
在完成了基礎的 RAG 架構後,接下來我們一項重點是:如何在地端運行 LLM(Large Language Model)?
目前常見的佈署工具包含 Ollama、vLLM 以及 llama.cpp。以下整理了一份比較表供大家參考。
| 特點 | Ollama | vLLM | llama.cpp |
|---|---|---|---|
| 定位 | 提供簡單易用的本地 LLM 運行環境,支援多種模型一鍵安裝與管理 | 高效能推理框架,專注於伺服器端大規模部署 | 輕量化 C++ 實作,強調跨平台與低資源可用性 |
| 安裝與使用 | 安裝簡單(brew install ollama / Windows installer),透過 ollama run 即可快速啟動模型 |
需要 Python 環境與 CUDA,部署流程相對複雜,需要自行下載模型權重 | 單一可執行檔,無需額外依賴,可直接在 CPU 上跑 |
| 模型支援 | 內建支援 LLaMA、Mistral、Gemma 等主流模型,下載即用 | 支援 Hugging Face Transformers 格式,適合自訓練或自定義模型 | 支援 GGUF 量化模型,特別適合資源有限的環境 |
| 效能優勢 | 啟動快,支援 GPU 加速與量化模型,適合快速試驗 | 針對大模型最佳化(PagedAttention 等技術),能高效處理大批量請求 | 可在無 GPU 環境下運行,記憶體需求低,支援 4-bit/8-bit 量化 |
| API/整合 | 提供 REST API,易於整合進 RAG、Agent 框架 | 需自行包裝 API 或搭配 FastAPI,適合進階使用者 | 無內建 API,需要自行包裝,適合低階控制或嵌入式場景 |
| 適合硬體 | 一般 PC(>=16GB RAM)即可跑中小模型;若有 GPU(>=8GB VRAM)則能流暢運行 7B~13B 模型 | 需要較強硬體:GPU (>=24GB VRAM) + 大記憶體,適合伺服器環境 | CPU-only 也能執行;Raspberry Pi / MacBook Air 這類低功耗設備都可跑小模型 |
| 典型場景 | 個人開發者做 Demo、快速原型、RAG 測試 | 企業伺服器端,需處理多用戶、大流量請求 | 個人裝置、邊緣運算、沒有 GPU 的環境 |
| 社群與維護 | 活躍度高,官方提供 Windows/Mac/Linux 支援 | 主要由研究社群與企業維護,偏向 AI infra 領域使用 | 開發社群活躍,持續支援量化格式,特別適合開源愛好者 |
企業場景 → vLLM
個人場景 → Ollama / llama.cpp
由於我們的目標是 在地端完成一個個人化的 RAG Demo,因此選擇 Ollama:
以下將依照不同作業系統,提供安裝方法與基本操作,不過筆者的環境是windows,後續介紹會繼續以window系統為主。
brew install ollama
安裝完成後即可使用 ollama 指令。
ollama --version
確認是否安裝成功。
curl -fsSL https://ollama.ai/install.sh | sh
完成後,重新打開終端機即可使用。
接下來我們介紹在 Windows 環境 下用Ollama安裝LLM,並以 RTX 3060 的硬體資源(筆者目前只有這張卡QQ),說明如何選擇合適的模型。
在安裝 LLM 之前,先確認目前電腦的 GPU / RAM / 磁碟 能支援哪樣規格的LLM 運行。
打開 PowerShell 或 命令提示字元 (CMD),輸入:
# 查看 GPU 型號與顯示記憶體
nvidia-smi
你應該會看到類似結果:
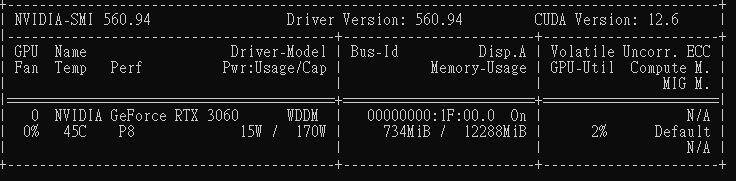
👉 代表我的 3060 有 12GB VRAM(12288MiB),足夠跑中小型 LLM 模型。
檢查重點:
systeminfo | findstr "Total Physical Memory"
記憶體建議:
# 檢查 C: 槽可用空間
fsutil volume diskfree C:
空間需求:
這邊提供模型大小參考,讀者可以藉此評估硬碟空間要有多少比較夠
由於 RTX 3060 具備 12GB VRAM,適合運行 7B 級別的模型。如果是繁體中文場景,推薦優先考慮 Qwen 系列,因為其在中文(含繁中)理解與生成上的效果通常優於 LLaMA、Mistral。
| 模型名稱 | 參數大小 | 量化大小 (GGUF / Ollama) | 需要 VRAM | 中文能力 | 適合場景 |
|---|---|---|---|---|---|
| Qwen 1.5 7B | 7B | 約 4GB (q4_0) / 6GB (q8_0) | 6~8GB | ✅ 強 | 中文 QA、對話、RAG |
| llama-3-taiwan-8b-instruct | 8B | 約 4GB (q4_0) / 6GB (q8_0) | 6~8GB | ✅ 強 | 台灣語境微調,強於在地語意理解 |
| Mistral 7B | 7B | 約 4GB (q4_0) / 6GB (q8_0) | 6~8GB | ❌ 偏弱 | 英文 QA、效能快 |
| LLaMA 2 7B | 7B | 約 4GB (q4_0) / 6GB (q8_0) | 6~8GB | ⚠️ 中等 | 英文任務佳,中文需要微調 |
| LLaMA 2 13B | 13B | 約 8GB (q4_0) / 12GB (q8_0) | 12GB+ | ⚠️ 中等 | 英文推理強,但中文弱,3060 效能吃緊 |
其實3060太小了,選擇真的不多,要推到14B基本上很容易就OOM,所以我們考量還是以:
下載適合繁體中文的 Qwen 模型:
# Qwen 7B (繁體中文推薦)
ollama pull cwchang/llama-3-taiwan-8b-instruct
這個步驟如果順利完成,我們就把~Taiwan-LLM 7B~ llama-3-taiwan-8b-instruct(筆者先前寫錯)給載到地端電腦了,後續我們就可以試著用這顆LLM來進行實作了!

 iThome鐵人賽
iThome鐵人賽