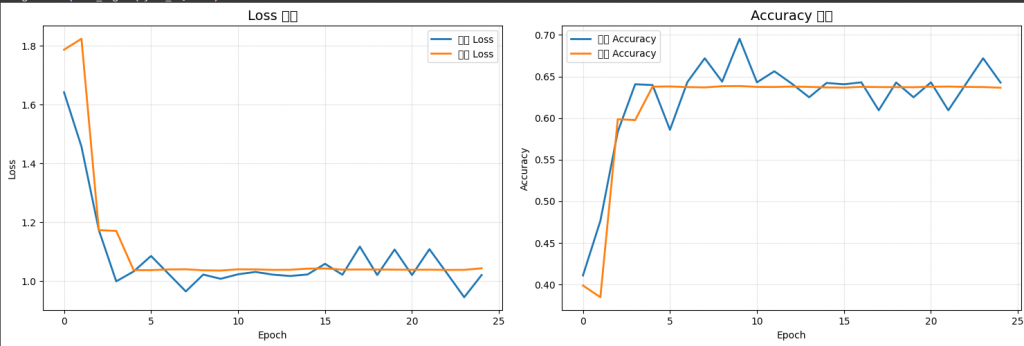
相對上面的圖片應該就很明顯了,這組曲線明顯有因訓練次數上升,
而降低損失率並提高了準確率。
大家也可以看一下CIFAR-10透過訓練出來的圖片辨識圖:
最終,我們從原本的47%準確率提高到了63%,還可以再精進,
但目前已經達到學習效果了,今天就先到這裡就好,後面還有很多實作,
下次再戰!!!


