在使用 LLM(大型語言模型)的時候,我們其實是透過一段「指令」來告訴模型要做什麼,
這段指令就叫做 提示詞(Prompt)。 在 Day 15 & Day 16,我們會把重心放在「語言模型層的」Prompt Generation 的部分,規範 LLM 輸出的模板。
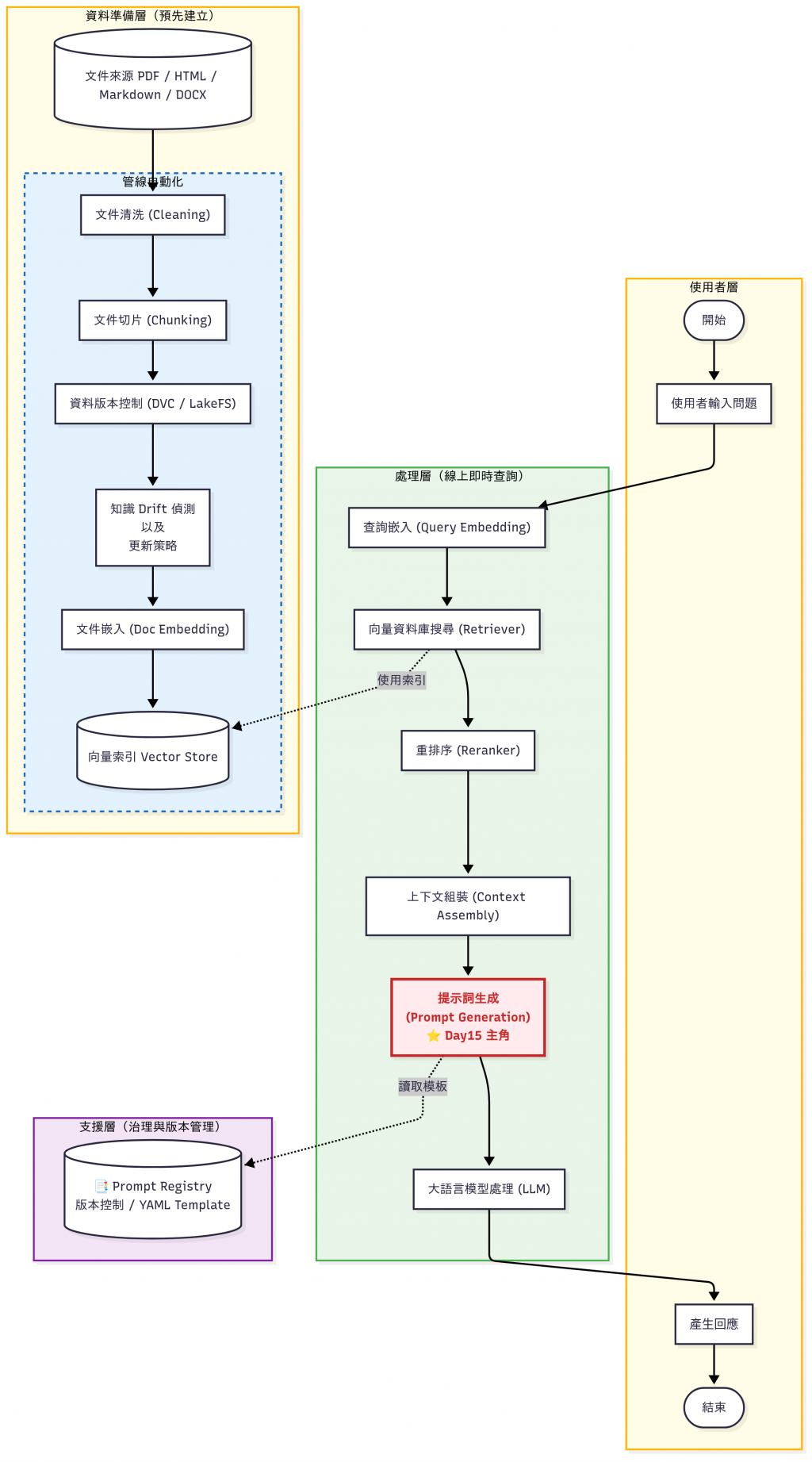
如圖所示,紅色和紫色是今天要談的部分:
很多人以為設計 Prompt 就等於在「訓練模型」,其實兩者完全不同:
| 項目 | Prompt | Fine-tuning |
|---|---|---|
| 本質 | 一段臨時的「指令」,影響模型回應 | 在模型參數上進行再訓練 |
| 是否改變模型參數 | ❌ 不會 | ✅ 會永久改變 |
| 影響範圍 | 當前輸入 / 當前對話 | 全部任務(模型學會新風格或知識) |
| 成本 | 幾乎免費(只需設計文字) | 需要資料集、算力、時間 |
| 適用情境 | 快速調整行為:格式、角色、語氣 | 長期任務:特定領域專業、固定格式 |
👉 Prompt 就像「臨時給助理的指令」,
👉 Fine-tuning 才是「重新訓練助理,讓他永久具備新能力」。
舉個 Prompt 的例子:
你是一個企業 FAQ 助理。請根據提供的知識庫內容回答使用者問題:
文件片段:{{context}}
問題:{{question}}
這就是一個提示詞(Prompt),其中 {{context}} 和 {{question}} 是動態填入的變數。
Prompt 決定了模型的 行為:
可以在今天的 GitHub Demo 中查看
demo_different_prompt.py範例
以下程式展示 同一個模型,只改 Prompt,行為就完全不同:
from openai import OpenAI
client = OpenAI()
def ask(prompt, question):
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=[
{"role": "system", "content": prompt},
{"role": "user", "content": question}
]
)
return response.choices[0].message.content
# Prompt A:客服助理
prompt_a = "你是一個專業客服助理,請用條列式回答。"
# Prompt B:詩人
prompt_b = "你是一個詩人,請用優美的散文回答。"
question = "請介紹一下 VPN 的用途"
print("=== 客服助理 ===")
print(ask(prompt_a, question))
print("\n=== 詩人 ===")
print(ask(prompt_b, question))
執行結果:
❯ python demo_different_prompt.py
=== 客服助理 ===
VPN(虛擬私人網路)的用途包括:
1. **加密數據傳輸**:VPN能夠加密網絡流量,確保用戶的數據在互聯網上傳輸時安全,防止被竊取和監視。
2. **隱藏用戶 IP 地址**:使用VPN可以隱藏用戶的真實IP地址,從而提高上網的匿名性和隱私保護。
3. **繞過地理限制**:VPN能幫助用戶訪問在其所在國家限制或封鎖的網站和內容,如串流媒體服務。
4. **安全連接公共 Wi-Fi**:在公共Wi-Fi環境中使用VPN可以保護用戶的數據,防止黑客攻擊。
5. **遠程訪問內部網絡**:企業使用VPN來讓遠程工作人員安全地訪問內部網絡和資源。
6. **避免帶寬限制**:某些ISP(互聯網服務提供商)可能限制特定應用程式的帶寬,使用VPN可以幫助用戶繞過這些限制。
如果您還有其他問題或需要更多資訊,隨時告訴我!
=== 詩人 ===
在這個數位化迅速發展的時代,虛擬私人網絡(VPN)如同一層隱形的保護罩,悄然守護著我們的網絡安全與隱私。它不僅僅是科技的結晶,更是連結虛擬世界與現實生活之橋樑。
當我們在公共Wi-Fi下悠然瀏覽,或在異國他鄉的咖啡館裡享受靜謐,VPN似是一位無形的守護神,為我們的數據加密,防止黑客的侵入,讓私密的資訊在茫茫網海中不被竊取。它如同夜空中的星辰,點滴閃爍,讓你在脆弱的網絡環境中找到一絲安心。
此外,VPN還能打破地域限制,讓我們如同羽翼般自由地穿越數字疆界。或許你已經體驗過,在某些國家或地區,特定網站、應用無法正常訪問。而VPN的神奇之處,就是可以將你的網絡位置隱藏,令你如同隱形人般,自在享受全球資訊的饗宴。
更甚者,在追求匿名的道路上,VPN讓你在虛擬空間中游刃有餘,如同流淌於一條未經雕琢的河流,無懼他人的窺視或琢磨。你的身影在數字舞台上如煙似霧,模糊而又美麗。
總之,VPN不僅是技術的工具,更是一種對私隱的尊重和對自由的追求。在這瞬息萬變的網絡時代,它如同一把鑰匙,打開了數字世界的無限可能,讓我們在每一次的點擊與滑動中,安心探索,無畏無懼。
輸出結果會呈現兩種截然不同的風格,雖然底層模型完全相同。這正是 Prompt 的威力:不改模型,只靠文字指令,就能調整行為。
而到目前為止,我們已經完成了從 資料處理 Pipeline 的基礎架構。今天要轉換到另一個同樣關鍵的層面:Prompt Engineering。今天要轉換到另一個同樣關鍵的層面:Prompt Engineering。
很多人以為 Prompt 就是「想個指令丟進去」,但在真實專案裡,如果沒有系統化管理,會很快陷入混亂:
👉 所以我們需要「Prompt Engineering 的系統化方法」。
零散
Prompt。Notion,有人甚至貼在 Slack。難追蹤
JSON 格式輸出」,卻沒有回報或記錄。難測試
環境依賴
GPT-4o 可能理解得很好,但 Claude 會加油添醋,Llama 2 可能答非所問。LLM Provider,就需要針對不同模型調整 Prompt。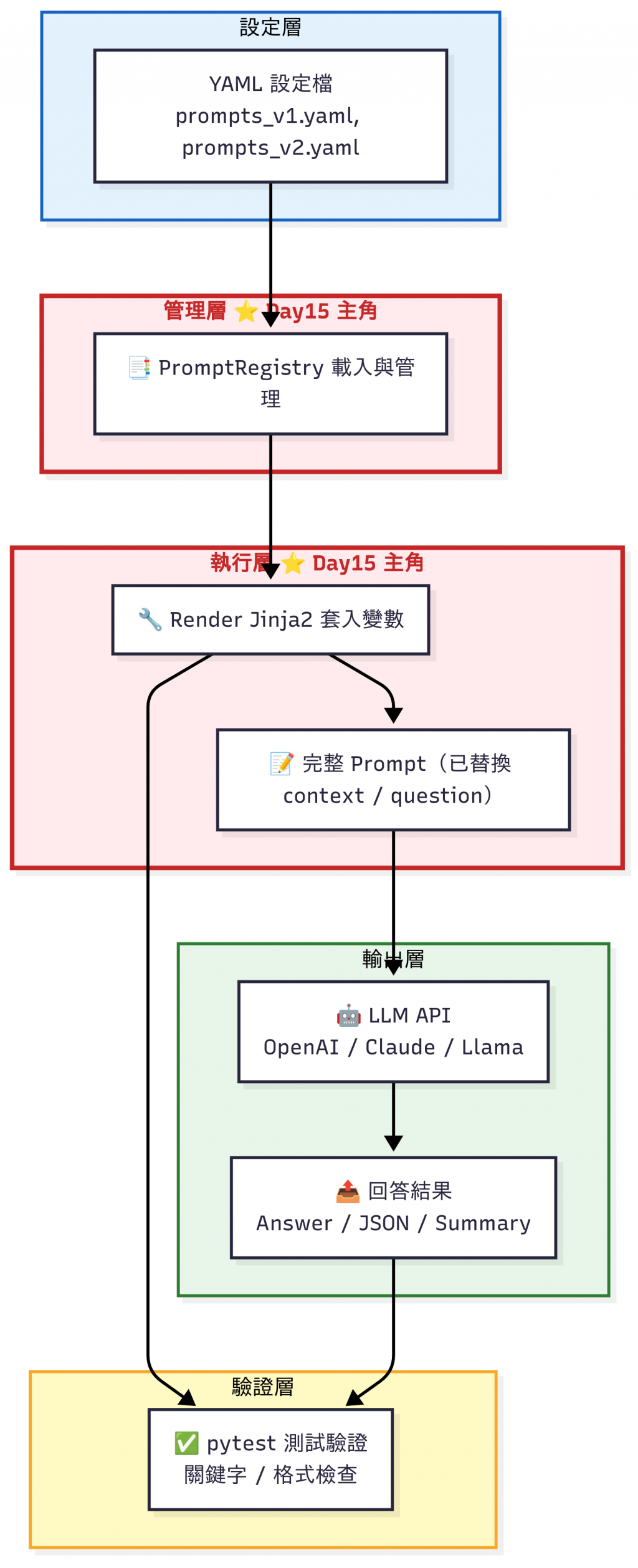
Prompt Engineering 流程圖
| 方法 | 核心概念 | 實作方式 | 作用 / 價值 | 應用情境 |
|---|---|---|---|---|
| 1. Prompt 模板化 (Template) | 把 Prompt 抽象化,避免硬寫在程式 | 使用 YAML 設定檔 + 佔位符 {{context}} / {{question}} |
提高 可重用性,方便快速修改 | FAQ Bot、文件摘要、不同部門共用同一套 Prompt |
| 2. Prompt 版本控制 (Registry) | 集中管理不同版本 Prompt | 建立 PromptRegistry,讀取多個 YAML (v1, v2) |
像程式碼一樣有 版本管理,可追蹤與回滾 | AB 測試不同 Prompt 效果、回滾到穩定版本 |
| 3. Prompt 測試 (Testing) | 驗證 Prompt 是否符合規範 | 建立 pytest 測試集:輸入問題/上下文 → 檢查輸出格式/關鍵字 | 確保 更新不會退化,避免輸出錯亂 | 檢查 JSON 格式輸出、FAQ 規則回答、避免幻覺 |
| 4. Prompt 與系統整合 | 在 API Gateway 層統一調用 Prompt | Gateway 呼叫 Registry → Render → 傳給 LLM → 記錄 Prompt ID | 讓 Prompt 成為 系統治理的一環,利於 Debug 與一致性 | API 層集中控管、日誌追蹤 Prompt ID、跨服務共享 |
將 Prompt 規範化,透過佔位符 {{variable}} 插入動態內容,這樣可以避免「硬寫死」Prompt,方便重複使用。
準備兩個不一樣的 prompt template 模板,模擬有多個不同 prompts 的情境:
# registry/prompts_v1.yaml
prompts:
faq:
description: "客服 FAQ:根據文件回答使用者問題,輸出條列式。"
template: |
你是一個專業客服助理,請根據以下文件回答使用者問題,並用條列式輸出。
【文件片段】
{{ context }}
【問題】
{{ question }}
【回答要求】
- 僅引用文件內容,不要捏造
- 若文件無相關資訊,回覆「文件中未提及」
summary:
description: "文件總結:三點重點。"
template: |
請將以下內容總結為三點重點,每點不超過 20 字:
{{ context }}
# prompts/prompts_v2.yaml
prompts:
faq:
description: "客服 FAQ:JSON 格式輸出,附引用"
template: |
你是一個專業客服助理,請依據下列文件回答問題,並用 JSON 格式輸出:
{
"answer": "根據文件的回答,簡短扼要。",
"citations": ["相關文件片段"]
}
【文件內容】
{{ context }}
【問題】
{{ question }}
【回答要求】
- 僅能引用文件,不要自行捏造
- 若文件中無相關資訊,請將 answer 設為「文件中未提及」
- citations 欄位至少包含一個文件片段
summary:
description: "文件總結:JSON 條列三點"
template: |
請將以下內容總結為三點重點,並輸出為 JSON:
{
"bullets": [
"第一點,不超過 20 字",
"第二點,不超過 20 字",
"第三點,不超過 20 字"
]
}
【文件內容】
{{ context }}
然後透過這個模板生成對應的 prompt,就可以看出差異:
❯ python demo.py
Versions: ['v1', 'v2']
Prompts in v1: ['faq', 'summary']
[FAQ v1]
你是一個專業客服助理,請根據以下文件回答使用者問題,並用條列式輸出。
【文件片段】
VPN 文件路徑:/docs/vpn/setup
【問題】
公司 VPN 怎麼設定?
【回答要求】
- 僅引用文件內容,不要捏造
- 若文件無相關資訊,回覆「文件中未提及」
[FAQ v2]
你是一個專業客服助理,請依據下列文件回答問題,並用 JSON 格式輸出:
{
"answer": "根據文件的回答,簡短扼要。",
"citations": ["相關文件片段"]
}
【文件內容】
VPN 文件路徑:/docs/vpn/setup
【問題】
公司 VPN 怎麼設定?
【回答要求】
- 僅能引用文件,不要自行捏造
- 若文件中無相關資訊,請將 answer 設為「文件中未提及」
- citations 欄位至少包含一個文件片段
就像程式碼需要 Git,Prompt 也需要版本管理:
PromptRegistry 會把 YAML 讀進來,並依檔名 (v1, v2) 分版本管理。get() 和 render() 介面,讓程式可以輕鬆取用 Prompt。# registry/registry.py
# registry/registry.py
from pathlib import Path
import yaml
from jinja2.sandbox import SandboxedEnvironment
class PromptRegistry:
def __init__(self, folder: str):
self.folder = Path(folder)
# 初始化 Jinja2 環境(sandbox 版本比較安全)
self._env = SandboxedEnvironment(autoescape=False)
self._prompts = {} # {version: {name: {template: str}}}
self._load_all()
def _load_all(self):
for file in sorted(self.folder.glob("prompts_v*.yaml")):
version = file.stem.replace("prompts_", "")
with open(file, "r", encoding="utf-8") as f:
data = yaml.safe_load(f) or {}
self._prompts[version] = data.get("prompts", {})
def list_versions(self):
return sorted(self._prompts.keys())
def list_prompts(self, version: str):
if version not in self._prompts:
raise KeyError(f"未知版本 {version},可用版本: {self.list_versions()}")
return list(self._prompts[version].keys())
def get(self, name: str, version: str):
try:
return self._prompts[version][name]["template"]
except KeyError:
raise KeyError(f"找不到 prompt: {name} (版本 {version})")
def render(self, name: str, version: str, **kwargs):
tmpl = self._env.from_string(self.get(name, version))
return tmpl.render(**kwargs)
這樣就能避免 Prompt 散亂在不同的資料夾下,改成統一存放、調用。
建立一組「標準輸入 & 預期輸出」測試集:
當 Prompt 更新後,自動跑單元測試,確保更新 Prompt 不會導致重要規則消失。
例如:
# ---- 規範:v1 FAQ (條列式) ----
def test_faq_v1_contains_core_instructions(reg):
rendered = reg.render(
"faq", "v1",
context="VPN 文件路徑:/docs/vpn/setup",
question="公司 VPN 怎麼設定?"
)
must_contains = [
"你是一個專業客服助理",
"【文件片段】",
"【問題】",
"僅引用文件內容,不要捏造",
"文件中未提及",
"VPN 文件路徑:/docs/vpn/setup",
"公司 VPN 怎麼設定?",
]
for m in must_contains:
assert m in rendered
透過這樣的測試檔,我們至少能避免「明顯壞掉」的情況,例如輸出格式錯亂或回答完全無關。不過,到這裡我們其實還沒有回答一個更現實的問題:
🤔 「同樣的問題,用 v1 Prompt 與 v2 Prompt,哪一個表現比較好?」
這就是 Prompt 效果比較 (Prompt Evaluation) 的範疇。
在 Day20,我們會示範如何建立基準測試 (benchmark),甚至讓 LLM 當裁判,幫忙評分不同版本 Prompt 的優劣。
| 面向 | 重點 | 實務作法 | 類比 Web 開發 |
|---|---|---|---|
| 測試策略 | 格式驗證不足,需要驗證回答品質 | - 建立 Golden Dataset(標準問答集)- 使用 ROUGE / BERTScore / embedding 評估- 做 A/B 測試 比較 v1 vs v2 | 單元測試 + 效能測試 |
| 成本與效能 | Prompt 長度 = Token 成本 | - 詳細指令:更穩定,但 成本↑ 延遲↑- 精簡指令:便宜快速,但品質不穩- 壓測 + 成本監控,找平衡點 | 效能改善 + 成本管控 |
| 安全性 | 防範使用者輸入惡意指令(Prompt Injection) | - 輸入驗證:黑名單 / 白名單- 清理:移除危險字串 / 控制符號 | Web API 的 Input Validation |
最後,我們可以在 API Gateway 層統一管理 Prompt (請參見 GitHub Repo - gateway.py):
在 API Gateway 上面用 Header 可以指定 prompt 版本:
@app.post("/ask")
def ask(body: AskBody, x_prompt_version: Optional[str] = Header(None)):
"""
主功能:接收使用者問題,透過 Prompt Registry 渲染後送去 LLM
"""
# 如果 header 裡有指定版本,會覆蓋 body 的設定
version = x_prompt_version or body.prompt_version
pid = f"{body.prompt_name}:{version}"
# 1. 渲染 Prompt
# 從 Registry 拿到模板,替換 {{context}} 與 {{question}}
prompt = REG.render(
body.prompt_name, version,
context=body.context, question=body.question
)
# 2. 呼叫 OpenAI API
resp = client.chat.completions.create(
model=body.model,
messages=[{"role": "user", "content": prompt}],
temperature=0
)
resp_text = resp.choices[0].message.content
# 3. 記錄日誌
# 方便之後 Debug:知道用的是哪個 Prompt + 哪個模型
log.info("ASK prompt_id=%s model=%s q=%r", pid, body.model, body.question)
# 4. 回傳結果
return {
"answer": resp_text, # LLM 的回覆
"prompt_id": pid, # 使用的 Prompt 名稱 + 版本
"model": body.model # 呼叫的模型
}
啟動 APP 後可以透過在 Header 輸入不同版本查看回答的差異性:
❯ uvicorn gateway:app --reload --port 8000
INFO: Will watch for changes in these directories: ['/Users/hazel/Documents/github/2025-ironman-llmops/day15_prompt_registry']
INFO: Uvicorn running on http://127.0.0.1:8000 (Press CTRL+C to quit)
INFO: Started reloader process [74060] using WatchFiles
INFO: Started server process [74062]
INFO: Waiting for application startup.
INFO: Application startup complete.
另外開啟 Terminal 輸入問題,以下是 prompts/prompts_v1.yaml 的結果:
❯ curl -s http://localhost:8000/ask \
-H "Content-Type: application/json" \
-H "X-Prompt-Version: v1" \
-d '{
"question": "公司的總部在哪?",
"context": "文件:公司資訊…",
"prompt_name": "faq",
"model": "gpt-4o-mini"
}' | jq .
{
"answer": "- 文件中未提及",
"prompt_id": "faq:v1",
"model": "gpt-4o-mini"
}
以下是 prompts/prompts_v2.yaml 的結果:
❯ curl -s http://localhost:8000/ask \
-H "Content-Type: application/json" \
-H "X-Prompt-Version: v2" \
-d '{
"question": "公司的總部在哪?",
"context": "文件:公司資訊…",
"prompt_name": "faq",
"model": "gpt-4o-mini"
}' | jq .
{
"answer": "```json\n{\n \"answer\": \"文件中未提及\",\n \"citations\": [\"文件:公司資訊…\"]\n}\n```",
"prompt_id": "faq:v2",
"model": "gpt-4o-mini"
}
可以看到即使是同樣的找不到回答,也可以透過 Registry 儲存的不同 prompt 模板顯示出差異性。
⚠️ 小提醒:這裡的範例主要是示範 Prompt Registry 的整合流程,而不是檢索的完整性。如果
context裡只包含「文件路徑」這種簡略資訊,模型可能會回覆「文件中未提及」。這是設計上的合理行為,因為我們的模板強調「僅能引用文件,不可捏造」。在之後的章節,我們會進一步加入檢索與內容豐富的上下文,來比較不同 Prompt 在真實場景下的表現差異。
在今天的範例中,我們可以看到:
兩者結合,才能讓 LLM 在企業級場景中真正可控、可維護。
明天(Day 16),我們會進一步介紹 Prompt Template & Chain(例如 LangChain / Guidance),展示如何把多個 Prompt 串成 可重複的流程,讓 LLM 從「單次問答」升級成「任務自動化

