在前幾天,我們專注在處理圖片的神經網路,尤其是 CNN 如何幫助我們從圖片中找出特徵。
但世界上的資料並不只有圖片,還有許多與「時間」或「順序」密切相關的訊號,
例如股市的走勢、語音訊號,甚至是我們日常的文字句子。
這些資料有一個共通點:
它們不是單一靜態的輸入,而是一段「序列」,每個元素之間往往有上下文的關聯。
而為了處理這類資料,研究者提出了一種特別的神經網路結構
今天的學習中,我們就來專心研究關於RNN的資訊,我們為什麼需要他?
他在我們的使用中扮演了什麼角色?
RNN,全名 Recurrent Neural Network(遞迴神經網路),是一種專門設計來處理序列資料的神經網路。
它和一般的神經網路不同,最大特色是擁有「循環結構」。
這種循環讓網路在處理當前輸入時,能同時參考前一步驟的資訊,形成一種「記憶」效果。
我們也就可以說,RNN 能理解資料之間的前後關係,而不只是單一片段。
我們再舉個範例來說,如果要讓模型理解一句話:「我今天很開心」,
傳統神經網路只會單獨看「今天」或「開心」這些詞,但 RNN 則會把「我」「今天」「很」這些前文保留下來,
讓「開心」的判斷更合理。
這種設計,使得 RNN 特別適合應用在語音辨識、語言翻譯、文字生成,
甚至股價預測等需要考慮時間與順序的任務。
RNN 的最大特色在於,它不只看「當下」的輸入,
還能保留「過去」的資訊,並且將這些歷史內容一併考慮進去。
RNN 有一個「隱藏狀態(hidden state)」,這個狀態能記住之前時間步驟的內容。
當新的輸入到來時,模型會把它與隱藏狀態融合,決定新的輸出。
假設我們要讓模型完成一句話 —「西瓜是綠色的」。當模型讀到「西瓜」時,它會把這個詞存進記憶。
接下來讀到「是」時,它會參考剛剛記住的「西瓜」,進一步推測合理的延續。
最後,它有很大機率會輸出「綠色」,因為「西瓜」和「綠色」在上下文中有自然的連結。
這就是 RNN 能處理上下文語意的直觀原因。
在結構上,RNN 其實和一般神經網路很相似:
都有輸入層、隱藏層和輸出層。
但不同的是,RNN 的隱藏層會「遞迴」接收自己在前一時間步的輸出,這形成一個環狀的訊息流。
因此,輸入不再是孤立的,而是與之前的步驟有連結。
數學上,如果我們用 xt 表示當前時間步的輸入,ht 表示隱藏狀態,那麼它的更新公式大致可以寫成:
https://vocus.cc/article/678c898cfd897800012d7158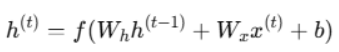
(來源:https://vocus.cc/article/678c898cfd897800012d7158)
在實作中,我們常根據「輸入與輸出在時間上的對應關係」把問題分類,
了解這些有助於選模型與 loss 設計。
而根據 input 及 output 的數目,RNN 也可以有很多的變化與應用,
以下就舉出常見的例子供大家參考:
標準分類(像一張圖片對一個標籤)。
多個時間步輸入,輸出一個結果(例如情緒分類:一段文字輸出一個情感標籤)。
單一輸入產生序列輸出(像從一張圖片生成描述句子)。
輸入序列到輸出序列(機器翻譯、語音轉文字);
若 input/output 同步長度(例如序列標註)可直接對齊,
否則用 seq2seq 結構或 attention。
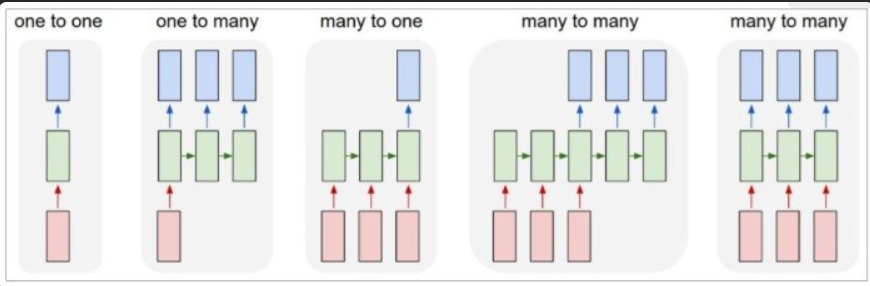
(圖片來源:https://hackmd.io/@4XoSjtMaS46Zzn7DwmEIEQ/Syjf9EOPL
透過以上這些靈活的設計,
就讓 RNN 能廣泛應用於語音辨識、文字生成、時間序列預測等不同領域。
雖然 RNN 在處理序列資料上有它的獨特優勢,但它也存在一些相當明顯的限制與挑戰,
這些問題在實務應用中常常讓模型效果打折扣。
以下我會用比較多譬喻的方式,來談談這些可能會有的問題:
首先我們要談到的是「長期依賴問題」(long-term dependency problem)。
RNN 雖然能記住前面步驟的資訊,但隨著序列變得愈長,早期的訊息會逐漸消失,模型只會保留最近的內容。
如果當你要讓模型理解一句很長的句子:「我昨天在書店買了一本關於人工智慧的書,它的內容非常精彩,尤其是關於神經網路的部分……」,當模型處理到後面「神經網路」這幾個字時,它可能早就忘了前面提到的「人工智慧」。
這樣的情況會導致模型無法準確捕捉長距離的語意關聯。
接著是「梯度消失與梯度爆炸」(vanishing & exploding gradients)。
在訓練 RNN 的過程中,誤差需要一層層往回傳遞(反向傳播),這時候梯度會經過很多次相乘。
如果數值太小,會導致梯度幾乎變成零,模型更新停滯,這就叫做梯度消失;
而如果數值太大,則會導致模型參數劇烈震盪,這就叫做梯度爆炸。
這兩種情況都會讓訓練變得不穩定,甚至完全失敗。
這也是為什麼早期的 RNN 難以處理較長的序列。
再來是關於「計算效率」的挑戰。
由於 RNN 是「逐步」處理輸入,也就是說它要一個接著一個時間點地運算,
而不像 CNN 那樣可以並行處理整張圖片,因此在處理很長的資料序列時,速度會變得非常慢。
最後,還有「過度依賴順序資訊」的問題。RNN 很擅長利用前後文的順序,
但在某些情境中,並不是所有資訊都要強調「時間先後」。
例如在一段文字中,有些詞與詞的關聯不必依賴順序,
而是更廣泛的語意關係。RNN 在這方面表現就不如後來的 Transformer 架構。
RNN 雖然在某些地方逐漸被 Transformer 取代,
但在處理需要「順序資訊」的資料時,依然有許多經典且實用的應用。
以下列出幾個代表性的例子,並附上簡單說明:
RNN 能夠理解文字中的先後關係,例如用於語言模型(預測下一個字或詞)、自動補全、以及機器翻譯。
當如果我輸入「我今天想去」,RNN 可能預測下一個字是「運動」或「看電影」。
語音是一種隨時間變化的訊號,RNN 可以逐步處理聲音片段並將其轉換為文字。這就是像 Siri、Google 助理等語音助理背後的核心技術之一。
在金融市場,RNN 常被用來分析股價、匯率的過去走勢,並預測未來的變化。天氣預測也是另一個應用,透過歷史資料推估未來的降雨量或溫度。
影片是一連串的影像,RNN 能夠捕捉畫面隨時間的變化,進而做出動作辨識。例如判斷某人是在「打籃球」還是「游泳」。
在電商或社群平台中,RNN 可以依照使用者過去的操作順序(如點擊、瀏覽或購買紀錄),推測他可能的下一個動作,並提供個人化推薦。
這些應用的共同點,就是「時間順序」或「資料的先後關聯性」很重要。
RNN 善於捕捉這種序列結構,因此能在這些領域發揮作用。
而為了克服這些問題,研究者在後來提出了改良版本的 RNN,
例如像是 LSTM(長短期記憶網路)和 GRU(門控遞迴單元),它們能更好地捕捉長期依賴關係。
再往後,Transformer 架構更是徹底顛覆了 RNN 的方式:
它完全拋棄「循環」設計,改用注意力機制(Attention)同時考慮整個序列,
讓運算能並行化,大幅加速訓練並提升長期記憶能力。
以上就是我們今天對RNN的介紹了,接下來也會進行實作,敬請期待。
參考資料:
https://hackmd.io/@4XoSjtMaS46Zzn7DwmEIEQ/Syjf9EOPL

