
在 核心篇 Day 5 (RAG),我們已經探討過 RAG(Retrieval-Augmented Generation) 的概念,並示範了最基礎的 naive 實作:
透過簡單的向量搜尋或網路檢索,讓模型能「開書考」,避免單靠記憶回答而產生幻覺。
不過,Naive RAG 雖然直觀,但很快會遇到瓶頸:
今天我們要運用 LangChain v1.0,把 RAG 化為一套 標準化、模組化的流程。
從 文件載入 → 分段 → 向量化 → 檢索 → 回答,每一步都能替換或調整,不需要推倒重來。
LangChain 把 RAG 拆解成模組化流程,根據應用需求,可以選擇不同架構:
| 架構類型 | 特點 | 適合情境 |
|---|---|---|
| 2-Step RAG | 固定「先檢索 → 再生成」,流程可控、延遲可預測 | FAQ、文件助理 |
| Agentic RAG | 模型自己決定「要不要檢索、檢索幾次」 | 研究助理、探索式問答 |
| Hybrid RAG | 兼具兩者,加入查詢增強、檢索驗證、答案檢查 | 需要品質控管的專業場景 |
換句話說,RAG 不再只是「拼湊技巧」,而是一條 可維護、可擴充的管線。
這是最經典的模式:
使用者問題 → 檢索文件 → 回答。
適合 FAQ、產品文件這類「檢索後就能直接作答」的場景。

圖:2-Step RAG 的固定流程。問題先經過檢索,找到相關文件,再交給 LLM 生成答案,最後回覆使用者。流程簡單、延遲可控。
pip install -q --pre -U langchain
pip install -q -U langchain-google-genai
pip install -q -U langchain-text-splitters langchain-community
import os
from langchain_core.documents import Document
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_google_genai import GoogleGenerativeAIEmbeddings
from langchain_community.vectorstores import InMemoryVectorStore
from langchain.chat_models import init_chat_model
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
# Step 1. 文件庫
docs = [
Document(page_content="美泉宮(Schönbrunn)通常上午 9 點開放。"),
Document(page_content="藝術史博物館適合雨天,館藏布勒哲爾的畫作《巴別塔》。"),
Document(page_content="納許市場適合午餐,靠近市中心,交通便利。"),
]
# Step 2. 分段
splits = RecursiveCharacterTextSplitter(chunk_size=300, chunk_overlap=50).split_documents(docs)
# Step 3. 向量化 + 建立索引
emb = GoogleGenerativeAIEmbeddings(model="models/gemini-embedding-001")
vstore = InMemoryVectorStore.from_documents(splits, emb)
# Step 4. Retriever
retriever = vstore.as_retriever(search_type="mmr", search_kwargs={"k": 2})
# Step 5. Prompt + Chain
RAG_PROMPT = ChatPromptTemplate.from_messages([
("system", "你是旅遊助理,請依據參考資料回答;若資料不足就說不知道。"),
("human", "問題:{question}\n\n參考資料:\n{context}")
])
llm = init_chat_model("google_genai:gemini-2.5-flash-lite", temperature=0, api_key=os.environ["GOOGLE_API_KEY"])
chain = RAG_PROMPT | llm | StrOutputParser()
# Helper:組合檢索結果
def format_ctx(docs):
return "\n".join(f"- {d.page_content}" for d in docs)
# 測試
query = "如果下午下雨,適合去哪裡?"
hits = retriever.invoke(query)
answer = chain.invoke({"question": query, "context": format_ctx(hits)})
print("檢索結果:\n", format_ctx(hits))
print("模型回答:", answer)

圖:2-Step RAG 的輸出範例。模型回答直接引用檢索結果(藝術史博物館 → 布勒哲爾《巴別塔》)來生成答案。這突顯了 RAG 的核心價值:答案不是憑空想像,而是有文件支持。
Document(metadata=…) 帶入 source/title/url,回答模板中把來源一併列出(例如「來源:Doc#1、Doc#2」)。k 可在召回率與延遲間取捨。另一種方式是 Agentic RAG:
讓模型自己判斷「要不要檢索」、「檢索什麼」、「檢索幾次」。
更靈活,適合需要探索的問題。
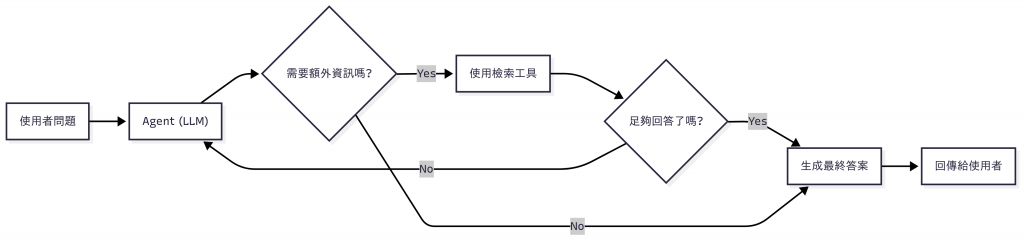
圖:Agentic RAG 的決策流程。Agent 會動態判斷是否需要外部知識,必要時使用檢索工具,直到足夠回答,再生成最終答案。
pip install -q --pre -U langchain
pip install -q -U langchain-google-genai
pip install -q -U langchain-text-splitters langchain-community
import os
from langchain.chat_models import init_chat_model
from langchain_core.tools import tool
from langchain.agents import create_agent
from langchain_core.documents import Document
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_google_genai import GoogleGenerativeAIEmbeddings
from langchain_community.vectorstores import InMemoryVectorStore
# ======================
# Step 1. 文件庫
docs = [
Document(page_content="美泉宮(Schönbrunn)通常上午 9 點開放。"),
Document(page_content="藝術史博物館適合雨天,館藏布勒哲爾的畫作《巴別塔》。"),
Document(page_content="納許市場適合午餐,靠近市中心,交通便利。"),
]
# Step 2. 分段
splits = RecursiveCharacterTextSplitter(
chunk_size=300, chunk_overlap=50
).split_documents(docs)
# Step 3. 向量化 + 建立索引
emb = GoogleGenerativeAIEmbeddings(model="models/gemini-embedding-001")
vstore = InMemoryVectorStore.from_documents(splits, emb)
# Step 4. Retriever
retriever = vstore.as_retriever(search_type="mmr", search_kwargs={"k": 2})
# ======================
# 定義 RAG 檢索工具
@tool
def rag_retrieve(query: str) -> str:
"""根據問題檢索維也納旅遊知識庫,返回相關內容"""
results = retriever.invoke(query)
if not results:
return "知識庫中沒有相關資訊"
return "\n".join([doc.page_content for doc in results])
# ======================
# 初始化 Gemini LLM
llm = init_chat_model("google_genai:gemini-2.5-flash", temperature=0, api_key=os.environ["GOOGLE_API_KEY"])
# 初始化 Agent(使用 RAG Tool)
agent = create_agent(
model=llm,
tools=[rag_retrieve],
system_prompt="你是一位維也納旅遊助理,請逐步推理,必要時使用工具檢索。"
)
# 測試
query = "幫我排一個雨天的半日遊行程,包含午餐和博物館"
response = agent.invoke({"messages": [{"role": "user", "content": query}]})
print("\n[模型最終回答]")
print(response["messages"][-1].content)
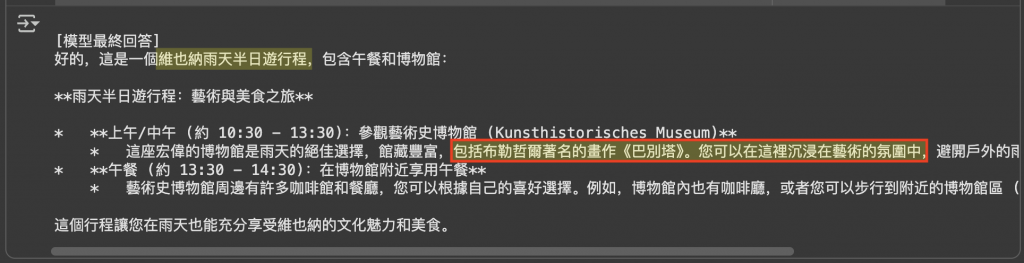
圖:Agentic RAG 的實際輸出結果。模型先判斷需要外部知識,再動態呼叫檢索工具(RAG Retriever),找到「藝術史博物館」等資訊,最後組合成完整的半日遊行程。這展現了 Agentic RAG 的特點:模型能在推理過程中靈活決定檢索時機與內容,讓答案更貼近需求。
rag_retrieve;若還不夠,會再次檢索並逐步充實上下文。rag_retrieve 回傳「片段 + doc_id/score/source」,並在最終回答中列出來源清單(或加上步驟摘要),提升可追溯性。這次的練習我們看到:
透過 LangChain v1.0,RAG 不再是零散技巧,而是一條 清晰、模組化的標準流程。
另外,眼尖的朋友可能會發現,在 Demo 2 (Agentic RAG) 裡,其實就是把 RAG 檢索包裝成工具(Tools),讓模型在需要時自行運用。
這裡其實已經用到了一些 Tools 的概念 了。接下來,我們就要更深入看看 —— LangChain 如何讓 Tool Use 更系統化,讓 Agent 不只會找答案,還能真的「動手做事」。

圖:布拉格克萊門特學院圖書館(Klementinum Library),被譽為世界上最美麗的圖書館之一。拱頂壁畫與滿牆古籍,展現知識的深度與厚度。這正好映照 RAG 的精神:讓模型不再閉門造車,而是能即時取用浩瀚知識,將推理建立在堅實的依據之上。每一次回答,都像在這座圖書館裡翻開正確的一頁書卷。(攝影:作者自攝)

 iThome鐵人賽
iThome鐵人賽